Data Science with Azure Databricks at Clifford Chance
by Mirko Bernardoni and Lulu Wan
Guest blog by Mirko Bernardoni (Fiume Ltd) and Lulu Wan (Clifford Chance)
Introduction
With headquarters in London, Clifford Chance is a member of the "Magic Circle" of law firms and is one of the ten largest law firms in the world measured both by number of lawyers and revenue.
As a global law firm, we support clients at both the local and international level across Europe, Asia Pacific, the Americas, the Middle East and Africa. Our global view, coupled with our sector approach, gives us a detailed understanding of our clients' business, including the drivers and competitive landscapes.
To achieve our vision of becoming the global law firm of choice we must be the firm that creates the greatest value for our clients. That means delivering service that is ever quicker, simpler, more efficient and more robust. By investing in smart technology and applying our extensive legal expertise, we can continually improve value and outcomes for clients, making delivery more effective, every time.
Applying data science to legal work
Artificial intelligence is growing at a phenomenal speed and is now set to transform the legal industry by mining documents, reviewing and creating contracts, raising red flags and performing due diligence. We are enthusiastic early adopters of AI and other advanced technology tools to enable us to deliver a better service to our clients.
To ensure we are providing the best value to our clients, Clifford Chance created an internal Data Science Lab, organised similar to a startup inside the firm. We are working with, and as part of the Innovation Lab and Best Delivery Hub in Clifford Chance where we deliver initiatives helping lawyers do their daily work.
Applying data science to the lawyer's work comes with many challenges. These include handling lengthy documents, working with a specific domain language, analysing millions of documents and classifying them, extracting information and predicting statements and clauses. For example, a simple document classification can become a complex exercise if we consider that our documents contain more than 5,000 words.
Data Science Lab process
The process that enables the data science lab to work at full capacity can be summarised in four steps:
- Idea management. Every idea is catalogued with a specific workflow for managing all progression gates and stakeholder’s interaction efficiently. This focuses us on embedding the idea in our existing business processes or creating a new product.
- Data processing. It is up to the Data Science Lab to collaborate with other teams to acquire data, seek the necessary approvals and transform it in such a way that only the relevant data with the right permission in the right format reaches the data scientist. Databricks with Apache SparkTM — we have an on-premise instance for filtering and obfuscating the data based on our contracts and regulations — allows us to move the data to Azure efficiently. Thanks to the unified data analytics platform, the entire data team — data engineers and data scientists — can fix minor bugs in our processes.
- Data science. Without Databricks it would be incredibly expensive for us to conduct research. The size of the team is small, but we are always looking to implement the latest academic research. We need a platform that allows us to code in an efficient manner without considering all the infrastructure aspects. Databricks provides a unified, collaborative environment for all our data scientists, while also ensuring that we can comply with the security standards as mandated by our organisation.
- Operationalisation. The Databricks platform is used to re-train the models and run the ETL process which moves data into production as necessary. Again, in this case, unifying data engineering and data science was a big win for us. It reduces the time to fix issues and bugs and helps us to better understand the data.
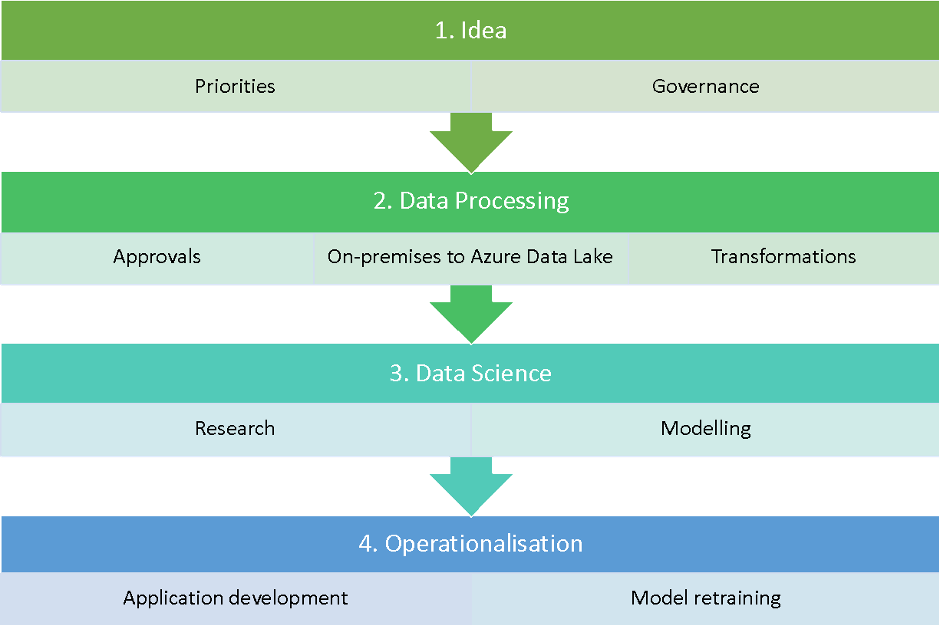
Workflow process for Data Science Lab
Data Science Lab toolkit
The Data Science Lab requirements for building our toolkit are:
- Maintain high standards of confidentiality
- Build products as quickly as possible
- Keep control of our models and personalisation
- A small team of four members with mixed skills and roles
These requirements drove us to automate all of our processes and choose the right platforms for development. We had to unify data engineering and data science while reducing costs and time required to be operational.
We use a variety of third-party, Azure Cloud, open-source and in-house build tools for our data stack:
- Spark on-premise installation for applying the first level of governance on our data (such as defining what can be copied in the cloud)
- Kafka and Event Hub are our transport protocol for moving the data in Azure
- Databricks Unified Data Analytics Platform for any ETL transformation, iterate development and test our built-in models
- MLflow to log models’ metadata, select best models and hyperparameters and models deployment
- Hyperopt for model tuning and optimisation at scale
- Azure Data Lake with Delta Lake for storing our datasets, enabling traceability and model storage
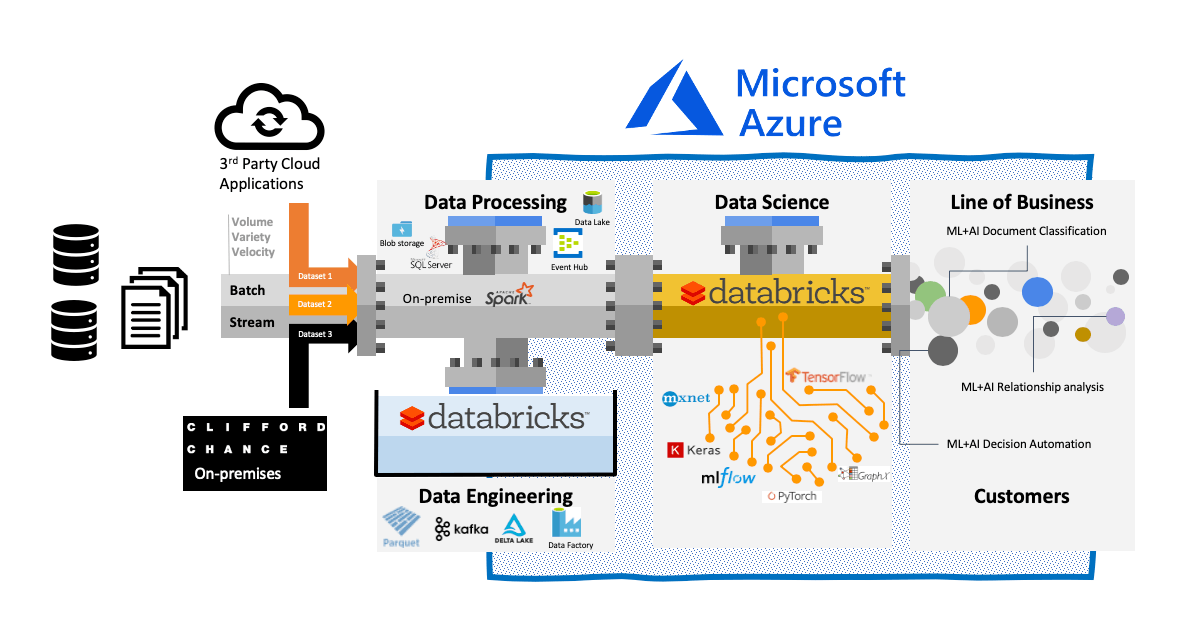
Data Science Lab data ingestion and elaboration architecture
An example use case: Document classification
In the legal sector, repapering documents is difficult and time consuming; it involves analysing large volumes of contracts, loans, or documents, and identifying which ones need to be updated. Having the ability to automatically label documents in these scenarios can significantly speed up many legal processes, especially when thousands or millions of documents are involved. To help automate this process, we decided to build a model.
First, we turned to the academic research around document classification, but to our surprise, we found that very little research had been done on classifying long documents. There were plenty of examples of text classification, but typically researchers had used short documents like movie reviews or Twitter posts. We quickly realized that long document classification was an area of study in which we could contribute to the academic research.
Next, we set about to create a model in the largely uncharted domain of long document classification. To build our model, we worked with the EDGAR dataset, which is an online public database from the U.S. Securities and Exchange Commission (SEC). EDGAR is the primary system that companies use to file financial information, like quarterly statements and audit documents, with the SEC.
The first step was to extract the documents from filings, find entries that were similar in size to our use case (more than 5,000 words), and extract only the relevant text. The process took multiple iterations to get a usable labelled dataset. We started from more than 15 million files and selected only 28,445 for creating our models.
Once we had extracted the documents we needed, we began to build our model, ultimately settling on a novel approach: applying chunk embedding inspired from audio segmentation. This involved dividing a long document into chunks, and mapping them to numeric space to achieve chunk embeddings. For more detail about this approach, you can read our published paper entitled Long-length Legal Document Classification. This was the first academic paper involving computer science and data science authored completely by a legal firm.
We ultimately settled on a multi-layered architecture for our model that benefited greatly from hyperparameter tuning. In addition to a long short-term memory (LSTM) neural network, we employed an attention mechanism to enable our model to assign different scores to different parts across the whole document. Throughout the entire architecture of the model, we used hyperparameter tuning, a vital tool that helped improve model performance, or decrease model training time. The hyperparameters that benefited from tuning the most included embedding dimensions, hidden layer size, batch size, learning rate, and weight decay.
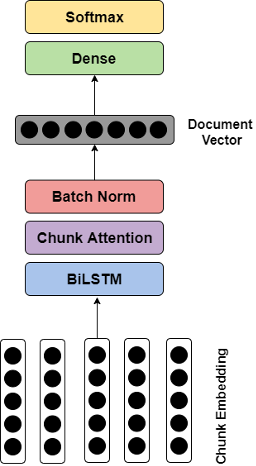
Model architecture
Although we were able to narrow down the values for each hyperparameter to a limited range of candidates, the total number of combinations was still massive. In this case, implementing a greedy search over the hyperparameter space was unrealistic, but here Hyperopt made life much easier. All we needed to do was to construct the objective function and define the hyperparameter search space, then Hyperopt got to work, quickly narrowing in on the best parameters. Meanwhile, we used MLflow to store all of the results generated during the hundreds of training runs, guaranteeing that no training data was lost.

t-SNE plot of projections of document embeddings, using Doc2Vec + BiLSTM
Conclusion
The Clifford Chance Data Science Lab team has been able to deliver end-user applications and cutting edge academic research despite having only a small team and limited resources. This has largely been made possible through the use of process automation, and powerful tools including Azure Cloud, Azure Databricks, MLflow and Hyperopt.
In the long document classification use case above, our final model achieved an F1 score greater than 0.98 with long-length documents. However, these results came only after significant tuning with Hyperopt, which increased our F1 score by more than 0.005 by the time it converged on the optimal parameters. Our final model has been put to good use in multiple projects where we are dealing with huge numbers of files that require classification.
Looking forward, we plan to further automate our processes to reduce the workload of managing product development. We are continuing to optimise our processes to add alerting and monitoring. We plan to produce more scientific papers and contribute to the MLflow and Hyperopt open source projects in the near future so we can share our specific use cases.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.