New Databricks Integration for Jupyter Bridges Local and Remote Workflows
Integrate your local Jupyter Notebook into Databricks Workspaces
Introduction
For many years now, data scientists have developed specific workflows on premises using local filesystem hierarchies, source code revision systems and CI/CD processes.
On the other side, the available data is growing exponentially and new capabilities for data analysis and modeling are needed, for example, easily scalable storage, distributed computing systems or special hardware for new technologies like GPUs for Deep Learning.
These capabilities are hard to provide on premises in a flexible way. So companies more and more leverage solutions in the cloud and data scientists have the challenge to combine their existing local workflows with these new cloud based capabilities.
The project JupyterLab Integration, published in Databricks Labs, was built to bridge these two worlds. Data scientists can use their familiar local environments with JupyterLab and work with remote data and remote clusters simply by selecting a kernel.
Example scenarios enabled by JupyterLab Integration from your local JupyterLab:
- Execute single node data science Jupyter notebooks on remote clusters maintained by Databricks with access to the remote Data Lake.
- Run deep learning code on Databricks GPU clusters.
- Run remote Spark jobs with an integrated user experience (progress bars, DBFS browser, ...).
- Easily follow deep learning tutorials where the setup is based on Jupyter or JupyterLab and run the code on a Databricks cluster.
- Mirror a remote cluster environment locally (python and library versions) and switch seamlessly between local and remote execution by just selecting Jupyter kernels.
This blog post starts with a quick overview how using a remote Databricks cluster from your local JupyterLab would look like. It then provides an end to end example of working with JupyterLab Integration followed by explaining the differences to Databricks Connect. If you want to try it yourself, the last section explains the installation.
Using a remote cluster from a local Jupyterlab
JupyterLab Integration follows the standard approach of Jupyter/JupyterLab and allows you to create Jupyter kernels for remote Databricks clusters (this is explained in the next section). To work with JupyterLab Integration you start JupyterLab with the standard command:
In the notebook, select the remote kernel from the menu to connect to the remote Databricks cluster and get a Spark session with the following Python code:
The video below shows this process and some of the features of JupyterLab Integration.
https://www.youtube.com/watch?v=VUqA8hp9bnk
Databricks-JupyterLab Integration — An end to end example
Before configuring a Databricks cluster for JupyterLab Integration, let’s understand how it will be identified: A Databricks clusters runs in cloud in a Databricks Data Science Workspace. These workspaces can be maintained from a local terminal with the Databricks CLI. The Databricks CLI stores the URL and personal access token for a workspace in a local configuration file under a selectable profile name. JupyterLab Integration uses this profile name to reference Databricks Workspaces, e.g demo for the workspace demo.cloud.databricks.com.
Configuring a remote kernel for JupyterLab
Let’s assume the JupyterLab Integration is already installed and configured to mirror a remote cluster named bernhard-5.5ml (details about installation at the end of this blog post).
The first step is to create a Jupyter kernel specification for a remote cluster, e.g. in the workspace with profile name demo:
The following wizard lets you select the remote cluster in workspace demo, stores its driver IP address in the local ssh configuration file and installs some necessary runtime libraries on the remote driver:
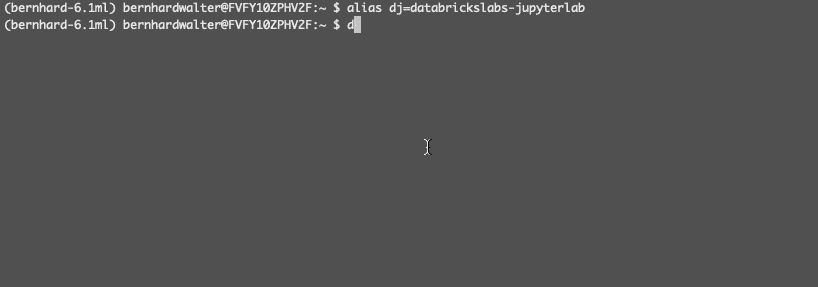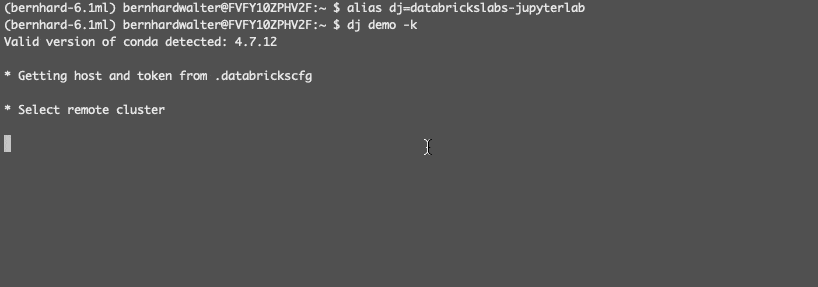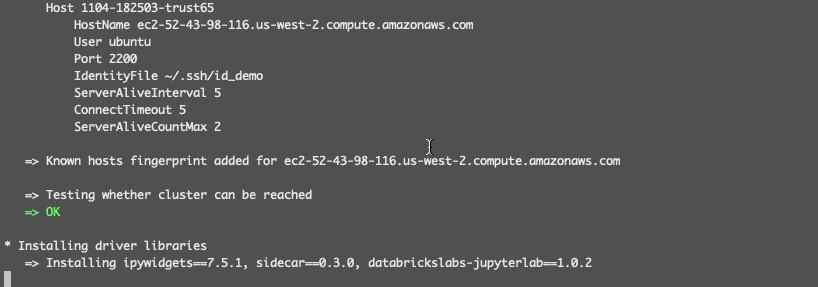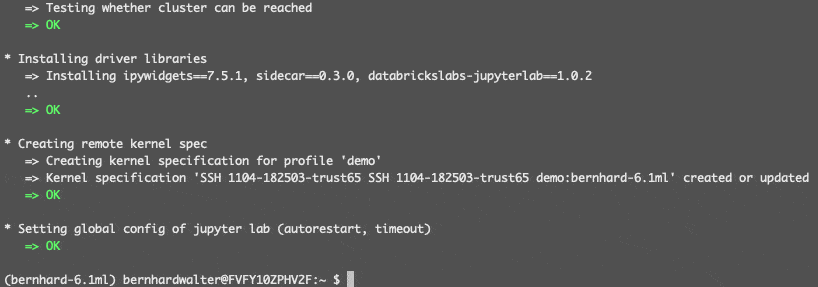
At the end, a new kernel SSH 1104-182503-trust65 demo:bernhard-6.1ml will be available in JupyterLab (the name is a combination of the remote cluster id 1104-182503-trust65, the Databricks CLI profile name demo, the remote cluster name bernhard-6.1ml and optionally the local conda environment name).
Starting JupyterLab with the Databricks integration
Now we have two choices to start JupyterLab, first the usual way:
This will work perfectly, when the remote cluster is already up and running and its local configuration is up to date. However, the preferred way to start JupyterLab for JupyterLab Integration is
This command automatically starts the remote cluster (if terminated), installs the runtime libraries “ipykernel” and “ipywidgets” on the driver and saves the remote IP address of the driver locally. As a nice side effect, with flag -c the personal access token is automatically copied to the clipboard. You will need the token in the next step in the notebook to authenticate against the remote cluster. It is important to note that the personal access token will not be stored on the remote cluster.
Getting a Spark Context in the Jupyter Notebook
To create a Spark session in a Jupyter Notebook that is connected to this remote kernel, enter the following two lines into a notebook cell:
This will request to enter the personal access token (the one that was copied to the clipboard above) and then connect the notebook to the remote Spark Context.
Running hyperparameter tuning locally and remotely
The following code will run on both a local Python kernel and a remote Databricks kernel. Running locally, it will use GridSearchCV from scikit-learn with a small hyperparameter space. Running on the remote Databricks kernel, it will leverage spark-sklearn to distribute the hyperparameter optimization across Spark executors. For different settings on local and remote environment (e.g. paths to data), the function is_remote() from JupyterLab Integration can be used.
- Define the data locations both locally and remotely and load GridSearchCV
- Load the data
- Define the different hyperparameter spaces for local and remote execution
- Finally, evaluate the model
Below is an video demo for both a local and a remote run:
https://www.youtube.com/watch?v=Dih6RcYS7as
JupyterLab Integration and Databricks Connect
Databricks Connect allows you to connect your favorite IDE, notebook server, and other custom applications to Databricks clusters. It provides a special local Spark Context which is basically a proxy to the remote Spark Context. Only Spark code will be executed on the remote cluster. This means, for example, if you start a GPU node in Databricks for some Deep Learning experiments, with Databricks Connect your code will run on the laptop and will not leverage the GPU of the remote machine:
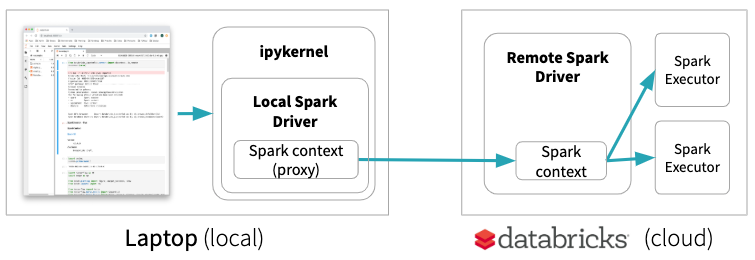
JupyterLab Integration, on the other hand, keeps notebooks locally but runs all code on the remote cluster if a remote kernel is selected. This enables your local JupyterLab to run single node data science notebooks (using pandas, scikit-learn, etc.) on a remote environment maintained by Databricks or to run your deep learning code on a remote Databricks GPU machine ⓶.
Your local JupyterLab can also execute distributed Spark jobs on Databricks clusters ⓵ with progress bars providing the status of the Spark job.
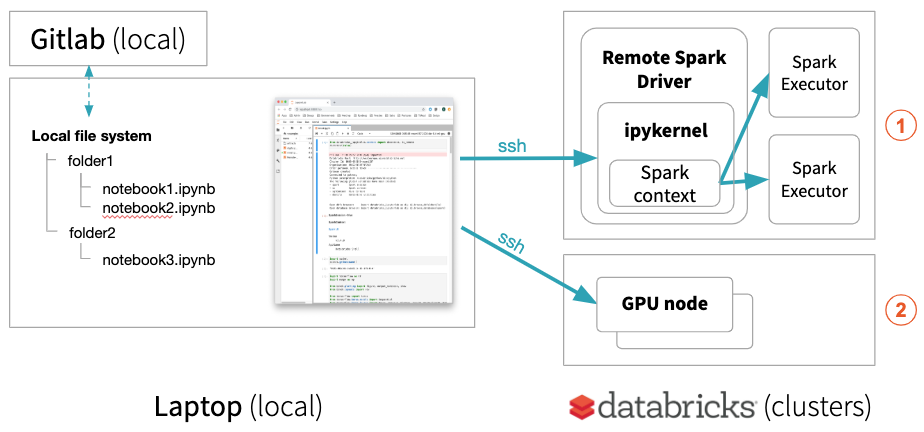
Furthermore, you can set up a local conda environment that mirrors a remote cluster. You can start building out your experiment locally, where you have full control over your environment, processes and easy access to all log files. When the code is stable, you can use the remote cluster to apply it to the full remote data set or do distributed hyperparameter optimization on a remote cluster without uploading data with every run.
Note: If a notebook is connected to a remote cluster, its Python kernel runs on the remote cluster and neither local config files nor local data can be accessed with Python and Spark. To exchange files between the local laptop and DBFS on the remote cluster, use Databricks CLI to copy data back and forth:
Since e.g. Pandas cannot access files in DBFS via dbfs:/, there is a mount point /dbfs/ that allows to access the data in DBFS (like /dbfs/data/abc.csv) with standard libraries of Python.
JupyterLab Integration Installation
After we have seen how JupyterLab Integration works, let’s have a look at how to install it.
Prerequisites
JupyterLab Integration will run for Databricks on both AWS and Azure Databricks. The setup is based on the Databricks CLI configuration and assumes:
- Anaconda is installed (the libraries for the JupyterLab Integration will be installed later)
- Databricks CLI is installed and configured for the workspace you want to use
- An SSH key pair is created for the cluster you want to use
- The cluster you want to use is SSH enabled and has the public key from 3 installed
Note: It currently only runs on MacOS and Linux and tested with Databricks Runtime 5.5, 6.0 and 6.1 (Standard and ML).

The convention is that the SSH key pair is named after the name of the Databricks CLI profile name. For more details on prerequisites, please see the “prerequisites” section of the documentation.
Installation
- Create a local conda environment and install JupyterLab Integration:
The prefix (db-jlab)$ for the command examples in this blog post shows that the conda environment db-jlab is activated.
The terminal command name databrickslabs-jupyterlab is quite long, so let’s create an alias - Bootstrap JupyterLab Integration:
This will Install the necessary libraries and extensions (using the alias from above): - Optionally, if you want to run the same notebook locally and remotely (mirroring):
This will ask for the name of a cluster to be mirrored and install all its data science related libraries in a local conda environment matching all versions.
Get started with JupyterLab Integration
In this blog post we have shown how JupyterLab Integration integrates remote Databricks clusters into locally established workflows by running Python kernels on the Databricks clusters via ssh. This allows data scientists to work in their familiar local environments with JupyterLab and access remote data and remote clusters in a consistent way. We have shown that JupyterLab Integration follows a different approach to Databricks Connect by using ssh. Compared to Databricks Data Science Workspaces and Databricks Connect, this enables a set of additional use cases.
https://github.com/databrickslabs/Jupyterlab-Integration
Related Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.