How Databricks IAM Credential Passthrough Solves Common Data Authorization Problems
by Greg Owen and Silvio Fiorito
In our first blog post, we introduced Databricks IAM Credential Passthrough as a secure, convenient way for customers to manage access to their data. In this post, we'll take a closer look at how passthrough compares to other Identity and Access Management (IAM) systems. If you’re not familiar with passthrough, we suggest reading the first post before you continue with this one.
Properties of a good cloud IAM system
When our customers choose a system to manage how their users access cloud data, they look for the following common set of properties:
- Security: Users should be able to access only the data they’re authorized to access.
- Attribution: An admin should be able to trace data accesses to the users who initiated them and audit historical accesses. This auditing should be trustworthy: users should not be able to remove or modify the audit logs.
- Ease of administration: Larger organizations typically have few personnel administering IAM systems with hundreds of non-admin users, such as data scientists, analysts, and data engineers. The non-admin users may have a few dozen entitlements (e.g., "access PII user data", "write to log pipeline tables", "read sales aggregate tables").
- Efficiency: The system should be as cost-efficient as possible. Resources should be shared among users and not sit idle.
In this blog post, we'll explore a few common cloud IAM systems and how well they achieve these properties. We'll finish with an exploration of Databricks IAM Credential Passthrough and how it achieves security and attribution without sacrificing ease of administration or efficiency.
Sub-optimal system 1: One EC2 instance per entitlement
Our AWS customers typically represent entitlements using IAM Instance Profiles: they'll have one instance profile to access all data from a particular customer, another to read a certain class of data, and so on. A user can get entitlement to some data by running code on an AWS EC2 instance that has the associated instance profile attached. Because each AWS EC2 instance can only be given a single instance profile, one of the most common solutions we see is for customers to launch a separate EC2 instance for each entitlement in their systems. The admin team is then responsible for making sure that users have access only to clusters with the appropriate entitlements.
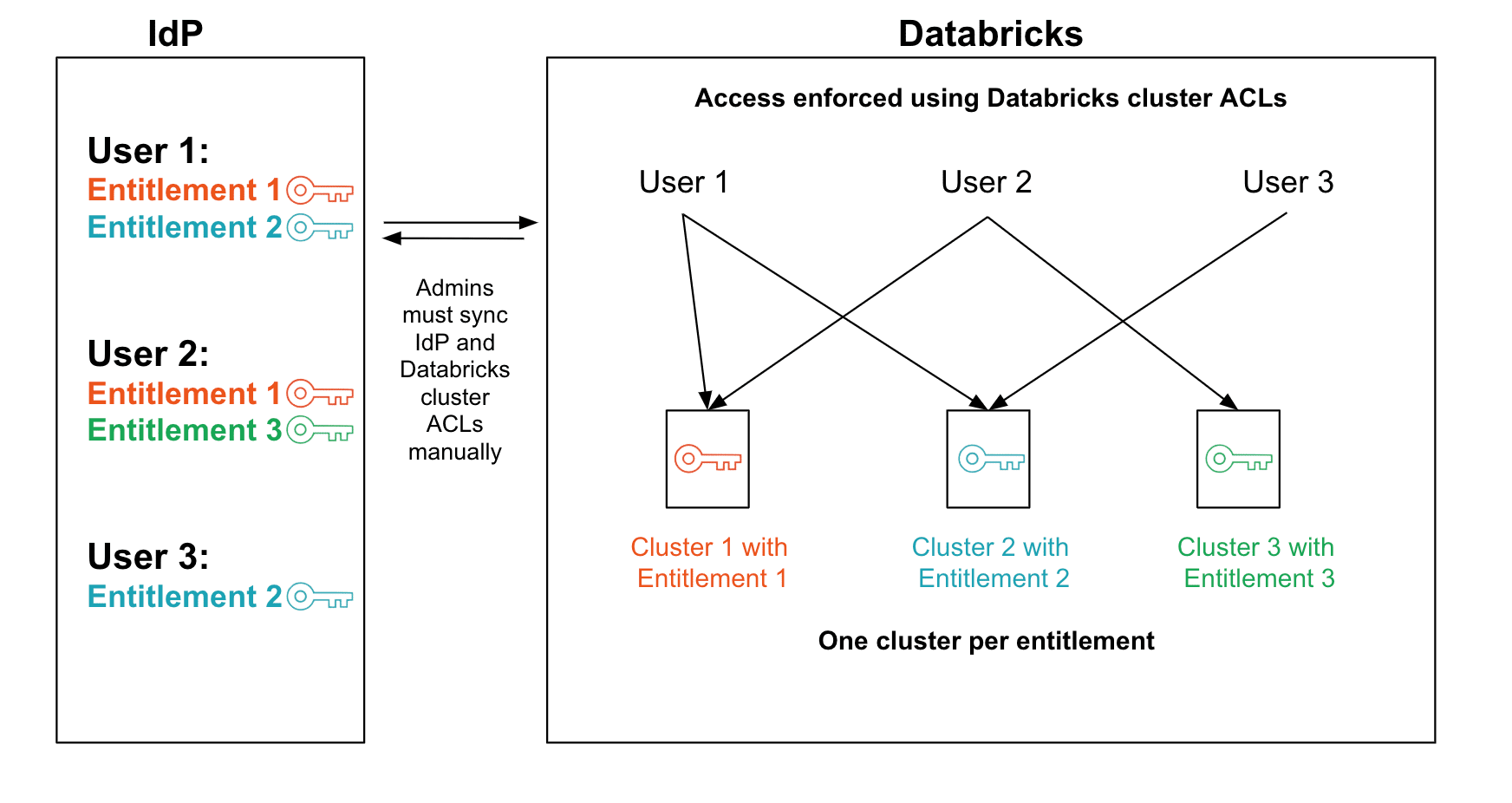
Sub-Optimal System 1: One EC2 instance per entitlementSecurity - The main benefit of this system is that it is straightforwardly secure. As long as the admin team maps users to EC2 instances correctly, each user has access to the correct set of entitlements.
Attribution - This system does not allow attribution to users. Because all users on a given EC2 instance share the same Instance Profile, cloud-native audit logs such as AWS CloudTrail can attribute accesses only to the instance, not to the user running code on the instance.
Ease of administration - This system is easy to administer provided the number of users and entitlements remain small. However, administration becomes increasingly difficult as the organization scales: admins need to ensure that each user accesses only the EC2 instances with the correct Instance Profiles, which may require manual management if the Instance Profiles don't map cleanly to policies in the admin's identity management system (such as LDAP or Active Directory).
Efficiency - This system requires a separate EC2 instance for each entitlement, which quickly becomes expensive as the organization's permission model becomes more complex. If there are only a few users with a particular entitlement, that EC2 instance will either sit idle most of the day (increasing cost) or have to be stopped and started according to the work schedule of its users (increasing administrative overhead and slowing down users). Because Apache Spark™ distributes work across a cluster of instances that all require the same Instance Profile, the cost of an idle cluster can become quite large.
Sub-optimal system 2: Users with different permission levels sharing an EC2 instance
Because of the drawbacks of the "one instance per entitlement" system, many of our customers decide to share EC2 instances among multiple users with different entitlements. These organizations let each user encode their particular credentials (in the form of usernames and passwords or AWS Access Keys and Secret Keys rather than Instance Profiles) in local configurations on the instance. The admin team assigns each user their credentials and trusts the user to manage them securely.
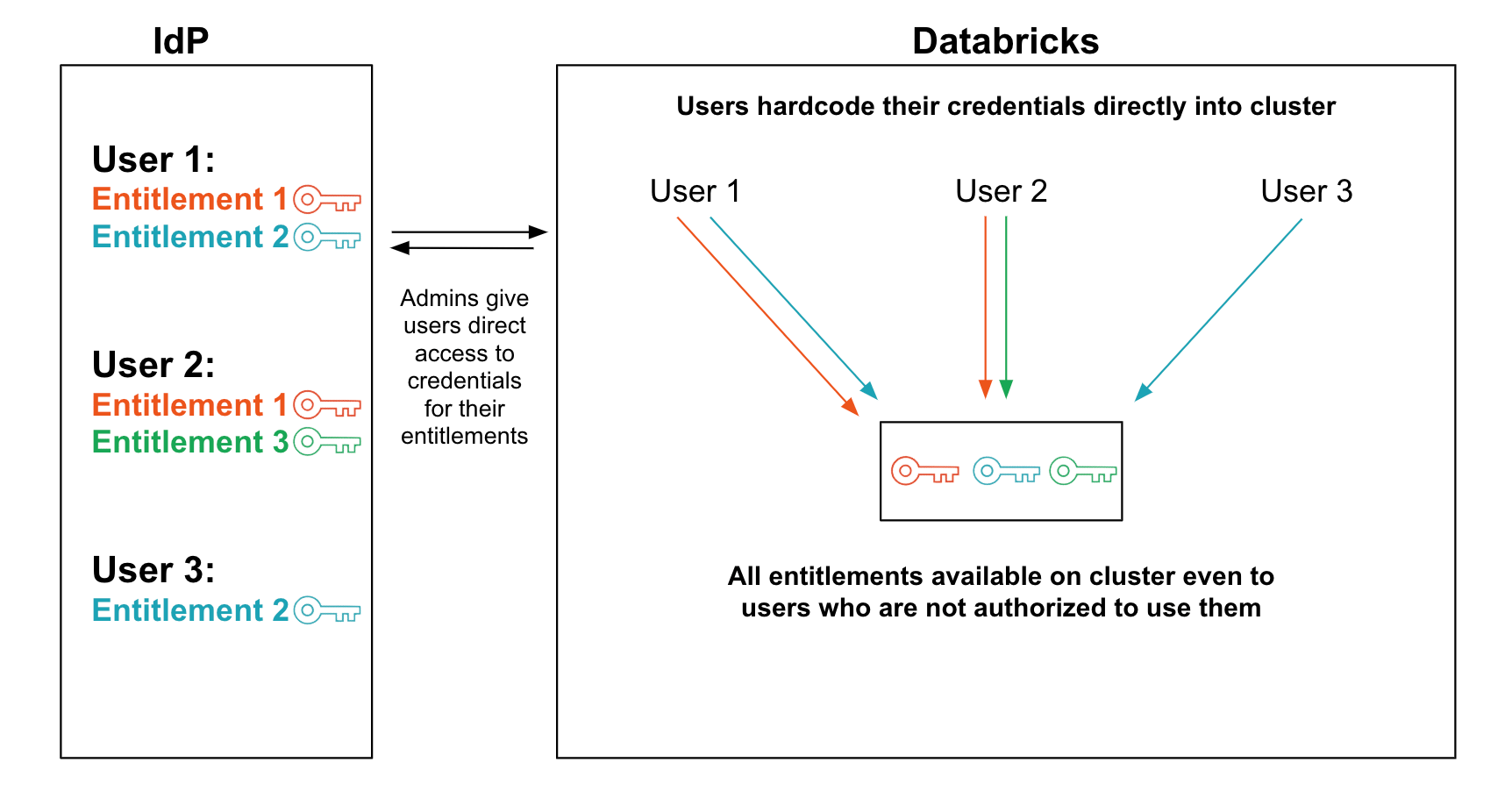
Security - The drawback of this system is that it is usually not secure. Besides the obvious problems of users sharing their credentials with each other or accidentally exposing their credentials via some global configuration, there are several more subtle security vulnerabilities hiding in this system.
- Users can use the instance's shared filesystem to access data that other users have collected to the instance's local disk. AWS IAM can't protect data once it's on a local disk.
- Users can inspect the in-memory state of their data processing tools to extract another user's credentials. For example, a user could dump the memory of another user's process or use Java reflection (for JVM-based tools) to crawl the JVM's object graph and extract the object containing another user's credentials.
- Users can trick their data-processing tools into performing data access using another user's credentials. Most data-processing tools (including Spark) are not hardened against mutually-untrusted users sharing the same engine. Even if a user cannot read another user's credentials directly, they can often use their tools to impersonate that other user.
Attribution - In theory, this system offers per-user attribution: since each user uses their own credentials, cloud access logs should be able to attribute each access to a user. In practice, however, that attribution can't be trusted because of the security holes described above. You can be sure that a given user's credentials were used to access data, but you can't confirm which user was using those credentials.
Ease of administration - At first glance, this system is easy to administer: just give users access to the credentials they need and they’ll do the job of getting those credentials onto the instances they're using. Eventually, though, we find that most admins get tired of having to rotate credentials that some user accidentally exposed to everyone on their EC2 instance.
Efficiency - The main benefit of this system is that it is cost-efficient, albeit at the cost of security. Users can share exactly the number of instances they need and the instances see good utilization.
Our system: Databricks IAM Credential Passthrough
Databricks IAM Credential Passthrough allows users with different entitlements to share a single EC2 instance without the risk of exposing their credentials to other users. This combines the security of System 1 with the efficiency of System 2, and achieves better attribution and easier administration than either system. For an overview of how Passthrough works, see our first blog post.
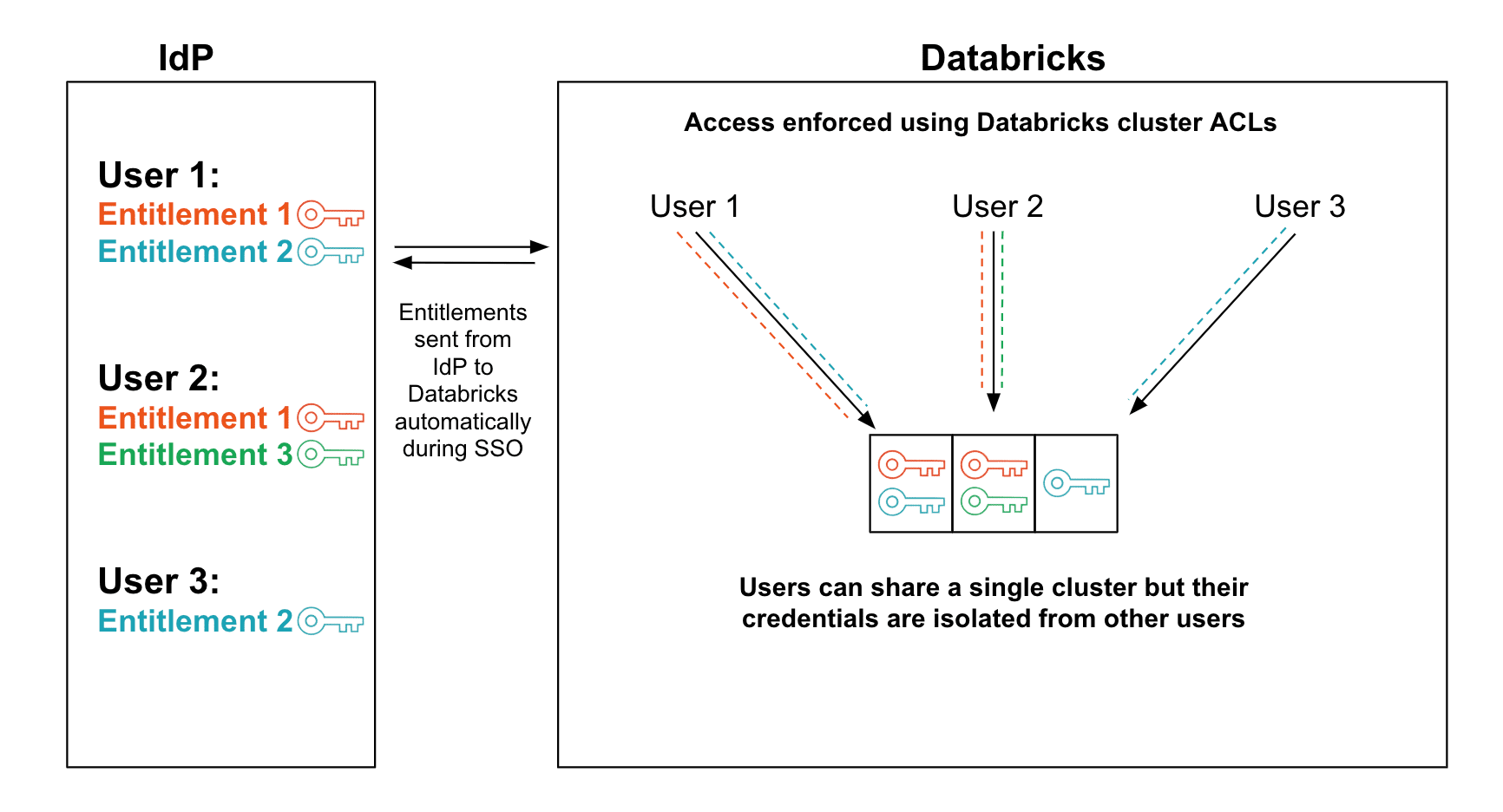
Security - Any system that shares a single execution engine between users with different entitlements must defend against a long tail of subtle security holes. By integrating closely with the internals of Apache SparkTM, Passthrough avoids these common pitfalls:
- It locks down the instance's local filesystem to prevent users from accessing data downloaded by other users and to secure data as it is transferred between user-defined code and Spark internal code.
- It runs code from different users in separate, low-privilege processes that can only run JVM commands from a predetermined whitelist. This protects against reflection-based attacks and other unsafe APIs.
- It guarantees that a user's credentials are only present on the cluster while that user is executing a Spark task. Furthermore, it purges user credentials from Spark threads after their tasks complete or are preempted, so a malicious user cannot use Spark to acquire indirect access to another user's credentials.
Attribution - Because Passthrough guarantees that each user only runs commands with their own credentials, cloud-native audit logs such as AWS CloudTrail will work out of the box.
Ease of administration - Passthrough integrates with our existing SAML-based Single Sign-On feature (link), so admins can assign roles to users within their existing SAML Identity Provider. Permissions can be granted or revoked based on groups, so the extra overhead of using Passthrough is minimal.
Efficiency - Because multiple users can share a single cluster, Passthrough is cost-efficient, especially when combined with our autoscaling high-concurrency clusters.
Summary Table
| Solution | Security | Attribution | Ease of Administration | Efficiency |
| One instance per entitlement | Yes | No - can only attribute to an instance | No - have to maintain user → instance map manually | No - instances (or clusters) will often sit idle |
| Shared instances | No - users can access each others' credentials | No - users can impersonate each other | No - have to rotate user credentials as they leak | Yes |
| Passthrough | Yes | Yes | Yes | Yes |
Conclusion
Databricks IAM Credential Passthrough allows admin users to manage access to their cloud data with a system that is secure, attributable, easy to administer, and cost-effective. Because it is deeply integrated with Apache Spark, Passthrough allows users with different credentials to share the same EC2 instances (reducing cost) without sharing their credentials (guaranteeing security and attribution). IAM Credential Passthrough is in private preview right now; please contact your Databricks representative to find out more.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.