Glow 0.3.0 Introduces New Large-Scale Genomic Analysis Features
In October of last year, Databricks and the Regeneron Genetics Center® partnered together to introduce Project Glow, an open-source analysis tool aimed at empowering genetics researchers to work on genomics projects at the scale of millions of samples. Since we introduced Glow, we have been busy at work adding new high-quality algorithms, improving performance, and making Glow’s APIs easier to use. Glow 0.3.0 was released on February 21, 2020 and improves Glow’s power and ease of use in performing large-scale, high-throughput genomic analysis. In this blog, we highlight features and improvements introduced in the 0.3.0 release.
Python and Scala APIs for Glow SQL functions
In this release, native Python and Scala APIs were introduced for all Glow SQL functions, similar to what is available for Spark SQL functions. In addition to improved simplicity, this provides enhanced compile-time safety. The SQL functions and their Python and Scala clients are generated from the same source so any new functionality in the future will always appear in all three languages. Please refer to Glow PySpark Functions for more information on Python APIs for these functions. A code example showing Python and Scala APIs for the function normalize_variant is presented at the end of the next section.
Improved variant normalization
The variant normalizer received a major performance improvement in this release. It still behaves like bcftools norm and vt normalize, but is about 2.5x faster and has a more flexible API. Moreover, the new normalizer is implemented as a function in addition to a transformer.
normalize_variants transformer: The improved transformer preserves the columns of the input dataframe, adds the normalization status to the dataframe, and has the option of adding the normalization results (including the normalized coordinates and alleles) to the dataframe as a new column. To start, we use the following command to read the original_variants_df dataframe. Figure 1 shows the variants in this dataframe.
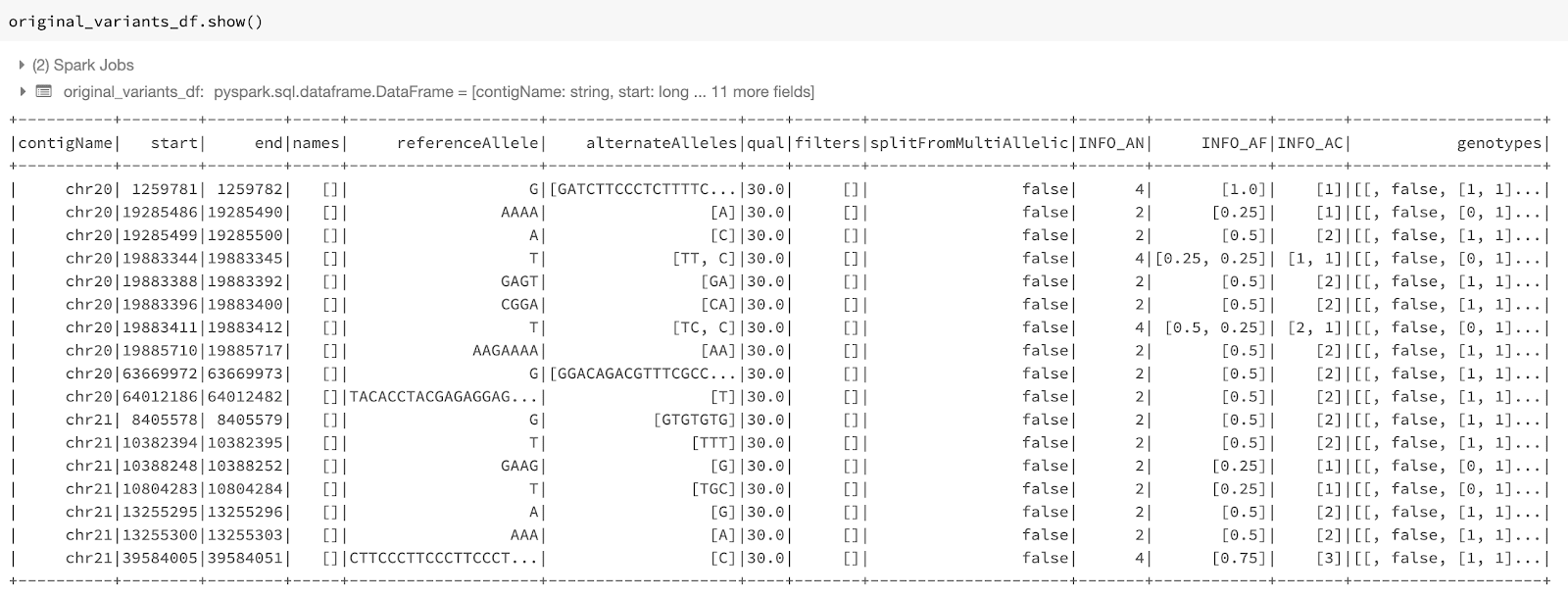
Figure 1: The variant dataframe original_variants_df
The improved normalizer transformer can be applied on this dataframe using the following command. This uses the transformer syntax used by the previous version of the normalizer:
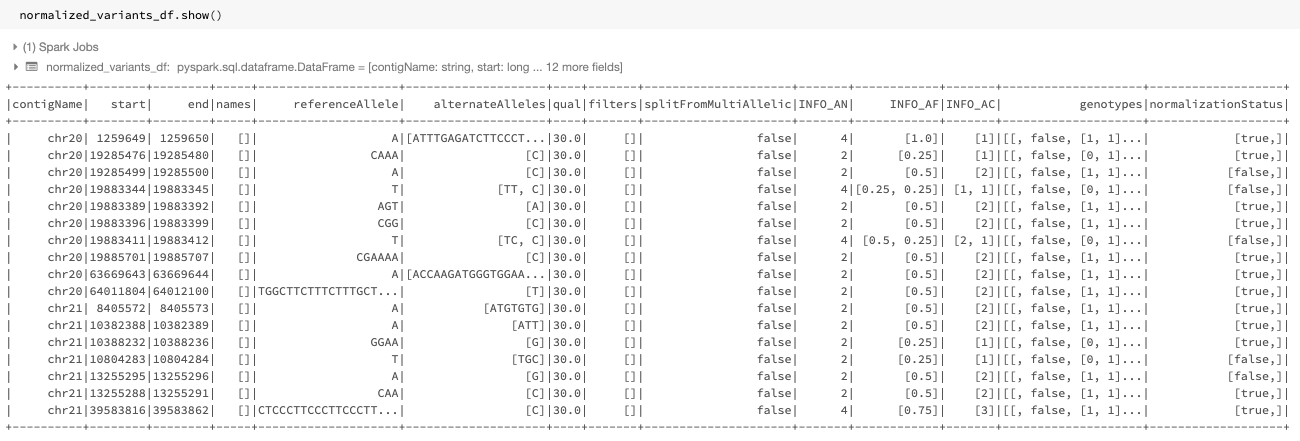
Figure 2: The normalized dataframe normalized_variants_df
Figure 2 shows the dataframe generated by the improved normalizer. The start, end, referenceAllele, and alternateAlleles fields are updated with the normalized values and a normalizationStatus column is added to the dataframe. This column contains a changed subfield that indicates whether normalization changed the variant, and an errorMessage subfield containing the error message, if an error occurred.
The newly introduced replace_columns option can be used to add the normalization results as a new column to the dataframe instead of replacing the original start, end, referenceAllele, and alternateAlleles fields:
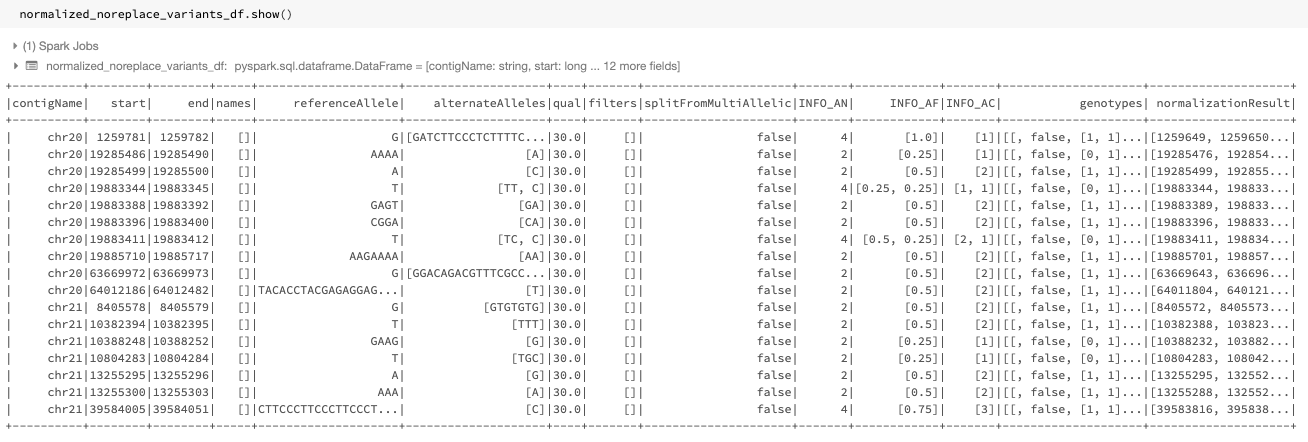
Figure 3: The normalized dataframe normalized_noreplace_variants_df with normalization results added as a new column
Figure 3 shows the resulting dataframe. A normalizationResults column is added to the dataframe. This column contains the normalization status, along with normalized start, end, referenceAllele, and alternateAlleles subfields.
Since the multiallelic variant splitter is implemented as a separate transformer in this release, the mode option of the normalize_variants transformer is deprecated. Refer to the Variant Normalization documentation for more details on the normalize_variants transformer.
normalize_variant function: As mentioned above, this release introduces the normalize_variant SQL expression:
As discussed in the previous section, this SQL expression function has Python and Scala APIs as well. Therefore, we can rewrite the previous code example as follows:
This example can also be easily ported to Scala:
The result of any of the above commands will be the same as Figure 3.
A new transformer for splitting multiallelic variants
This release also introduced a new dataframe transformer called split_multiallelics. This transformer splits multiallelic variants into biallelic variants, and behaves similarly to vt decompose with -s option. This behavior is more powerful than the behavior of the previous splitter, which behaved like GATK’s LeftAlignAndTrimVariants with --split-multi-allelics. In particular, the array-type INFO and genotype fields with elements corresponding to reference and alternate alleles are split into biallelic rows (see -s option of vt decompose). So are the array-type genotype fields with elements sorted in colex order of genotype calls, e.g., the GL, PL, and GP fields in the VCF format. Moreover, an OLD_MULTIALLELIC INFO field is added to the dataframe to store the original multiallelic form of the split variants.
The following is an example of using the split_multiallelic transformer on the original_variants_df. Figure 4 contains the result of this transformation.
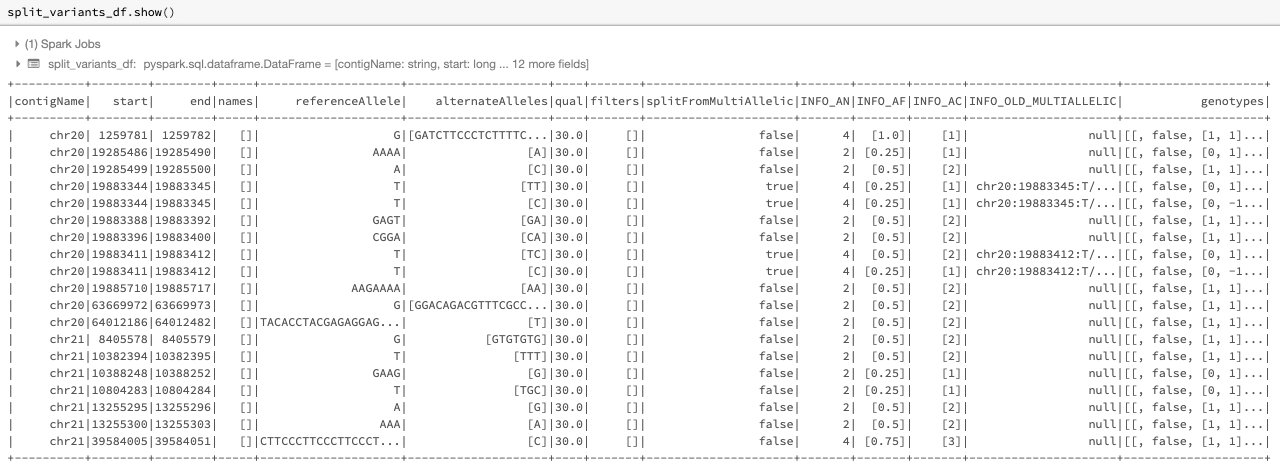
Figure 4: The split dataframe split_variants_df
Please note that the new splitter is implemented as a separate transformer from the normalize_variants transformer. Previously, splitting could only be done as one of the operation modes of the normalize_variants transformer using the now-deprecated mode option. Please refer to the documentation of the split_multiallelics transformer for complete details on the behavior of this new transformer.
Parsing of Annotation Fields
The VCF reader and pipe transformer now parse variant annotations from tools such as SnpEff and VEP. This flattens the ANN and CSQ INFO fields, which simplifies and accelerates queries on annotations. Figure 5 shows the output of the code below, which queries the annotated consequences in a VCF annotated using the LOFTEE VEP plugin.

Figure 5: The annotated dataframe annotated_variants_df with expanded subfields of the exploded INFO_CSQ
Other Data Analysis Improvements
Glow 0.3.0 also includes optimized implementations of the linear and logistic regression functions, resulting in ~50% performance improvements. See the documentation at Linear regression and Logistic regression.
Furthermore, the new release supports Scala 2.12 in addition to Scala 2.11. The Maven artifacts for both Scala versions are available on Maven Central.
Try Glow 3.0!
Glow 0.3 is installed in the Databricks Genomics Runtime (Azure | AWS) and is optimized for improved performance when using cloud computing to analyze large genomics datasets. Learn more about our genomics solutions and how we’re helping to further human and agricultural genome research and enable advances like population-scale next-generation sequencing in the Databricks Unified Analytics Platform for Genomics and try out a preview today.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.