Automate and Fast-track Data Lake and Cloud ETL with Databricks and StreamSets
by Hiral Jasani and Nauman Fakhar
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
Data lake ingestion is a critical component of a modern data infrastructure. But enterprises often run into challenges when they have to use this data for analytics and machine learning workloads. Consolidating high volumes of data from disparate sources into a data lake is difficult, even more so if it is from both batch and streaming sources. Big data is often unorganized and inconsistent with discrepancy in formats and data types. This makes it difficult to update data in the data lake. With low query speeds and lack of real-time access, the result is a development environment that can’t keep pace. Additionally, it leads to a lack of data quality and poor overall performance of the data lake further delaying deployments in production.
Bringing Speed and Agility with Smart ETL Ingest
What can organizations do to make their data lakes more performant and useful? The challenges discussed above can slow down an organization’s cloud analytics/data science plans significantly - especially if they are limited on data engineering and data science professionals. Data engineers waste their time on ad-hoc, proof of concept sandboxes while struggling to transition data into production. In turn, data scientists lack the confidence to use that data for analytics and machine learning applications.
Databricks and StreamSets have partnered to accelerate value to cloud analytics by automating ingest and data transformation tasks. The joint solution brings rapid pipeline design and testing to cloud data processing. StreamSets Data Collector and Transformer provides a drag-and-drop interface to design, manage and test data pipelines for cloud data processing.
Together, this partnership brings the power of Databricks and Delta Lake to a wider audience. Delta Lake makes it possible to unify batch and streaming data from disparate sources and analyze it at data warehouse speeds. It supports transactional insertions, deletions, upserts and queries. It provides ACID compliance, which means that any writes are always complete and failed jobs are fully backed out.
The integration provides several key benefits:
- Faster migration to cloud with less overhead on data engineering resources
- Easily bring data from multiple disparate sources using a drag-and drop interface
- Better management of data quality and performance for cloud data lakes with Delta Lake
- Change Data Capture (CDC) capability from several data sources in to Delta Lake
- Decreased risk of disruptions for Hadoop migrations with quicker time-to-value on on-prem to cloud initiatives
- Continuous monitoring of data pipelines to lower support cost and optimize ETL pipelines
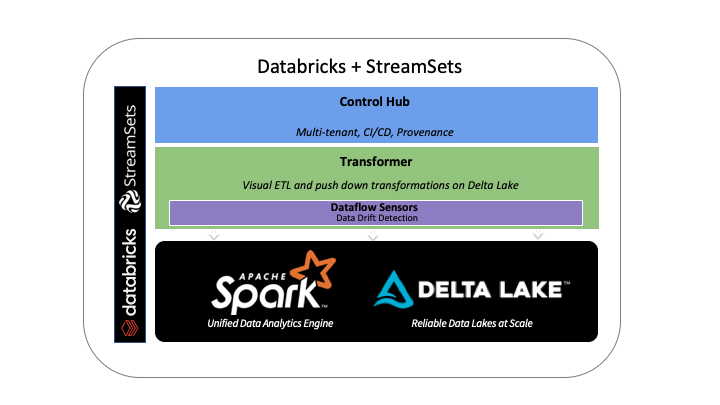
Databricks Architecture with StreamSets
Using Visual Pipeline Development to Ingest Data into Delta Lake
Data teams spend a large amount of time building ETL jobs in their current data architectures, and this often tends to be complex and code-intensive. For example, organizations may want to know real-time usage in production as well as run historical reports to analyze usage trends over time without being slowed down by complex ETL processing. Overcoming messy data issues, corrupt data and other challenges requires validation and reprocessing that can take hours if not days. The query performance of streaming data may slow things down further.
The integration of Databricks and StreamSets solves this by allowing users to design, test and monitor batch and streaming ETL pipelines without the need for coding or specialized skills. The drag-and-drop interface with StreamSets makes it easy to ingest data from multiple sources into Delta Lake. With its execution engine - StreamSets Transformer, users can create data processing pipelines that execute on Apache Spark. Transformer generates native Spark applications that execute on a Databricks cluster.
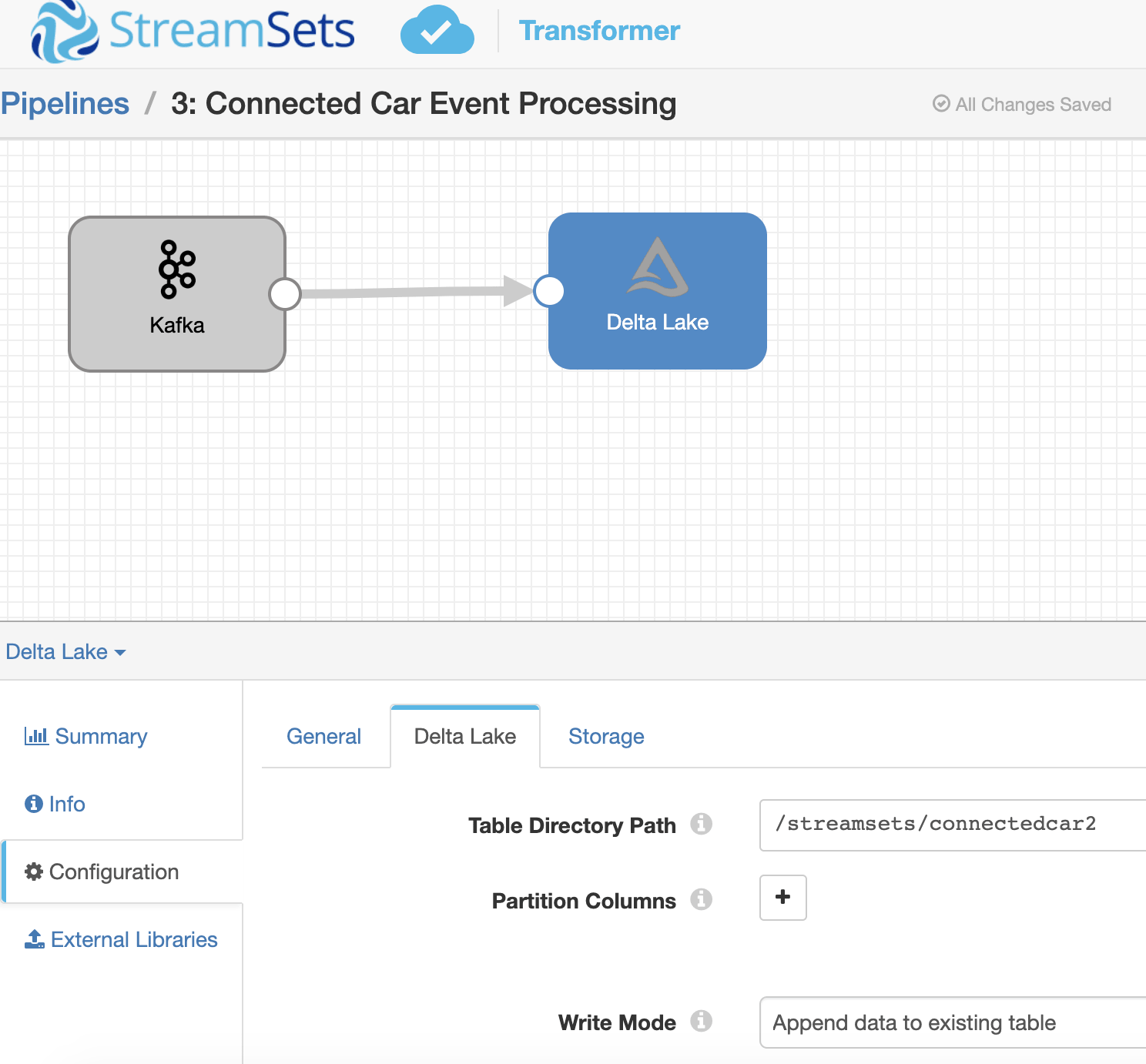
Below is an example of how simple it is to create a Delta ingest pipeline with Streamsets where Kafka is the source and Delta is the destination.
There is a native Delta Lake destination in Transformer, which is very easy to configure. You simply specify location of Delta dataset, which could be a DBFS mount, and data from Kafka (or any other source supported by Transformer) flows into the destination Delta table.
Transformer can also perform transformations on Delta tables, which are expressed visually but convert to Spark code at runtime and pushed down as Spark jobs into Databricks clusters, so joint customers can enjoy the scale, reliability and agility of a fully managed data engineering and AI platform with the click of a few buttons.
Below is an example of a transformation pipeline where both the source and destination are Delta Lake tables, while the middle steps are transformations being done on the source table.

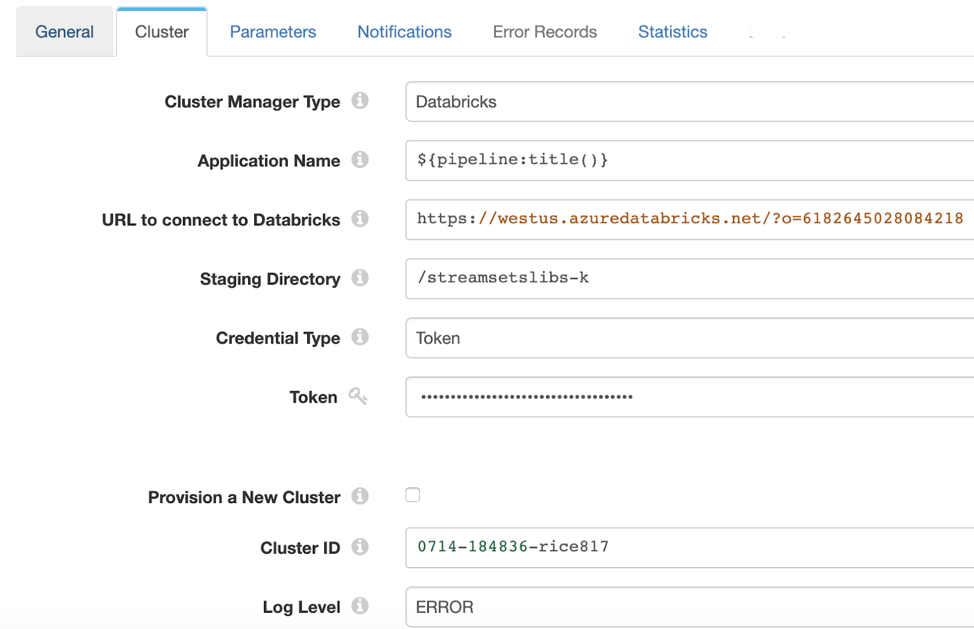
Transformer communicates with Databricks via simple REST APIs. It orchestrates the uploading of code and running of jobs in Databricks via these secure APIs.
A simple configuration dialogue in a Transformer pipeline allows a customer to connect Transformer to their Databricks environment. Note that Transformer supports both interactive and data engineering clusters in Databricks, giving customers the flexibility to choose the right cluster type for the right use case.
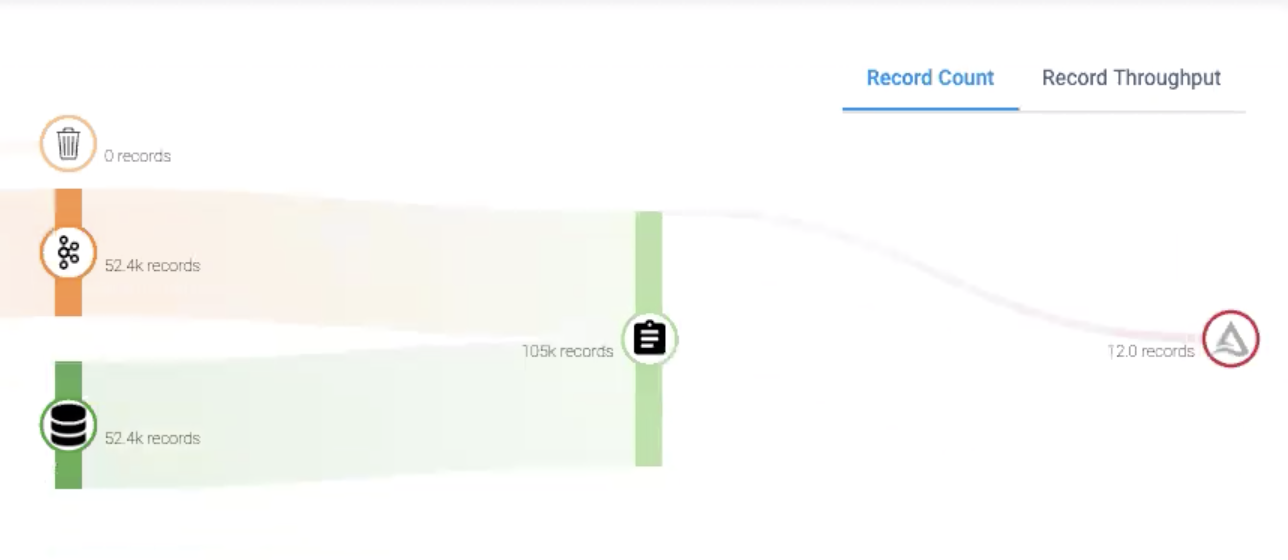
Monitoring of Delta Lake pipelines is also a critical capability of integration because it gives customers a visual window into the health and status of how well an ingestion job or transformation pipeline is doing. For example, the below screenshot depicts the flow of records from a relational source & Kafka into a Delta table and it can be monitored for throughput or record count.
Change Data Capture (CDC) with Delta Lake’s MERGE
Data lakes such as Delta Lake bring together data from multiple origin data sources into a central location for holistic analytics. If the source data in an origin data source changes, it becomes imperative to reflect that change in Delta Lake so data remains fresh and accurate. Equally important is the need to manage that change reliably so end users do not end up doing analytics on partially ingested or dirty data.
Change data capture (CDC) is one such technique to reconcile changes in a source system with a destination system. StreamSets has out of the box CDC capability for popular relational data sources (such as mysql, postgres and more), which makes it possible to capture changes in those databases. In many cases, StreamSets reads the binary log of the relational system to capture changes, which means the source database does not experience any performance or load impact from CDC pipelines.
Streamsets has implemented Delta’s MERGE functionality which makes it possible to reconcile changes from CDC sources to Delta tables with a simple visual pipeline automatically, hence simplifying CDC pipelines from source systems into Delta Lake for customers.
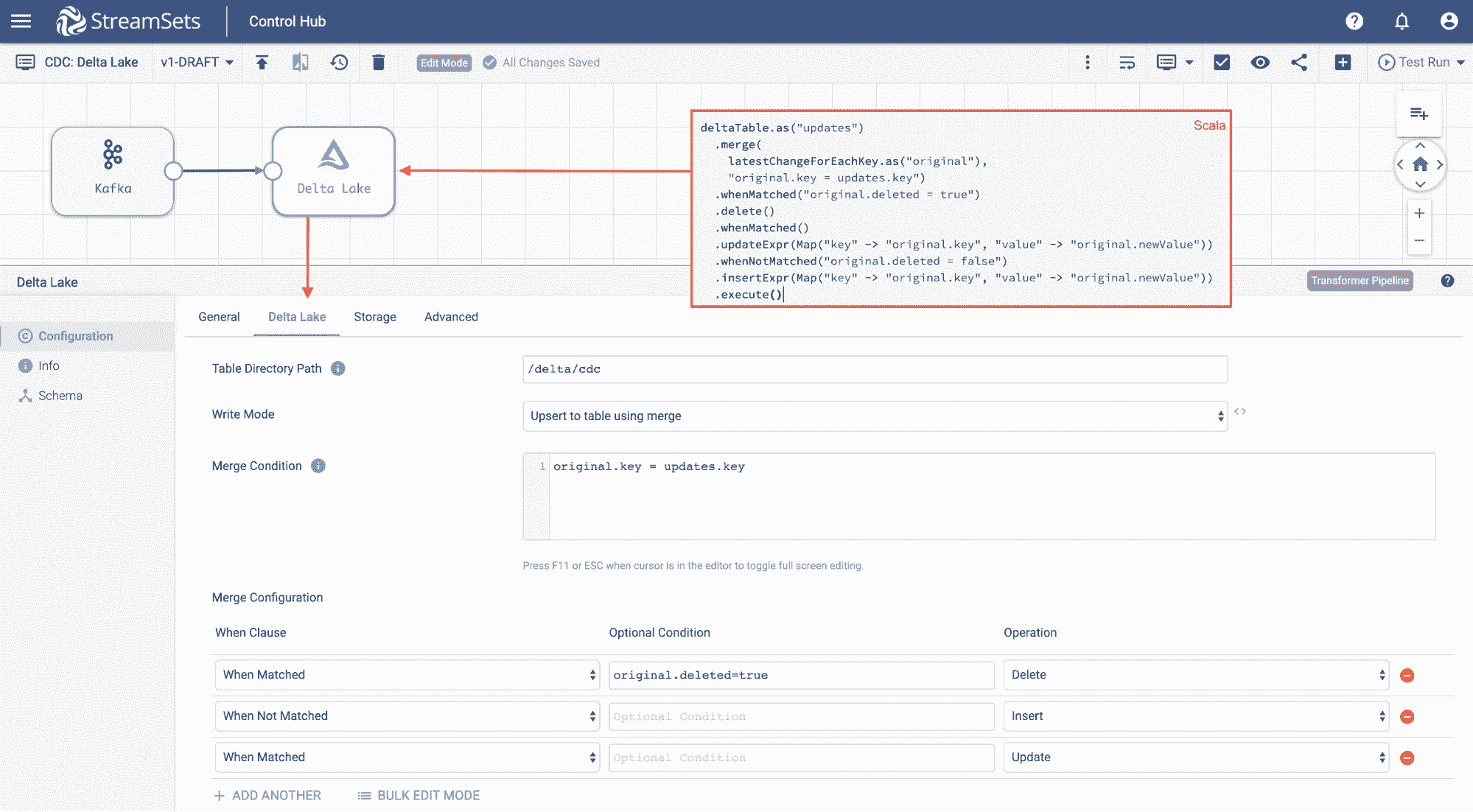
Because StreamSets uses Delta to implement the CDC pipeline, customers get the benefit of transactional semantics and performance of Delta Lake on the CDC ingest process, which guarantees that fresh reliable data is available in the lake, in a format that's optimized for downstream analytics.
How to Get Started with Databricks and StreamSets New Ingest Solution
We are excited about this integration and its potential for accelerating analytics and ML projects in the cloud. To learn more, register for this Manage Big Data Pipelines in the Cloud Webinar. We will show a live demo of how easy it is to build high-volume data pipelines to move data into Delta lake.
Related Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.