Solving the Challenge of Big Data Cloud Migration with WANdisco, Databricks and Delta Lake
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
This is a guest blog from Paul Scott-Murphy, VP of Product Management, Big Data / Cloud at WANdisco.
Migrating from Hadoop on-premises to the cloud has been a common theme in recent Databricks blog posts and conference sessions. They’ve identified key considerations, highlighted partnerships and described solutions for moving and streaming data to the cloud with governance and other controls, and compared the runtime environments offered between Hadoop and Databricks to highlight the benefits of the Databricks Unified Data Analytics Platform.
Challenges for Hadoop users when moving to the cloud
WANdisco has partnered with Databricks to solve many of the challenges for large-scale Hadoop migrations. A particular challenge for organizations that have adopted Hadoop at scale is the traditional problem of data gravity. Because their applications assume ready, local, fast access to an on-premises data lake built on HDFS, building applications away from that data becomes difficult, because it requires building additional workflows to manually copy or access data from the on-premises Hadoop data lake.
This problem is exacerbated by an order of magnitude if those on-premises data sets continue to change, because the workflows to move data between environments add a layer of complexity, and don’t handle changing data easily.
While the cloud brings efficiencies for data lakes there remains concerns about the reliability and the consistency of the data. Data Lakes typically have multiple data pipelines reading and writing data concurrently, and data engineers have to go through a tedious process to ensure data integrity, due to the lack of transactions.
Hadoop migration with Databricks and WANdisco
The Databricks and WANdisco partnership solves these challenges, by providing full read and write access to changing data lakes at scale during migration between on-premises systems and Databricks in the cloud. This solution is called LiveAnalytics, and it takes advantage of WANdisco’s platform to migrate and replicate the largest Hadoop datasets to Databricks and Delta Lake. WANdisco makes it possible to migrate data at scale, even while those data sets continue to be modified, using a novel distributed coordination engine to maintain data consistency between Hive data and Delta Lake tables.
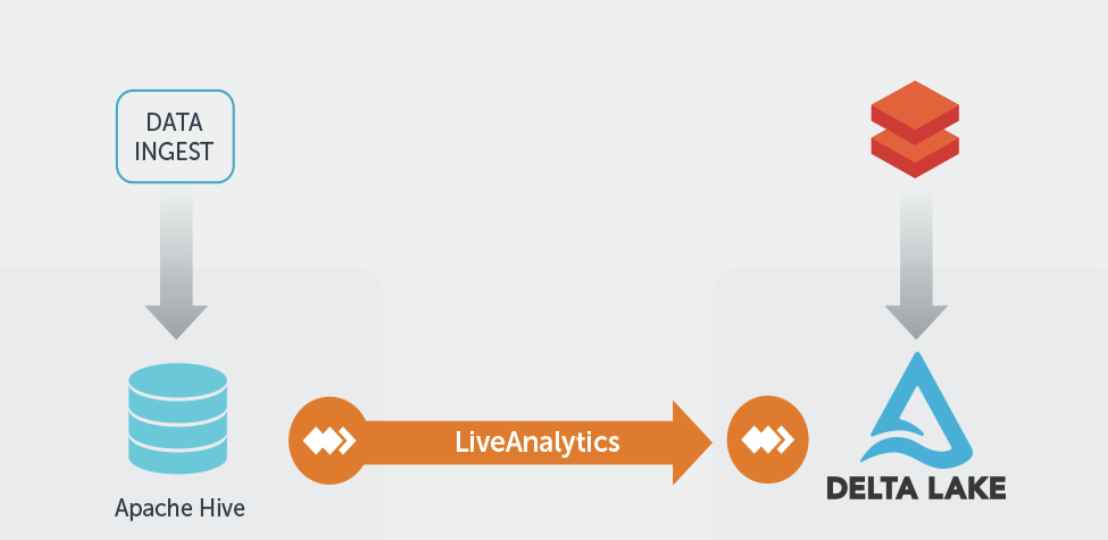
WANdisco’s architecture and consensus-based approach is the key to this capability. It allows migration without disruption, application downtime or data loss, and opens up the benefits of applying Databricks to the largest of data lakes that were previously difficult to bring to the cloud.
Because WANdisco LiveAnalytics provides direct support of Delta Lake and Databricks along with common Hadoop platforms, it provides a compelling solution to bringing your on-premises Hadoop data to Databricks without impacting your ability to continue to use Hadoop while migration is in process.
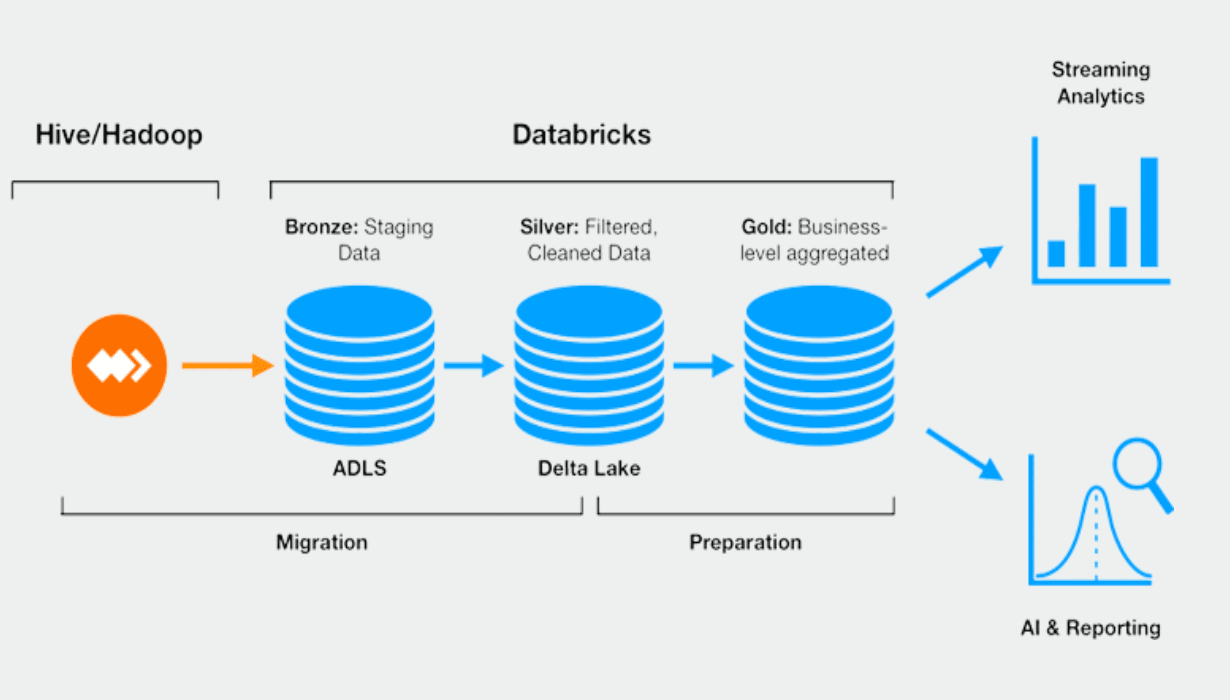
You can take advantage of WANdisco’s technology today to help bring your Hadoop data lake to Databricks, with native support of common Hadoop platforms on-premises and for Databricks and Delta Lake on Azure or AWS.
Related Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.