Solving the World’s Toughest Problems with the Growing Open Source Ecosystem and Databricks
by Reynold Xin
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
We started Databricks in 2013 in a tiny little office in Berkeley with the belief that data has the potential to solve the world’s toughest problems. We entered 2020 as a global organization with over 1000 employees and a customer base spanning from two-person startups to Fortune 10s.
In this blog post, let’s take a moment to look back and reflect on what we have achieved together in 2019. We will elaborate on the following themes: Solving the World’s Toughest Data Problems, New Developments in the Open Source Ecosystem, and how we are bridging the two with Databricks Platform enhancements.
- Solving the World's Toughest Problems
- New Developments in the Open Source Ecosystem
- Databricks Unified Data Analytics Platform
- Closing Thoughts
Solve the World’s Toughest Problems
As every year goes by, we encounter more use cases that reinforce our belief that leveraging data effectively is having a profound impact across all industries and disciplines, and we are proud of our part in this journey.
Thousands of organizations have entrusted Databricks with their mission-critical workloads, and have presented their progress at various conferences to disseminate best practices. Some great examples in 2019 include:
- Regeneron is able to analyze a massive corpus of genomics data and through machine learning was able to identify a portion of the genome that is responsible for chronic liver disease. By being able to process all of this data quickly, they are now able to create and test a potentially life-saving drug to fight chronic liver disease. To continue this momentum, Databricks and Regeneron teamed up earlier this year to launch Glow, an open-source toolkit for large-scale genomic analysis.
- FINRA is able to combat fraud by building a multi-petabyte graph using GraphFrames and then use machine learning to determine which part of graphs have clicks that point to market manipulation.
- Quby: Using Europe’s largest energy dataset, consisting of petabytes of IoT data, Quby has developed AI-powered products that are used by hundreds of thousands of users on a daily basis. To learn more about how Quby is conserving the planet, check out Saving Energy in Homes with a Unified Approach to Data and AI.
New Developments in the Open Source Ecosystem
At Spark + AI Summit EU 2019 in Amsterdam, we were excited to preview Apache Spark 3.0, the upcoming major version expected to be released in 2020, along with other major projects in the ecosystem: New Developments in the Open Source Ecosystem: Apache Spark 3.0, Delta Lake, and Koalas.

Open Source Delta Lake Project
Delta Lake is an open-source storage layer that brings reliability to data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Delta Lake runs on top of your existing data lake and is fully compatible with Apache Spark APIs.
The project has been deployed at thousands of organizations and processes more exabytes of data each week, becoming an indispensable pillar in data and AI architectures. More than 75% of the data scanned on the Databricks Platform is on Delta Lake!
Earlier in 2019, we announced that we were open sourcing the Delta Lake project as noted in the Spark + AI Summit 2019 keynote. Throughout the year, we quickly progressed from version 0.1.0 (April 2019) to version 0.5.0 (December 2019).
https://www.youtube.com/watch?v=R4f6SKOetB4
Some highlights include:
- Make Apache Spark™ Better with Delta Lake Webinar with Michael Armbrust
- Simple, Reliable Upserts and Deletes on Delta Lake Tables using Python APIs
- Diving Into Delta Lake: Unpacking The Transaction Log
- Delta Lake Now Hosted by the Linux Foundation to Become the Open Standard for Data Lakes
For a more comprehensive list of how-to blogs, webinars, and meetups and events, refer to the Delta Lake Newsletter (October 2019 edition).

Easily Scale pandas with Koalas!
For data scientists who love working with the pandas but need to scale, we announced the Koalas open source project. Koalas allows data scientists to easily transition from small datasets to big data by providing a pandas API on Apache Spark.
Even though this project started in early 2019, koalas now has 20,000 downloads per day!

As highlighted in the blog post How Virgin Hyperloop One reduced processing time from hours to minutes with Koalas:
By making changes to less than 1% of our pandas lines, we were able to run our code with Koalas and Spark. We were able to reduce the execution times by more than 10x, from a few hours to just a few minutes, and since the environment is able to scale horizontally, we’re prepared for even more data.
Simplifying Machine Learning Workflows
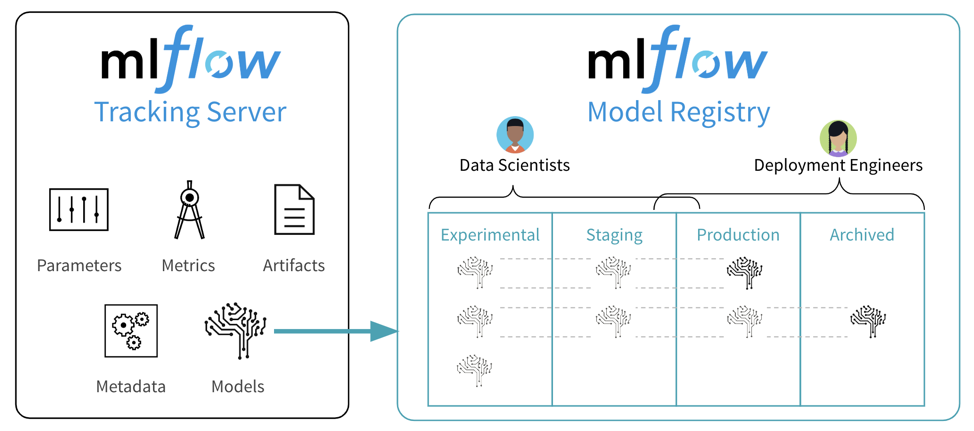
Introduced in 2018, the MLflow project has the ability to track metrics, parameters, and artifacts as part of experiments, package models and reproducible ML projects, and deploy models to batch or real-time serving platforms.
In 2019, the MLflow project has over 1 million downloads per month!
To help simplify machine learning model workflows, in Fall 2019, we introduced the MLflow Model Registry which builds on MLflow’s existing capabilities to provide organizations with one central place to share ML models, collaborate on moving them from experimentation to testing and production, and implement approval and governance workflows.
Databricks Unified Analytics Platform
The Databricks Unified Analytics Platform is a cloud platform for massive scale data engineering and collaborative data science.
In 2019, the Databricks Unified Data Analytics Platform has created more than one million virtual machines (VMs) every day!
We expanded the Databricks platform with many new features! The full list is quite extensive and can be found in the Databricks Platform Release Notes (AWS | Azure).
Optimizing Storage
In Databricks Runtime 6.0, we enhanced the FUSE mount that enables local file APIs to significantly improve read and write speed as well as support files that are larger than 2 GB. If you need faster and more reliable reads and writes such as for distributed model training, you would find this enhancement particularly useful. For example, as noted in this Spark+AI Summit 2019 session Simplify Distributed TensorFlow Training for Fast Image Categorization at Starbucks, the training of a simple CNN model improved by more than 10x (from 2.62min down to 14.65s).
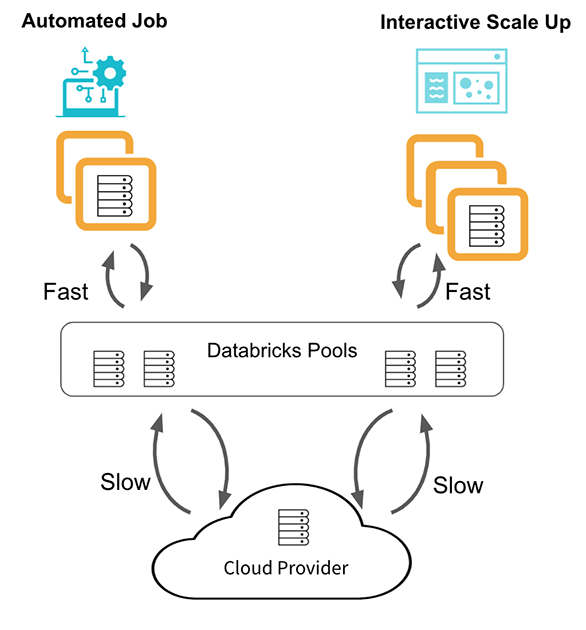
Databricks Pools
Recently, we launched Databricks pools to speed up your data pipelines and scale clusters quickly. Databricks pools is a managed cache of VM instances that allow you to achieve a reduction in cluster start and auto-scaling times from minutes to seconds!
As well, in 2019 we introduced more regions that are available to use Databricks. As of the end of 2019, there are 29 regions available in Azure and 13 regions in AWS with more coming in 2020!
Databricks Runtime and Databricks Runtime for Machine Learning
In 2019, Databricks Runtime (DBR) for Machine Learning became generally available! As of December 2019, there is DBR 6.2 GA, DBR 6.2 ML, and DBR 6.2 for Genomics. Every DBR release has been tested and verified for version compatibility thus simplifying the management of the different versions of TensorFlow, TensorBoard, PyTorch, Horovod, XGBoost, MLflow, Hyperopt, MLeap, etc.
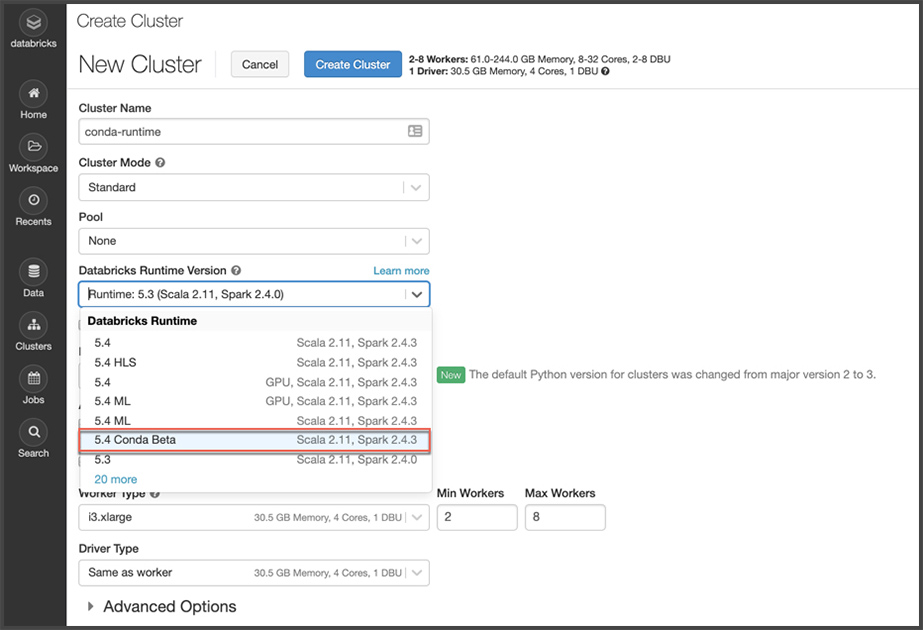
To simplify Python library and environment management, we also introduced Databricks Runtime with Conda (Beta) Many of our Python users prefer to manage their Python environments and libraries with Conda, which quickly is emerging as a standard. Conda takes a holistic approach to package management by enabling:
- The creation and management of environments
- Installation of Python packages
- Easily reproducible environments
- Compatibility with pip
Databricks Runtime with Conda (AWS | Azure) provides an updated and optimized list of default packages and a flexible Python environment for advanced users who require maximum control over packages and environments.
Automatic Logging for Managed MLflow
Managed MLflow on Databricks offers a hosted version of MLflow fully integrated with Databricks’ security model, interactive workspace, and MLflow Sidebar for Databricks Enterprise Edition and Databricks Community Edition.
https://www.youtube.com/watch?v=DFn3hS-s7OA
With Managed MLflow, it is now even easier for data scientists to track their machine learning training sessions for Apache Spark MLlib, Hyperopt, Keras, and Tensorflow without having to change any of their training code.
- Hyperparameter Tuning with MLflow, Apache Spark MLlib and Hyperopt
- Scaling Hyperopt to Tune Machine Learning Models in Python
- Automatic logging from Keras and TensorFlow
Augmenting Machine Learning with Databricks Labs’ AutoML Toolkit
Note: The Databricks Labs' AutoML Toolkit is a labs project to accelerate use cases on the Databricks Unified Analytics Platform.
As mentioned in the Spark+AI Summit Europe 2019 session Augmenting Machine Learning with Databricks Labs AutoML Toolkit, you can significantly streamline the process to build, evaluate, and optimize Machine Learning models by using the Databricks Labs AutoML Toolkit. Using the AutoML Toolkit also allows you to deliver results significantly faster because it allows you to automate the various Machine Learning pipeline stages.
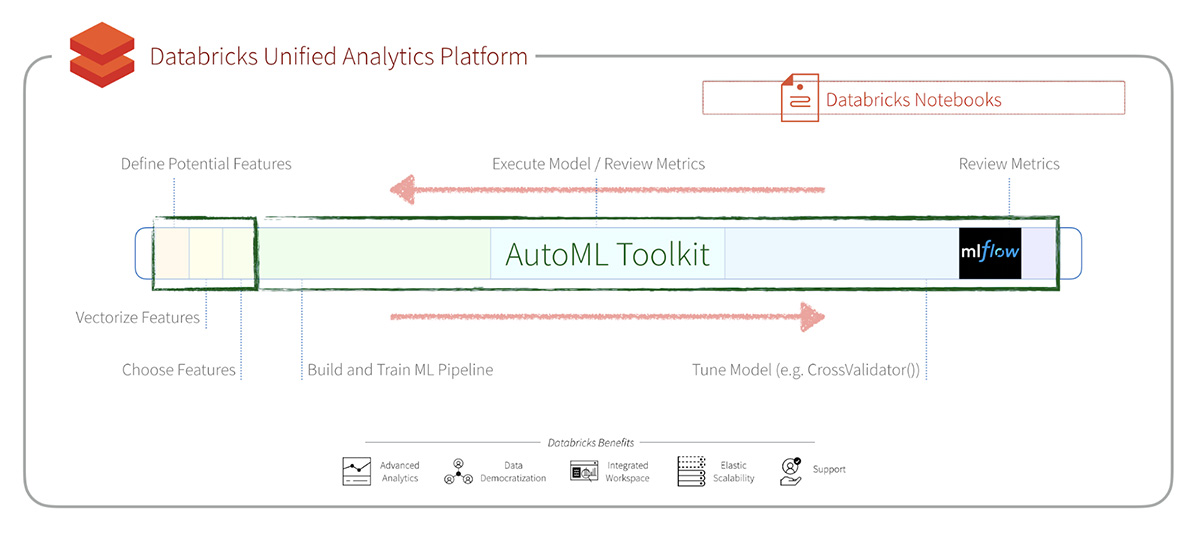
We further simplified the AutoML Toolkit by releasing the AutoML FamilyRunner allowing you to test with a family of different ML algorithms as noted in Using AutoML Toolkit’s FamilyRunner Pipeline APIs to Simplify and Automate Loan Default Predictions.
Closing Thoughts
2019 has been a great year at Databricks! In November 2019, we hired our 1,000th full-time employee. A lot has changed since our first year (2013), you can read more about it in Celebrating Growth at Databricks and 1,000 Employees!

As part of our amazing growth in 2019, we had both our Series E Funding (February 5th, 2019) and Series F Funding (October 22nd, 2019) with a $6.2 billion valuation! We are setting aside a €100 million ($110 million) slice of the Series F to expand the Amsterdam-based European development center. And at the end of the year, we announced that we were opening up our Databricks engineering office in Toronto in 2020!
This year (2020) will be an even more exciting year with the upcoming Apache Spark 3.0 release and our continued enhancements to Delta Lake, MLflow, Koalas, AutoML, and more! If you’re interested, find your place in Databricks!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.