Apache Spark™ Clusters in Autopilot Mode
by Haogang Chen and Prakash Chockalingam
Apache Spark™ is a unified analytics engine that helps users use a single distributed computing framework for various use cases. With the advent of cloud computing, setting up your own platform using Apache Spark is relatively easy. There are also tools / services that cloud providers provide to make setup easier. However, the real hard problems where devops and platform engineers spend a lot of time in building and maintaining such a platform are:
- High availability: In the cloud, all the workloads are running on low-cost commodity machines. Being able to easily recover from failures is critical. Also, ensuring high availability of the clusters during software updates of the side car services in the cluster is also very essential.
- Optimizing for cost: Clusters need to be set up in such a way that they autoscale efficiently, they are terminated when not being used, and leverage spot market and use those instances in such a way that to lower costs but also not affect the workloads' stability when there are fluctuations in spot price.
- Optimizing for performance: Different workloads have different resource requirements and they need to run fast and efficiently utilizing all the resources.
- Fault isolation while handling user code: Clusters also need to be set up in such a way that different users do not bring down the clusters because of their user code.
Typically, solutions to these class of problems not only require an enormous amount of time in implementation, but they also introduce complexity in configuration and frequently require manual intervention to address them. This blog summarizes all the major capabilities Databricks provides you out of the box that put Databricks clusters in an "autopilot mode" so that devops need not worry about these platform problems anymore.
Automatic scaling of compute
Autoscaling compute is a basic capability that many big data platforms provide today. But most of these tools expect a static resource size allocated for a single job, which doesn't take advantage of the elasticity of the cloud. Resource schedulers like YARN then take care of "coarse-grained" autoscaling between different jobs, releasing resources back only after a Spark job finishes. This suffers from two problems:
- Estimating a good size for the job requires a lot of trial and error.
- Users typically over-provision the resources for the maximum load based on time of day, the day of the week or some special occasions like black Friday.
Databricks autoscaling is more dynamic and based on fine-grained Spark tasks that are queued on the Spark scheduler. This allows clusters to scale up and down more aggressively in response to load and improves the utilization of cluster resources automatically without the need for any complex setup from users. Databricks autoscaling helps you save up to 30% of the cloud costs based on your workloads. See the optimized autoscaling blog to learn more on how you save cloud costs by using Databricks autoscaling.
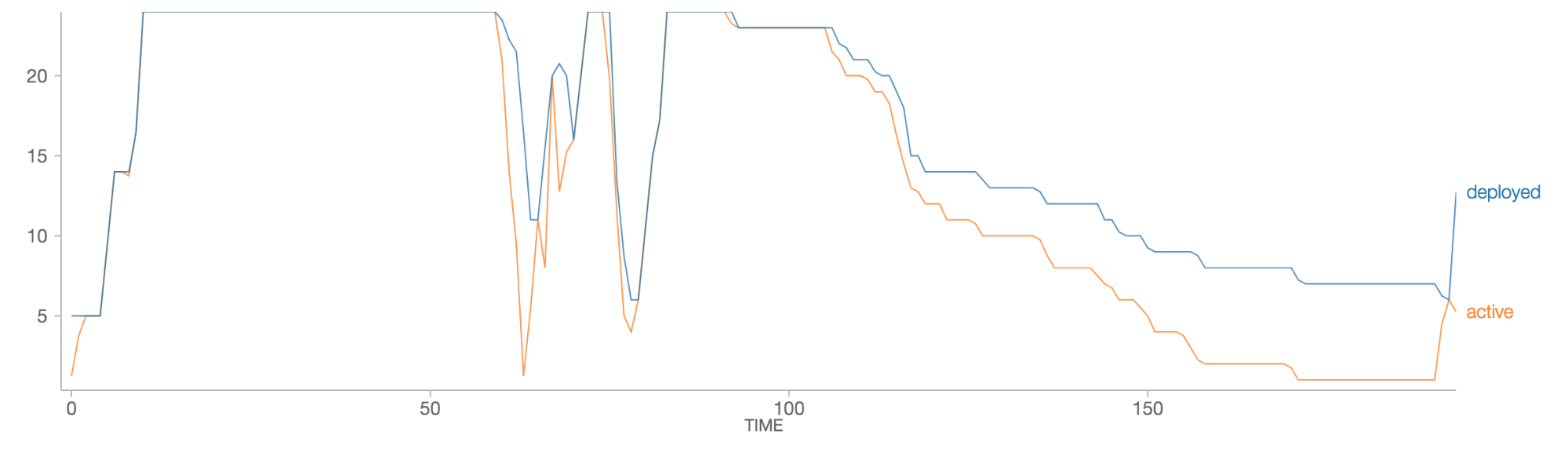
Automatic scaling of local storage
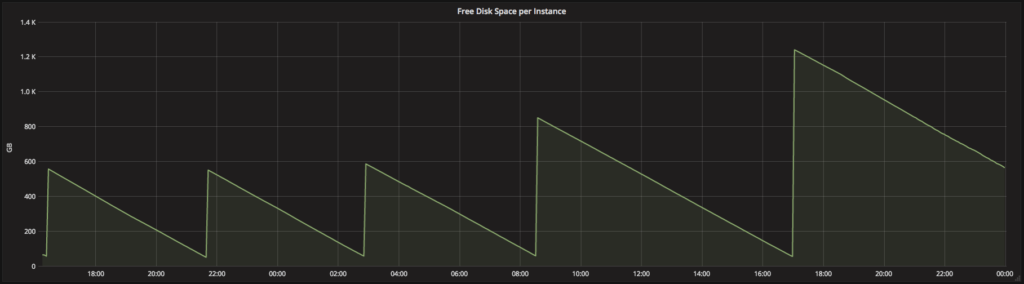
Big data workloads require access to disk space for a variety of operations, generally when intermediate results will not fit in memory. When the required disk space is not available, the jobs fail. To avoid job failures, data engineers and scientists typically waste time trying to estimate the necessary amount of disk via trial and error: allocate a fixed amount of local storage, run the job, and look at system metrics to see if the job is likely to run out of disk. This experimentation – which becomes especially complicated when multiple jobs are running on a single cluster – is expensive and distracts these professionals from their real goals.
Databricks clusters allows instance storage to transparently autoscale independently from compute resources so that data scientists and engineers can improve their productivity tremendously while moving their ETL jobs from development to production.
Learn more from the transparent autoscaling of instance storage blog on how we optimally autoscale the instance storage and its benefits.
Automatic termination
Databricks clusters can be set to terminate automatically after a set idle time to save on your cloud costs.

Automatic start
Databricks clusters also start automatically! Whenever a cluster receives a command from Jobs scheduler or JDBC/ODBC interface, the cluster automatically wakes up and then executes them. This is tremendously useful in the following scenarios:
- Scheduled production jobs: When you have a series of scheduled Databricks jobs on a single cluster and if there are idle periods when you want to shut down the cluster and save cost, you can now do that easily. When a scheduled job is submitted to a terminated cluster, it will automatically wake up the cluster and run the job.
- BI use cases: If you are connecting BI tools like Tableau to a Databricks cluster, before the availability of this feature, your data analysts need to login to Databricks and start the cluster. Now they no longer need to login to Databricks. They can just run commands from Tableau. If the cluster is in terminated state, it will automatically start. This will allow platform teams to roll out a serverless big data platform for internal data analysts to slice and dice big data without having to worry about any concept of clusters.
- Warm up cluster: You have a situation when you step into the office tomorrow at 9am, you want to have a cluster up and running with certain analysis done and certain data cached so that you can be more productive and continue your work as soon as you step into the office. You can now schedule a job at early in the morning that would automatically wake up the cluster and run the analysis and have everything ready by the time you step into the office. You no longer need to write custom scripts that uses Databricks REST APIs for this purpose.
Together with auto-termination, auto-start is a powerful feature that allows users to just set the cluster configuration once and then let Databricks take care of automatically starting and terminating clusters based on usage.
Automatic recovery and resilience to spot price fluctuations
In a cloud environment, computing resources can fail for various reasons:
- Cost-efficient nodes such as spot instances or low priority VMs may be reclaimed by the cloud provider at anytime
- A node can get stuck in an unresponsive state due to software bugs
- Transient network failures can also cause instance malfunctioning
Detecting and recovering from various failures is a key challenge in a distributed computing environment. With built-in support for automatic recovery, Databricks ensures that the Spark workloads running on its clusters are resilient to such failures. The Databricks cluster manager periodically checks the health of all nodes in a Spark cluster. Depending on the nature of the failure, it smartly recovers the cluster with the minimal cost. For example, when an executor crashes or gets stuck, Databricks simply restarts the process to avoid strangling the entire workload; when an underlying instance is fully unresponsive, Databricks acquires a new instance from the cloud provider to replace the malfunctioning one.
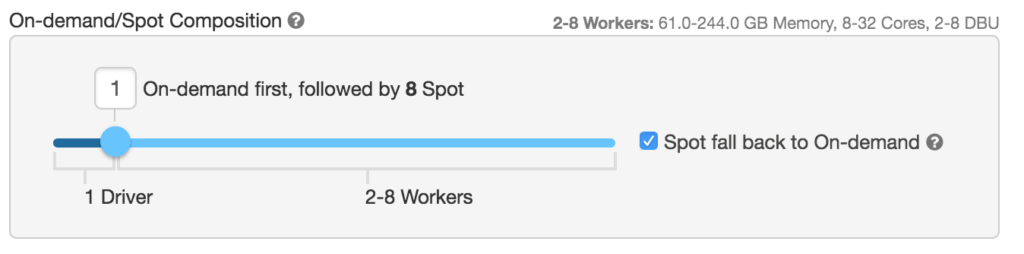
Automatic recovery also helps Databricks clusters gain the upside of high availability while maintaining low cost. Take AWS as an example, customers can configure their clusters to use spot instances with fallback to on-demand instances. With this setting, Databricks will first try to use spot instances at user-specified bidding ratio at a much lower price. When that fails, it automatically switches to on-demand instances so that your workloads run smoothly even during spot price fluctuation.
Automatic monitoring instrumentation
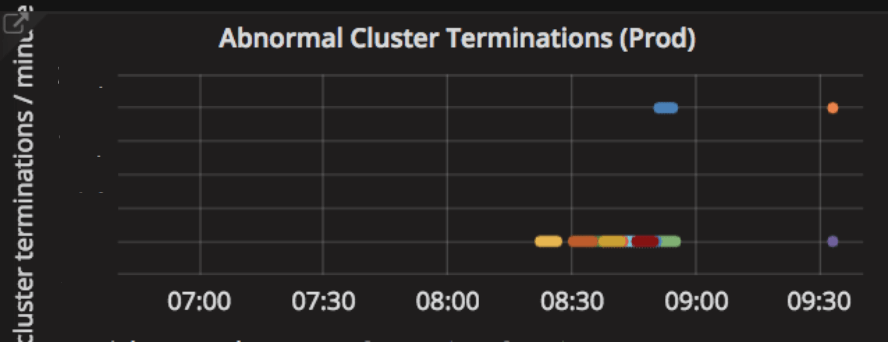
Databricks services stream hundreds of metrics to our internal monitoring system every minute. Those metrics include cluster launch duration, cluster and node terminations, worker disk usage hikes, network connectivity issues, and Spark configuration errors. The monitoring system automatically categorizes the metrics and visualizes them on dashboards. The metrics help Databricks determine and guard the health of clusters on behalf of our customers. In the case where failure recovery is impossible, such as the Spark master node going down or prolonged cloud-provider outage, Databricks collects diagnosis information and reports the cluster termination reason to customers for better visibility.
Databricks also get alerts for spikes of correlated incidents. For instance, when the rate of abnormal cluster terminations exceeds a threshold, the monitoring system automatically sends alerts to our first responders so that they can drill down the root cause. Given the large volume of instances that Databricks manages for our customers, sometimes Databricks even detects large-scale cloud outages before the cloud provider reports them. Once the root cause is confirmed, Databricks proactively sets up a banner to affected customers to inform them about the outage and the root cause.
Automatic software updates
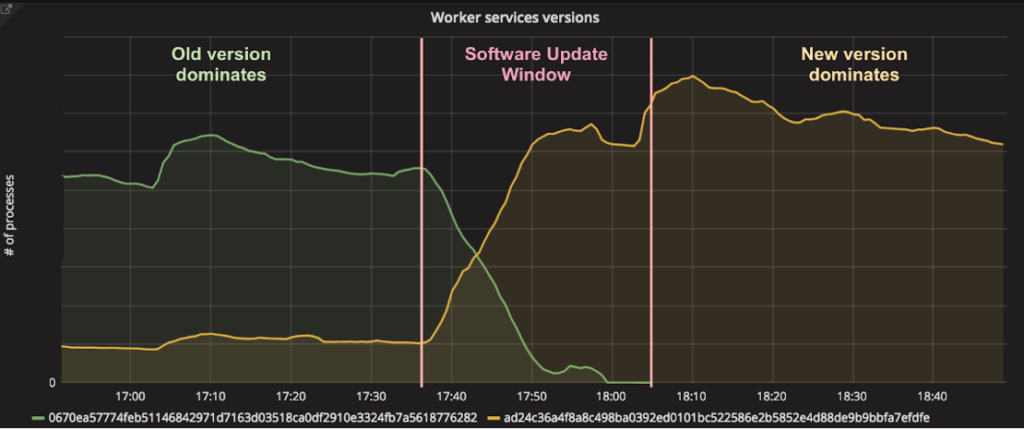
As a SaaS platform, Databricks releases new features and bug fixes to our customers in a regular cadence. Many updates affect side-car services running in the cluster along with Spark workers. A key challenge is how to deploy updates on tens of thousands of worker instances without interrupting or interfering with the customers' running workloads.
Databricks update manager monitors the version of side-car services running on existing Spark workers, and gradually brings them up-to-date with the latest release. The updates are carefully throttled so that they do not cause performance degradation on Spark workloads. New clusters are always launched with the latest software. In this way, updates are usually deployed to all Spark clusters transparently within an hour of release while incurring zero downtime on customers' production workloads.
Automatic preemption
When multiple users are sharing a cluster, it is very common to have a single job from a user monopolize all the cluster resources, thereby slowing all other jobs on the cluster. Apache Spark's fair scheduler pool can help address such issues for a small number of users with similar workloads. As the number of users on a cluster increases, however, it becomes more and more likely that a large Spark job will monopolize all the cluster resources. The problem can be aggravated when multiple data personas are running different types of workloads on the same cluster. For example, a data engineer running a large ETL job will often prevent a data analyst from running short, interactive queries.
To combat such problems, Databricks clusters proactively preempt Spark tasks from over-committed users to ensure all users get their fair share of cluster time. This gives each user a highly interactive experience while still minimizing overall resource costs. See the documentation on task preemption to know more.
Automatic killing of rogue jobs
In a multi-user scenario, sometimes it is also possible that a user's job is going rogue causing it to consume all the resources. Even with task preemption, the job could still saturate cluster resources and stall everyone's job. One example would be a user job that does an unintentional cross join of two large datasets resulting in a large amount of intermediate data. In such cases, Databricks clusters has a simple process, Query Watchdog, that periodically checks if the job is creating too many output rows for the number of input rows at a task level and kills any rogue job that produces too many output rows.
Automatic caching
During interactive analysis, users typically run ad-hoc queries / jobs that repeatedly read the same set of data. In such cases, caching repeatedly used data is very useful. Typically, users need to worry about which data to cache, how to evict unused data, how to load balance the cached data and handle updates to cached data.
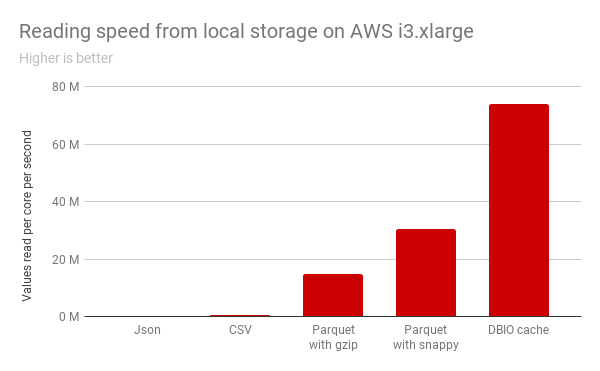
In Databricks, if you choose certain instance types with SSDs, Databricks transparently transcodes the data into an on-disk caching format and caches it in the instance's SSD whenever a remote file is accessed. We also take care of evicting long unused data and load balancing the cached data across all nodes in the cluster. The cache also automatically detects when a file is added or deleted in the original source location and presents the up-to-date state of the data. Read the blog about DBIO Cache to know more about our caching feature.
Conclusion
We walked through a series of "automatic" features in Databricks clusters that lets users not worry about the platform anymore and just focus on the data. These features also illustrate how our unified analytics platform reduces time to value for the big data projects.
If you are interested in trying out all these "automatic" features, sign up for a free trial on AWS here. If you are on Azure, you can login to your Azure subscription and start using Databricks.
If you are passionate about building and solving these problems for thousands of enterprise users, we are hiring!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.