Operationalizing machine learning at scale with Databricks and Accenture
by Atish Ray and Nathan Buesgens
Guest blog by Atish Ray, Managing Director at Accenture Applied Intelligence and Nathan Buesgens, Manager, Accenture
While many machine learning pilots are successful, scaling and operating full blown applications to deliver business-critical outcomes remains a key challenge. Accenture and Databricks are partnering to overcome this, writes Atish Ray, Managing Director at Accenture Applied Intelligence, who specializes in big data and AI.
In 2019, machine learning (ML) applications and platforms attracted an average of $42 billion in funding worldwide. Despite this promise, scaling and operating full-blown ML applications remains a key challenge—especially in a business context, where many of the long-term benefits of industrialized ML are yet to be realized.
While ML is lauded for its ability to learn patterns of data, subsequently improving performance and outcomes based on experience, the barriers to scaling it are many and varied. For instance, a lack of good management of metadata end-to-end in an ML lifecycle could lead to fundamental issues around trust and traceability. The rapid evolution of skills and technologies required, and the potential incompatibility of traditional operating models and business processes, especially in IT, both pose hurdles in moving ML applications from pilot stage into production.
The good news is that recent advances in and availability of several AI and ML technologies have yielded the tools necessary to democratize and industrialize the lifecycle of an ML application. Increasing popularity and use of public cloud has enabled organizations to store and process more data at higher efficiency than ever before—a prerequisite for ML applications to scale and run most efficiently.
Innovations from open source communities supported by companies like Databricks have resulted in state-of-the-art products that allow scientists, engineers, and architects to collaborate together and rapidly build and deploy ML applications. And, what used to require a PhD in machine learning, has now been abstracted into a wide variety of software tools and services, which are democratized for use by a more diverse set of users.
Combine all of this with deep knowledge of an industry and its data, and it is clear there has never been a better time for organizations to deploy and operate ML at scale.
What makes the ML lifecycle a complex, collaborative process?
To monitor if ML delivers sustained outcomes to a business over a period of time, a deep understanding of the people, processes and technologies in each phase of the ML lifecycle is critical (Figure 1). From the outset, key stakeholders must be aligned on what exactly it is they need to achieve for the business.
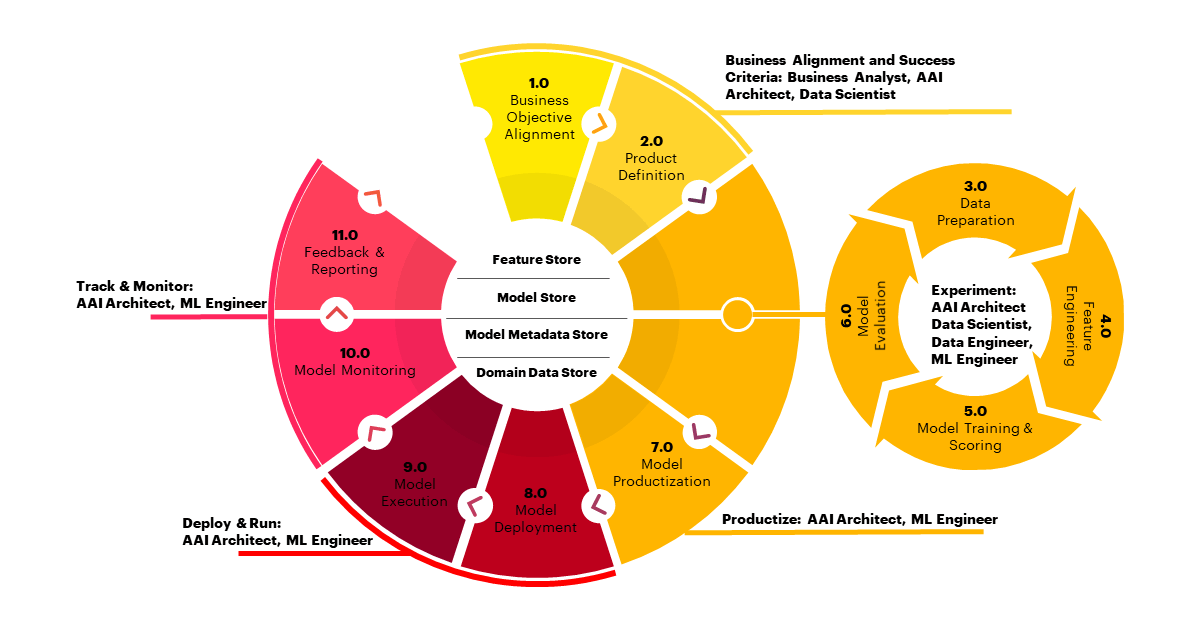
In a business context, one of the best practices is to begin by prioritizing one or two business challenges around which to build a minimum viable product or MVP supported by an initial foundation. Once this is established and the necessary data prepared, an experimentation phase takes place to determine the right model for any given problem.
After the model has been selected, tested, tuned and finalized, the ML application is ready to be operationalized. Traditionally, the work required to get to this point has been where data scientists focus the bulk of their time. However, in order to operationalize at scale, models may need to be deployed on certain platforms, such as cloud platforms, or integrated into user-facing business applications.
Once this is all complete, the next step is to monitor and tune the performance of these learning models as they're deployed into a production environment, where they are delivering specific outcomes such as making recommendations and predictions or monitoring certain types of operational efficiencies.
In one case, for example, an online ad agency in Japan was utilizing ML to create lists of target customers for ad delivery. They were successful in creating accurate models but were suffering from high operational cost of building models and evaluating the targeting outcomes. There was an urgent need to normalize and automate the process across measures.
To address this issue, Accenture implemented a reusable scripts tool to build, train, test and validate models. The scripts, which ran from a GUI frontend, were integrated with ML flow to enable deployment with ease, substantially reducing the DevOps time and effort needed to scale.
In another case, a large pharmaceutical retailer in the US was struggling to engage with its 80-million-plus member base through offers made with its loyalty program. It needed a way to increase uplift, yet apart from manual processes, there were no systems in place to build a reliable, uniform and reproducible ML pipeline to evaluate billions of combinations of offers for millions of customers on a continual basis.
Accenture developed and delivered a personalization engine with the Databricks platform to build, train, test, validate and deploy models at scale, across tens of millions of customers, billions of offers, and tens of thousands of products. An automated ML model deployment process and modernized AI pipeline were also deployed. The result was substantially reduced DevOps time and effort in deploying models, and the business was able to achieve an estimated 20% higher margin for pilot retail locations.
What are the technical building blocks for industrial ML?
Leveraging established building blocks by partnering with established experts—such as in the two cases outlined above—accelerates both the build and deployment of these types of programs, which can be iterated, incrementally scaled and applied to deliver increasingly complex business outcomes.
To help its clients build and operate these ML applications, Accenture has partnered with Databricks. Accenture is leveraging Databricks' platform to establish the key technical foundation needed to address three core areas of industrial ML: collaboration, data dependency and deployment (Figure 2).
Databricks' Unified Analytics Data Platform enables key technical components for each of the three fundamental areas, and Accenture has developed a set of additional technical components that co-exist and integrate with the Databricks platform. This also includes a package of reusable components, which accelerate collaboration, improve understanding of data and streamline operational deployments.
Ultimately, the objective of this partnership was to streamline the methodologies that have been proven successful for large-scale deployment.
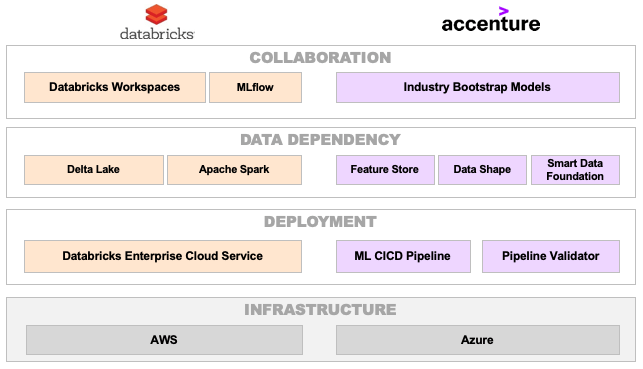
Based on extensive implementation experience, we know organizations that are industrializing ML development and deployment are addressing the three fundamental areas that we address here:
Collaboration
Comprehensive collaboration of analytics communities across organization boundaries, managing and sharing features and models, is key to success. As a collaborative environment, Databricks Workspaces provides a space in which data engineers and data scientists can jointly explore datasets, build models iteratively and execute experiments and data pipelines. MLflow is a key component and open source project from Databricks to collaborate across the ML lifecycle from experimentation to deployment and allows users to track model performance, versions and reproducible results.
Accenture brings a toolkit of models and feature engineering for many scenarios, for example a recommendation engine, that bootstraps the full ML application lifecycle. It leverages industry knowledge of successful models and enables baseline production feedback to inform calibration efforts.
Data dependency
We cannot emphasize enough the importance of access to and understanding of usable datasets and associated metadata for driving successful outcomes. Our data dependency components capture standards and rules to shape data, and provide visual charts to help assess data quality. This improves speed of data acquisition and curation, and further accelerates understanding of data and improves efficiencies of feature engineering.
The Databricks platform provides several capabilities to improve data quality and processing performance at scale. Delta Lake, available as part of Databricks, is an open source storage layer that enables ACID transactions and data quality features, and brings reliability to data lakes at scale. Apache Spark delivers a highly scalable engine for big data and ML, with additional enhancements from Databricks for high performance.
Deployment
Whereas experimentation requires data science knowledge to apply the right solutions to the right industry problem, deployment requires well integrated, cross-functional teams. Our deployment components use a metadata-driven approach to build and deploy ML pipelines representing continuous workflow from inception to validation. By enabling standards and deployment patterns, these components make it possible to operationalize experiments.
The Databricks Enterprise Cloud Service is a simple, secure and scalable managed service that enables consistent deployment of high-performing ML pipelines and applications. What's more, a governance structure for deployment and management of production models and drifts can also be enabled. Integrated together, these components from Databricks and Accenture deliver significant acceleration to the deployment of a ML lifecycle on AWS and Azure clouds.
What are the key considerations before deploying ML at scale?
For those considering an industrialized approach to ML, there are a few key questions to consider first. They include:
- Are business stakeholders aligned on the business problems ML needs to solve and the expectations on key outcomes it needs to achieve?
- Are the right roles and skills in place to scale and monitor the ML application for deploying a successful experimentation?
- Is the necessary infrastructure and automation needs understood and made available for an industrialized ML solution?
- Does the data science team have the right operating model, standards and enablers needed to avoid significant deployment re-engineering once experimentation is done?
When it comes to industrialized ML, it can be tempting to start by building a very deep technical foundation that addresses all aspects of the lifecycle. More often than not, however, that approach risks losing sight of business outcomes and encountering challenges with adoption, spend and justification of approach.
Instead, we have experienced successful iterative development of these foundations in a business-critical environment, built through successive cycles delivering incremental business outcomes.
About Accenture
Accenture is a leading global professional services company, providing a broad range of services and solutions in strategy, consulting, digital, technology and operations. Combining unmatched experience and specialized skills across more than 40 industries and all business functions – underpinned by the world's largest delivery network – Accenture works at the intersection of business and technology to help clients improve their performance and create sustainable value for their stakeholders. With more than 492,000 people serving clients in more than 120 countries, Accenture drives innovation to improve the way the world works and lives. Visit us at www.accenture.com.
This document is produced by consultants at Accenture as general guidance. It is not intended to provide specific advice on your circumstances. If you require advice or further details on any matters referred to, please contact your Accenture representative.
This document makes descriptive reference to trademarks that may be owned by others. The use of such trademarks herein is not an assertion of ownership of such trademarks by Accenture and is not intended to represent or imply the existence of an association between Accenture and the lawful owners of such trademarks.
Copyright © 2019 Accenture. All rights reserved. Accenture, its logo, and High Performance. Delivered. are trademarks of Accenture.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.