Building Reliable Data Pipelines for Machine Learning Webinar Recap
This is a guest blog from Ryan Fox Squire | Product & Data Science at SafeGraph
At SafeGraph we are big fans of Databricks. We use Databricks every day for ad hoc analysis, prototyping, and many of our production pipelines. SafeGraph is a data company - we sell accurate and reliable data so our customers can build awesome analytics and software products. Databricks is also a partner of SafeGraph’s because many of our customers want to use SafeGraph data on top of the Databricks platform to help them create their own value with SafeGraph data. Databricks and SafeGraph are also partners of the AWS Data Exchange. You can learn more about Databricks and third party data providers on their AWS Data Exchange page.
Powering innovation through open access to geospatial data
The SafeGraph mission is to power innovation through open access to geospatial data. This is an important mission today because data is more valuable than ever. AI, ML, and data science applications are growing rapidly, and all those applications rely on access to high-quality data. We believe that data should be an open platform, not a trade secret. SafeGraph makes high quality data available to everyone, and Databricks helps extend the reach of that data by making it easier for everyone to work with data. At SafeGraph, we want to live in a world where if you have a good idea for how to use data, then there should be a way for you to get that data (and use it!).
In this blog post we will recap some of the points discussed in our webinar co-presented with Databricks, and we will cover some of the questions that came up in the webinar.
If you want to hear the whole webinar, you can access it at Building Reliable Data Pipelines for Machine Learning (Webinar). You can also access a free sample of SafeGraph data from the SafeGraph Data Bar; use the coupon code “Data4DatabricksFans.”
SafeGraph is the source of truth for data about physical places, so if you have an idea of something cool to build using data about the physical world, SafeGraph is here to help. We build data sets about points of interests (physical places) and we're 100% focused on making those data as complete and accurate as possible.
Today the SafeGraph data set covers over 6 million points of interest (POI) in the US and Canada, and we're primarily focused on all the commercial businesses where consumers can physically go and spend money or spend time. For example, all of the restaurants, retail shops, grocery stores, movie theaters, hotels, airports, parks, hardware stores, nail salons, bars, all these places where consumers physically visit. Understanding the physical world and having accurate data about all these points of interest has a wide range of applications including retail and real estate, advertising and marketing, insurance, economic development for local governments, and more.
The foundational data set is what we call SafeGraph Core Places. This is all the foundational metadata about a place like its name, its address, phone number, category information, does it belong to a major corporate brand or chain, etc.
On top of SafeGraph Places, we offer SafeGraph Patterns. The goal of SafeGraph Patterns is to provide powerful insights into consumer behavior as it relates to the physical world. SafeGraph Patterns is all about summarizing human movement or foot traffic to points of interest. It's keyed on the safegraph_place_id so that you can easily join SafeGraph Patterns to the other datasets.
One example of how customers use SafeGraph Patterns data is in retail real estate decisions. Opening a new location is a huge investment for companies, and so you want to know as much as possible to select the right location for your business. SafeGraph data can tell you about the identity and location of all of the other neighboring businesses in an area, whether these businesses are competitive or complementary to your business, and it also gives you a picture of the foot traffic and human movement around this location. An end user of SafeGraph Patterns can answer questions like “Did total footfall to McDonald's change from Q2 to Q3?”
This webinar focused on how we build SafeGraph Patterns. I provide a lot of details about this product and the process to build it in the webinar. Briefly, building SafeGraph Patterns is a large scale preference learning problem also known as a learning-to-rank model. We have a lot of training data and a lot of possible features. Let me summarize our journey of figuring out how to build the SafeGraph Patterns dataset at scale.
Solving the Large Scale Preference Learning Problem -- Four Steps To Maturity
The Local Approach: Originally when we tried to solve this problem, we started in a Jupyter notebook on a laptop computer. The data is quite large, the raw data can be as big as a terabyte per day. The computer started failing at 300 megabytes of the training data. This clearly wasn’t going to work.
The Cloud Approach: The next approach was to use a big cloud EC2 box to provide more memory than my laptop. We downloaded the data from AWS S3 on to this big cloud instance. Fitting the model was very slow (it took many hours), but it worked. I was able to train the model on a small fraction of the training data. Then I increased the data size and the EC2 box crashed. Not going to cut it.
“Distributed” Process: Next we tried a Databricks Spark cluster and map partitions (PySpark) the sklearn model across the full data. But when we try to run the model in production, it was way too slow. We are using a scikit-learn model that is single threaded, so we are not really taking advantage of a true distributed, multi-threaded approach.
Truly Distributed: To get the real benefit of our Databricks Spark cluster we turned to Spark ML libraries instead of python sklearn. We also created separate spark jobs for each processing step, so that all the data pre-processing happens in Scala instead of pyspark (much faster). This made a world of difference. The processing time is an order of magnitude faster, the model takes 30 minutes to train on the full terabytes of data, whereas before it was taking many hours to just do a subset of the data.
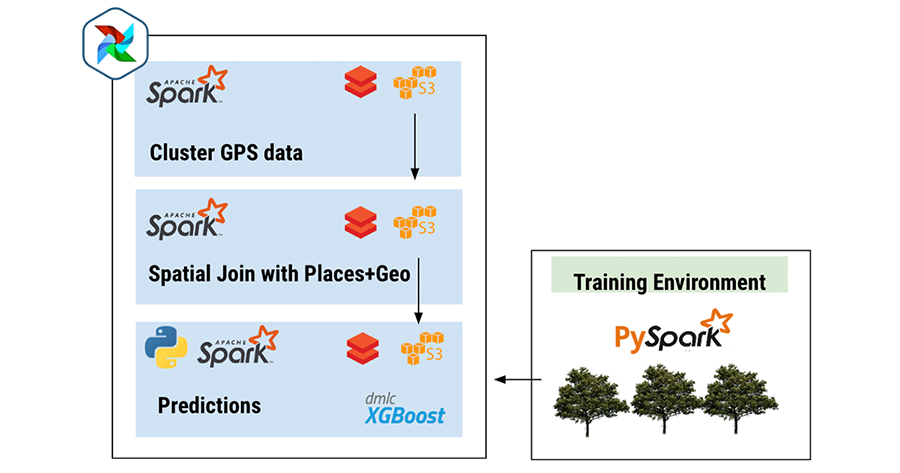
Embracing a truly distributed processing approach with Spark (scala, pyspark, sparkml) run on Databricks made a world of difference for our processing times.
For the full details, you should check out the original Building Reliable Data Pipelines for Machine Learning at SafeGraph Webinar.
Questions from the Building Reliable Data Pipelines for Machine Learning Webinar
How can I use SafeGraph data to figure out, for instance, where to build a school?
One of the questions on the webinar was “How can I use SafeGraph data to figure out, for instance, where to build a school?” We can generalize this to any sort of real estate decision. At SafeGraph our data helps a lot of customers make real estate decisions.
I always have to remind myself that when you're making real estate decisions, you are not working with a uniform opportunity space. You can't buy any real estate and put a school anywhere. Usually people are starting from a position of having some candidate places that they are considering. Those candidates come from criteria like what real estate locations are available, what is the budget, what is the square footage requirements, what are zoning requirements, etc.
We see our customers employ very sophisticated processes to model and predict how successful any particular location will be. You need data like “What is the overall population density within a certain drive time of this place?” and “What are the average demographics of this neighborhood?” (which you can get for free from Open Census Data). As well as data like “What are the competitive choices consumers are making in this neighborhood” (which you can get from SafeGraph Patterns). And you want to combine that with whatever point-of-view you have about your own target audience.
Where the SafeGraph data really adds value to those processes is that a lot of people have first-party data about their own locations, but almost no one has good data about their competitors or the other businesses in an area.SafeGraph gives you the opportunity to look not only at your own customers, and the foot-traffic to your own locations but also to look at complementary businesses and competitive businesses.
For example, SafeGraph Places has schools in the data set. So you would be able to see where all the schools are located. If you were looking to open an after-school program, like a tutoring center, that could be very helpful. Certainly, you want to be near the schools, but quite often they're in a residential neighborhood that are not zoned for a business. Then you're trying to figure out, “Where the nearby kinds of business zones, how is the parking, what are other competitors doing in that space in terms of after school traffic?” There's a lot of interesting puzzle solving that goes into each of these problems besides just being able to work the data, and I think that's what's really fun about this domain.
How to encode features for the preference learning model?
Another set of questions came up about how to encode features for the preference learning model. I go into a lot of details about the model in the webinar, so if you haven’t seen that I encourage you to view that (see: Building Reliable Data Pipelines for Machine Learning Webinar). I hadn't worked on a preference or learning-to-rank model before, and it's very interesting. We started by looking at a bunch of data with our human eyes and brains to figure out if we can correctly identify where visits are happening. We found ourselves doing a lot of things like trying to calculate distances between points or measuring whether points were closer to one business or another business. Ultimately we ended up using two distance related features in the model - one is the distance from POI boundary to the center of the point-cluster, and the second is the distance of the POI to the nearest point in the cluster. We also have time-of-day information. For example, if it's a bar, we know that bars and pubs have a different time-of-day popularity profile than if it's a grocery store or a hardware store. We were able to build those features by looking at a lot of examples, so time of day-by-category is another important feature in the model.
There's more features (and you can read all the details in SafeGraph’s full Visit Attribution White Paper), but the way that the learning to rank model works is that we look at all possibilities as pairs. Imagine a point-cluster that is nearby 5 possible businesses (POI). Each POI candidate has its features. Each pair of POI has two vectors (each POI’s feature vector). We take the difference between those two vectors and that gives us a single vector that we consider the feature vector for that pair. Then each pair in the training data gets labeled with the possible truth labels for whether it is correct or not. If you have a pair, A and B you have 3 possibilities: A is correct, B is correct or neither A or B are correct. So if you have six businesses in an area, only one of them is correct, but you have 30 head-to-head pairs to consider. Most of those pairs are going be both A and B are incorrect, but 5 of them will have a winner and a loser.
To train the model we threw out all of the neutral pairs (both A and B incorrect), and trained only on pairs where either A or B was correct. Our feature vector was just the difference between the two individuals feature vectors. The way the model was structured, it produces a ranking for each POI, and then you can rank them in retrospect, by saying, "Okay who won each head-to-head competition?” That gives you an overall ranking across all pairs, and then you just choose the highest ranked one. Check out the wikipedia page for learning-to-rank. This is a technique used a lot in search algorithms where you are trying to rank search results.
Learn More about SafeGraph and Databricks
Thanks for reading about our story! We hope we gave some context into how SafeGraph data provides value to our customers and how SafeGraph uses Databricks to help create that value. Thank you to everyone who participated in the webinar and for all of the great questions. If you want to hear the entire webinar, you can access it at Building Reliable Data Pipelines for Machine Learning Webinar. You can also access a free sample of SafeGraph data from the SafeGraph Data Bar--use the coupon code “Data4DatabricksFans.”
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.