Productionize and Automate your Data Platform at Scale
Data-driven innovation is no longer optional to stay competitive in today's marketplace. Companies that can bring data, analytics, and ML-based products to market first will quickly beat their competition. While many companies have streamlined CI/CD (continuous integration and delivery) processes for application development, very few have well-defined processes for developing data and ML products.
That’s why it’s critical to have production-ready, reliable and scalable data pipelines that feed the analytics dashboards and ML applications your managers use. As new feature sets are developed, data scientists, data analysts and data engineers need consistent toolsets and environments that help them rapidly iterate on ideas. As these ideas progress, they need to be tested and taken from development to production rapidly. Once they are in production, the ML models and analytics need to be constantly monitored for effectiveness, stability, and scale.
If you want to accelerate the creation of new and innovative data products, you will need to rely heavily on automation to overcome the following challenges.
Lack of consistent and collaborative development environments
When a new team is spinning up in an organization to build their data product or service, they need the infrastructure, tools and enterprise governance policies set up before they can start. We refer to this as a ‘fully configured’ data environment. This requires coordination and negotiations with multiple teams in the organization and may take days (if not weeks or months). The ideal would be to get such a fully configured data environment on-demand within minutes.
Lack of consistent Devops processes
A lot of code is written by data teams to manage the data itself — like code for data ingestion, data quality, data cleanup, and data transformations. All of this is needed before the data can be utilized by downstream teams for business intelligence and machine learning. Machine learning flows themselves are very iterative. The amount and variety of data changes rapidly, thus requiring changes to the code that handles the data pipelines, and trains machine learning models. Like any other application development codebase, this requires the discipline of a CI/CD pipeline to ensure quality, consistency, and idempotency. Ideally, data engineers and data scientists — like app dev engineers — could focus on iterations of code and let the data platform and tools apply the right quality gates to transport the code to production.
Limited visibility into data pipeline and ML model performance
Data environments can change on multiple dimensions — the underlying data, the code for data transformations in data pipelines, and the models that are built using the data. Any of these can affect the behavior and performance of applications that depend on it. Multiply that by hundreds of teams deploying thousands of applications and services. The problem of scaling and monitoring the health and performance of such applications becomes complex. DevOps teams supporting data platforms for the organization need automated tools that help data teams scale as their workloads become larger and leverage monitoring tools to be able to ensure the health of these applications.
Fully configured data environments on-demand
Deploy workspace Connect data sources Provision users and groups Create clusters and cluster policies Add permissions for users and groups
Deploy workspace - A global organization should be able to serve the data platform needs of their teams by provisioning data environments closest to where their data teams are — and more importantly, co-locate the services where the data resides. As the data platform leader of the organization, you should be able to service the needs of these teams on multiple clouds and in multiple regions. Once a region is chosen, the next step is deploying completely isolated ‘environments’ for the separate teams within the organization. Workspaces can represent such environments that isolate the teams from each other while still allowing the team members to collaborate among themselves. These workspaces can be created in an automated fashion, by calling Workspace REST APIs directly or using a client-side Workspace provisioning tool that uses those APIs.
Connect data sources -The next step is connecting data sources to the environment, including mounting data sources within the workspace. In order to access these cloud-native data sources with the right level of permissions from within the data environment, the appropriate permissions and roles can be set up using standardized infrastructure-as-code tools like Terraform.
Provision users and groups - The next step is to provision users and groups within the workspace using a standards-based SCIM API. This can be further automated when using Identity Provider (IdP), like Azure Active Directory, Okta, etc., by setting up automated sync between the IdP and Databricks. This enables seamless management of users in one standard location, IdP.
Create clusters and cluster policies - Now that users and data have been provisioned, you need to set up the compute so that users can run their workloads to process data. The clusters object represents the fully managed, auto-scaling unit of compute in a workspace. Typically, organizations have two modes of instantiating clusters. First, the long-running, static cluster that is used for interactive workloads - data scientists doing exploratory analysis in their notebooks. Second, is the transient cluster that is created because of scheduled or on-demand automated jobs. The static clusters are set up by the admins in the process of creating the data environment using the clusters APIs. This ensures that the clusters conform to policies such as using the right instance types for VMs, using the right runtimes, using the right tags, etc. You can also configure the clusters to have the right set of libraries using the library APIs, so end users don’t have to worry about it. Transient clusters by definition are created at run time, so the policies have to be applied only at runtime. To automate this you can use Cluster Policies that help you define the parameters of any cluster that can be created by any user in the workspace, thus ensuring that these clusters are compliant with your policies.
Grant permissions - Next you would want to give your users and groups the right level of permissions on objects in the data environment so they can do their jobs. Databrick supports fine-grained access controls on objects such as clusters, jobs, notebooks, pools, etc. These can be automated using permissions API (in Preview).

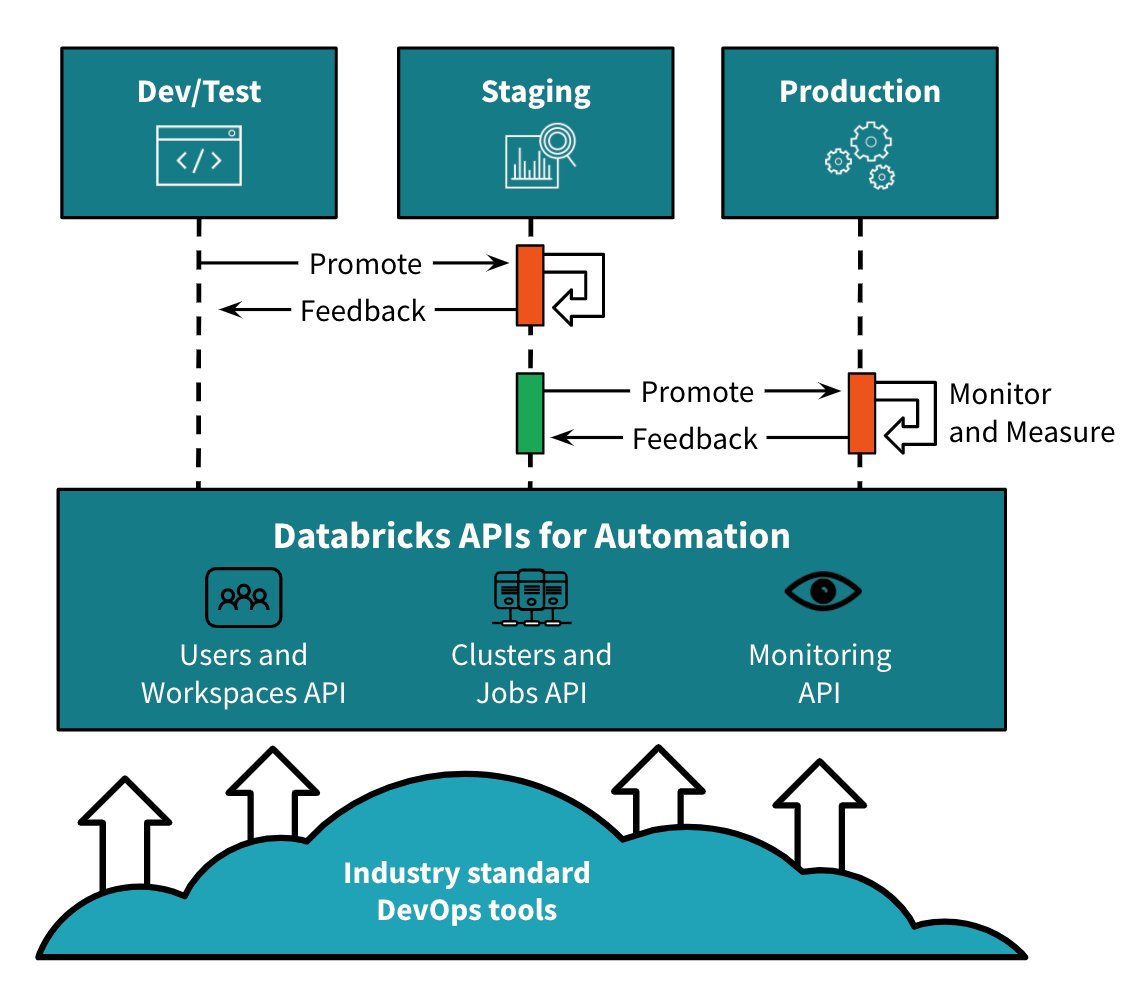
The CI/CD pipeline
Development environment - Now that you have delivered a fully configured data environment to the product (or services) team in your organization, the data scientists have started working on it. They are using the data science notebook interface that they are familiar with to do exploratory analysis. The data engineers have also started working in the environment and they like working in the context of their IDEs. They would prefer a connection between their favorite IDE and the data environment that allows them to use the familiar interface of their IDE to code and, at the same time, use the power of the data environment to run through unit tests, all in context of their IDE.
Any disciplined engineering team would take their code from the developer’s desktop to production, running through various quality gates and feedback loops. As a start, the team needs to connect their data environment to their code repository on a service like git so that the code base is properly versioned and the team can work collaboratively on the codebase.
Staging/Integration environment - While hundreds of data scientists and data engineers are working in the development phase in the data environment when the time comes to push a set of changes to the integration testing phase, more control is required. Typically, you want fewer users to have access to the integration testing environment where tests are running continuously and results are being reported and changes are being promoted further. In order to do that, the team requires another workspace to represent their ‘staging’ environment. Another fully configured environment can be delivered very quickly to this team. Integration with popular continuous integration tools such as Jenkins or Azure Devops Services, enables the team to continuously test the changes. With more developers and more workloads, the rate of changes to the code base increases. There is a need to run tests faster. This also requires the underlying infrastructure to be available very quickly. Databricks pools allow the infrastructure to be held in a ready-to-use state while preventing runaway costs for always-on infrastructure. With all this tooling in place, the team is able to realize the ‘Staging’ environment for their continuous integration workflows.
Production environment - Eventually, when the code needs to be deployed to production — similar to the fully configured staging environment —a fully configured production environment can be provisioned quickly. This is a more locked-down environment, with access for only a few users. Using their standard deployment tools and by leveraging the well-defined REST APIs of the platform, the team can deploy the artifacts to their production environment.
Once this CI/CD pipeline is set up, the team can quickly move their changes from a developer desktop to production, while testing at scale, using familiar tools to ship high-quality products.
Streamlined operations
Over time, as the amount of data being processed increases, data teams need to scale their workloads. DevOps teams need to ensure that the data platform can scale seamlessly for their workloads. The DevOps teams can leverage auto-scaling capabilities in the data platform to deliver a seamless automated scale for these workloads. Additionally, a platform that is available on multiple clouds, and multiple regions in each cloud (AWS, Azure) allows the DevOps teams to deliver an at-scale platform to data teams, wherever they are operating in the world.
DevOps is in charge of supporting the data platform being used by teams across the organization. They would like to ensure the three layers of data environment are working as expected — infrastructure, platform, and application. At the bottom is the infrastructure, the compute that is used to perform the data processing jobs. Integration with tools such as Ganglia and Datadog provide visibility into core infrastructure metrics including CPU, memory, and disk, usage etc. A layer above infrastructure is the data platform. Objects such as clusters and jobs enable DevOps teams to automate analytics and machine learning workflows. Performance metrics for these objects can be consumed using REST APIs for Cluster Events and Jobs and plugged into the monitoring tool of choice for the organization. The last layer is the application, specifically the Spark-based application. Visibility into monitoring data using spark logs from Apache Spark application enables the team to troubleshoot failures and performance regressions and design optimizations for running workloads efficiently.
The automation interfaces enable the DevOps teams to apply consistent tooling across the CI/CD pipeline and integrate performance monitoring not only in production but also in lower-level environments. It allows the teams to debug the changes and also test out the performance monitoring workflow itself before the changes reach production.
Take innovations to market faster
AI/ML-driven innovations are happening organically in every enterprise in all sectors of the economy. Enterprises can realize the full potential of those innovations only when these innovations are developed, tested and productionized rapidly so their customers can use them. In order to do that, the organization needs a reliable, global scale, easy to use data platform that enables CI/CD for AI/ML applications and that can be made available to any team in the organization quickly.
Learn more about other steps in your journey to create a simple, scalable and production-ready data platform, ready the following blogs
Enabling Massive Data Transformation Across Your Organization
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.