New Features in MLflow v0.6.0
by Aaron Davidson and Jules Damji
Today, we’re excited to announce MLflow v0.6.0, released early in the week with new features. Now available on PyPI and Maven, the docs are updated. You can install the recent release with pip install mlflow as described in the MLflow quickstart guide.

MLflow v0.6.0 introduces a number of major features:
- A Java client API, available on Maven
- Support for saving and serving Spark MLlib models as MLeap for low-latency serving
- Support for tagging runs with metadata, during and after the run completion
- Support for deleting (and restoring deleted) experiments
In this post, we’ll describe new features, enhancements, and bug fixes in this release. In particular, we will focus on two features: A new Java MLflow client API and Spark MLlib and MLeap model integration.
Java Client API
To give developers a choice of programming languages, we have included a Java client tracking API, similar in functionality to Python client tracking API. Both offer CRUD interface to MLflow experiments and runs. This Java client is available on Maven.
Through the primary Java class constructor MlflowClient() and its instance methods, you create, list, delete, log or access runs and its artifacts. By default, it connects to the tracking server set in the environment variable MLFLOW_TRACKING_URI, unless instantiated explicitly with MlflowClient(tracking_server_ui) constructor.
If you have used the new MLflow Python tracking and experiment API, introduced in MLflow v0.5.2, it’s no different in functionality. As always, some code snippet will illustrate its usage. A full example, though, can be found in the sample directory of the Java client source code: QuickStartDriver.java
Spark MLlib and MLeap Model Integration
True to the MLflow’s design goal of “open platform," supporting popular ML libraries and model flavors, we have added yet another model flavor: mlflow.mleap. Spark MLlib models can be optionally saved in the MLeap format. This new MLeap format allows deploying Spark MLlib models for low-latency production serving.
For real-time serving, the MLeap framework is far more performant than Spark MLlib for a number of reasons. First, it employs a lighter weight, performant DataFrame representation. Second, unlike the Spark MLlib Pipeline model, it does not require a SparkContext while evaluating MLlib Pipelines in Scala. And, finally, it has serialization and deserialization mechanisms to convert PySpark Pipeline models into Scala objects.
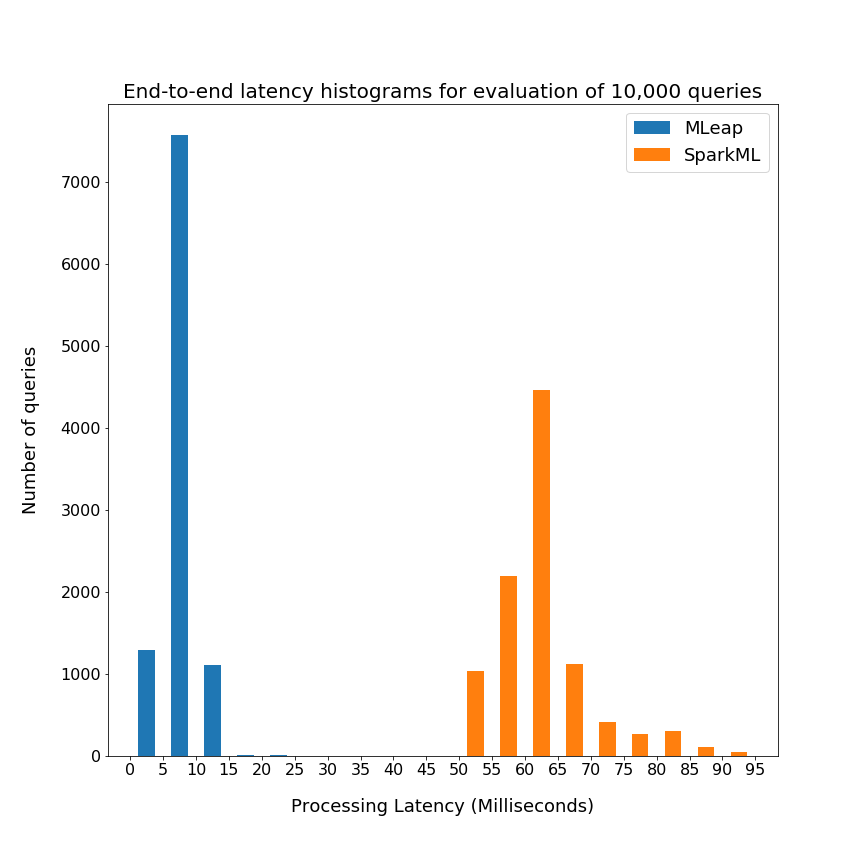
From the above graph, you can see that MLeap can serve predictions in the single-digit millisecond range, whereas Spark MLlib reaches in the 100-millisecond range.
Saving Spark MLib Models in MLeap Flavor
For this functionality, we have extended the mlflow.spark API’s save_model(...) to optionally save a Spark MLib model in MLeap format too, giving you the option to deploy a performant model for real-time serving. An example will illustrate how to save this model in both formats.
Let’s create a simple Spark MLlib model, log model, some parameters, and persist it in both a Spark MLlib and MLeap model format. An additional argument to mlflow.spark.save_model(...) will persist in both formats: Spark MLlib and MLeap.
Other Features and Bug Fixes
In addition to these features, other items, bugs and documentation fixes are included in this release. Some items worthy of note are:
- [API] Support for tagging runs with metadata, during and after the run completion
- [API] Experiments can now be deleted and restored via REST API, Python Tracking API, and MLflow CLI (#340, #344, #367, @mparkhe)
- [API] Added list_artifacts and download_artifacts to MlflowService to interact with a run's artifactory (#350, @andrewmchen)
- [API] Added get_experiment_by_name to Python Tracking API, and equivalent to Java API (#373, @vfdev-5)
- [API/Python] Version is now exposed via mlflow.version.
- [API/CLI] Added mlflow artifacts CLI to list, download, and upload to run artifact repositories (#391, @aarondav)
*[API/CLI] Added mlflow artifacts CLI to list, download, and upload to run artifact repositories (#391, @aarondav) - [API] Added get_experiment_by_name to Python Tracking API, and equivalent to Java API (#373, @vfdev-5)
- [Serving/SageMaker] SageMaker serving takes an AWS region argument (#366, @dbczumar)
- [UI] Added icons to source names in MLflow Experiments UI (#381, @andrewmchen)
- [Docs] Added comprehensive example of doing a multi-step workflow, chaining MLflow runs together and reusing results (#338, @aarondav)
- [Docs] Added comprehensive example of doing hyperparameter tuning (#368, @tomasatdatabricks)
- [Docs] Added code examples to mlflow.keras API (#341, @dmatrix)
- [Docs] Significant improvements to Python API documentation (#454, @stbof)
- [Docs] Examples folder refactored to improve readability. The examples now reside in examples/ instead of example/, too (#399, @mparkhe)
The full list of changes and contributions from the community can be found in the 0.6.0 Changelog. We welcome more input on mlflow-users@googlegroups.com or by filing issues or submitting patches on GitHub. For real-time questions about MLflow, we have a Slack channel for MLflow as well as you can follow @MLflow on Twitter.
Read More
For an overview of what we’re working on next, take a look at the roadmap slides in our presentation.
Credits
MLflow 0.6.0 includes patches, bug fixes, and doc changes from from Aaron Davidson, Adrian Zhuang, Alex Adamson, Andrew Chen, Corey Zumar, Hamroune Zahir, Joy Gioa, Jules Damji, Krishna Sangeeth, Matei Zaharia, Siddharth Murching, Shenggan, Stephanie Bodoff, Tomas Nykodym, Toon Baeyens, and VFDev.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.