New Data Ingestion Network for Databricks: The Partner Ecosystem for Applications, Database, and Big Data Integrations into Delta Lake
by Hiral Jasani
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
Organizations have a wealth of information siloed in various sources, and pulling this data together for BI, reporting and machine learning applications is one of the biggest obstacles to realizing business value from data. The data sources vary from operational databases such as Oracle, MySQL, etc. to SaaS applications like Salesforce, Marketo, etc. Ingesting all this data into a central lakehouse is often hard, in many cases requiring custom development and dozens of connectors or APIs that change over time and then break the data loading process. Many companies use disparate data integration tools that require data engineers to write scripts and schedule jobs, schedule triggers and handle job failures, which does not scale and creates massive operational overhead.
Introducing the Data Ingestion Network
To solve this problem, today we launched our Data Ingestion Network that enables an easy and automated way to populate your lakehouse from hundreds of data sources into Delta Lake. We are excited about the many partners announced today that have joined our Data Ingestions Network - Fivetran, Qlik, Infoworks, StreamSets, Syncsort. Their integrations to Data Ingest provide hundreds of application, database, mainframe, file system, and big data system connectors, and enable automation to move that disparate data into an open, scalable lakehouse on Databricks quickly and reliably. Customers using Azure Databricks already benefit from the native integration with Azure Data Factory to ingest data from many sources.
Key Benefits of the Data Ingestion Network
1. Real-time, Automated Data Movement
The ingest process is optimized for change data capture (CDC), and enables easy automation to load new or updated datasets into Delta Lake. Data engineers no longer need to spend time developing this complex logic, or processing the datasets manually each time. The data in Delta Lake can be automatically synced with changes and kept up to date.
2. Out-of-the-Box Connectors
Data engineers, Data scientists, and Data analysts have access to out-of-the-box connectors through the Data Ingest Network of partners to SaaS applications like Salesforce, Marketo, Google Analytics, and Databases like Oracle, MySQL and Teradata, plus file systems, mainframes, and many others. This makes it much easier to set up, configure and maintain the data connections to hundreds of different sources.
3. Data Reliability
Data ingestion into Delta Lake supports ACID transactions that makes data ready to query and analyze. This makes more enterprise data available to BI, reporting, data science and machine learning applications to drive better decision-making and business outcomes.
Data Ingestion Set Up in 3 Steps
End-users can discover and access the integration setup the Data Ingestion Network of partners through the Databricks Partner Gallery.
Step 1: Partner Gallery
Navigate to the Partner Integrations menu to see the Data Ingestion Network of partners. We call this the Partner Gallery. Follow the Set up guide instructions for your chosen partner.

Step 2: Set up Databricks
Next, set up your Databricks workspace to enable partner integrations to push data into Delta Lake. Do the following:
- Create a Databricks token that will be used for authentication by the partner product
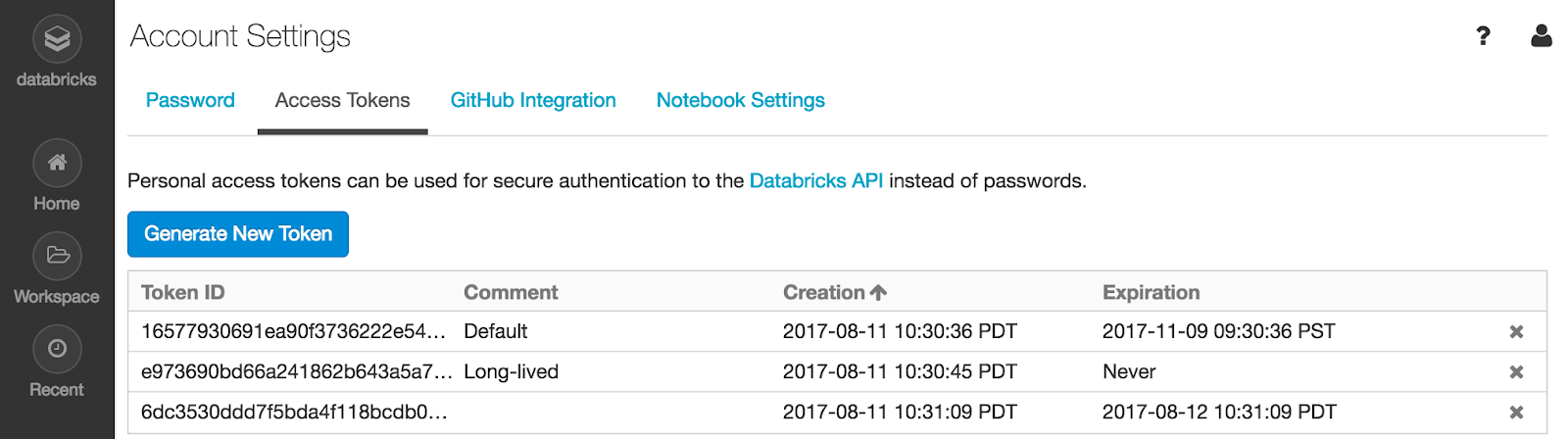
- From the Databricks cluster page, copy the JDBC/ODBC URL
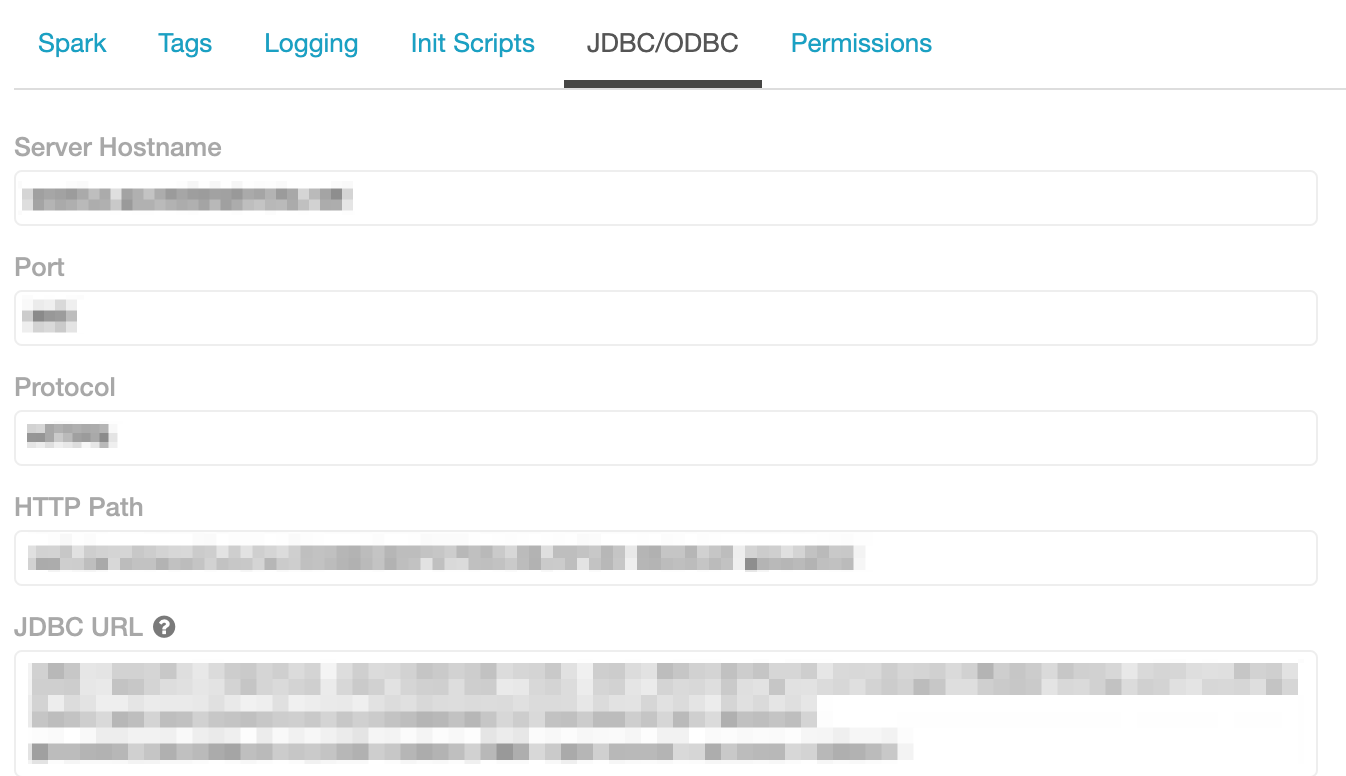
Step 3: Choose the data sources, select Databricks as the destination
Using the partner product, choose the data sources you want to pull data from and choose Databricks as the destination. Enter the token and JDBC information from step 2, and set up the job that will then pull data from your data source and push it into Databricks in the Delta Lake format.
That’s it! Your data is now in Delta Lake, ready to query and analyze.
A Powerful Data Source Ecosystem to Address Data Ingestion Needs
The Data Ingestion Network is a managed offering that allows data teams to copy and sync data from hundreds of data sources using auto-load and auto-update capabilities. Fivetran, Qlik, Infoworks, StreamSets, and Syncsort are available today, along with Azure Data Factory that already provided native integration for Azure Databricks customers to ingest data from many sources. Together these partners enable access to an extensive collection of data sources that are both cloud-based and on-premises.

The Goal of the Data Ingestion Network
With the Data Ingestion Network, we set out to build an ecosystem of data access that allows customers to realize the potential of combining big data and data from cloud-based applications, databases, mainframes and files systems. By simplifying the data ingestion process compared to traditional ETL, customers have the ability to overcome the complexity and maintenance cost typically associated with pulling data together from many disparate sources. This accelerates the path to maximizing the business value from data across BI, reporting and machine learning applications.
To learn more:
Sign up for our webinar: Introducing Databricks Ingest: Easily load data into Delta Lake to enable BI and ML.
Talk to an expert: Contact us
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.