Automate continuous integration and continuous delivery on Databricks using Databricks Labs CI/CD Templates
by Michael Shtelma and Thunder Shiviah
CONTENTS
- Overview
- Why do we need yet another deployment framework?
- Simplifying CI/CD on Databricks via reusable templates
- Development lifecycle using Databricks Deployments
- How to create and deploy a new data project with Databricks Labs CI/CD Templates in 10 minutes?
Overview
Databricks Labs continuous integration and continuous deployment (CI/CD) Templates are an open source tool that makes it easy for software development teams to use existing CI tooling with Databricks Jobs. Furthermore, it includes pipeline templates with Databricks’ best practices baked in that run on both Azure and AWS so developers can focus on writing code that matters instead of having to set up full testing, integration and deployment systems from scratch.
CI/CD Templates in 3 steps:
pip install cookiecuttercookiecutter https://github.com/databrickslabs/cicd-templates.git- Answer the interactive questions in the terminal such as which cloud you would like to use and you have a full working pipeline.
pip install databricks_cli && databricks configure --token- Start pipeline on Databricks by running
./run_pipeline.py pipelinesin your project main directory
- Add your databricks token and workspace URL to github secrets and commit your pipeline to a github repo.
Your Databricks Labs CI/CD pipeline will now automatically run tests against databricks whenever you make a new commit into the repo. When you are ready to deploy your code, make a github release and templates will automatically package and deploy your pipeline to databricks as a job.
That’s it! You now have a scalable working pipeline which your development team can use and develop off of. Additionally, you can always modify the template to be more specific to your team or use-case to ensure future projects can be set up with ease.
For the remainder of this post, we’ll go into depth about why we decided to create Databricks Labs CI/CD templates, what is planned for the future of the project, and how to contribute.
Why do we need yet another deployment framework?
As projects on Databricks grow larger, Databricks users may find themselves struggling to keep up with the numerous notebooks containing the ETL, data science experimentation, dashboards etc. While there are various short term workarounds such as using the %run command to call other notebooks from within your current notebook, it’s useful to follow traditional software engineering best practices of separating reusable code from pipelines calling that code. Additionally, building tests around your pipelines to verify that the pipelines are also working is another important step towards production-grade development processes.
Finally, being able to run jobs automatically upon new code changes without having to manually trigger the job or manually install libraries on clusters is important for achieving scalability and stability of your overall pipeline. In summary, to scale and stabilize our production pipelines, we want to move away from running code manually in a notebook and move towards automatically packaging, testing, and deploying our code using traditional software engineering tools such as IDEs and continuous integrationI tools.
Indeed, more and more data teams are using Databricks as a runtime for their workloads preferring to develop their pipelines using traditional software engineering practices: using IDEs, GIT and traditional CI/CD pipelines. These teams usually would like to cover their data processing logic with unit tests and perform integration tests after each change in their version control system.
The release process is also managed using a version control system: after a PR is merged into the release branch, integration tests can be performed and in a case of positive results deployment pipelines can be also updated. Bringing a new version of pipelines to production workspace is also a complex process since they can have different dependencies, like configuration artifacts, python and/or maven libraries and other dependencies. In most cases, different pipelines can depend on different versions of the same artifact(s).
Simplifying CI/CD on Databricks via reusable templates
Many organizations have invested many resources into building their own CI/CD pipelines for different projects. All those pipelines have a lot in common: basically they build, deploy and test some artifacts. In the past, developers were also investing long hours in developing different scripts for building, testing and deploying of applications before CI tools made most of those tasks obsolete: conventions introduced by CI tools made it possible to provide developers with the frameworks which can implement most of those tasks in an abstract way so that they can be applied to any project which follows these conventions. For example Maven has introduced such conventions in Java development, which made it possible to automate most of the build process, which were implemented in huge ant scripts.
Databricks Labs CI/CD Templates makes it easy to use existing CI/CD tooling, such as Jenkins, with Databricks; Templates contain pre-made code pipelines created according to Databricks best practices. Furthermore, Templates allow teams to package up their CI/CD pipelines into reusable code to ease the creation and deployment of future projects. Databricks Labs CI/CD Templates introduces similar conventions for Data Engineering and Data Science projects which provide data practitioners using Databricks with abstract tools for implementing CI/CD pipelines for their data applications.
Let us go deeper into the conventions we have introduced. Most of the data processing logic including data transformations, feature generation logic, model training, etc should be developed in the python package. This logic can be utilized in a number of production pipelines that can be scheduled as jobs. The aforementioned logic can be also tested using local unit tests that test individual transformation functions and integration tests. Integration tests are run on Databricks workspace and can test the data pipelines as a whole.
Development lifecycle using Databricks Deployments
Data Engineers and Data Scientists can rely on Databricks Labs CI/CD Templates for testing and deploying the code they develop in their IDEs locally in Databricks. Databricks Labs CI/CD Templates provides users with the reusable data project template that can be used to jumpstart the development of a new data use case. This project will have the following structure:
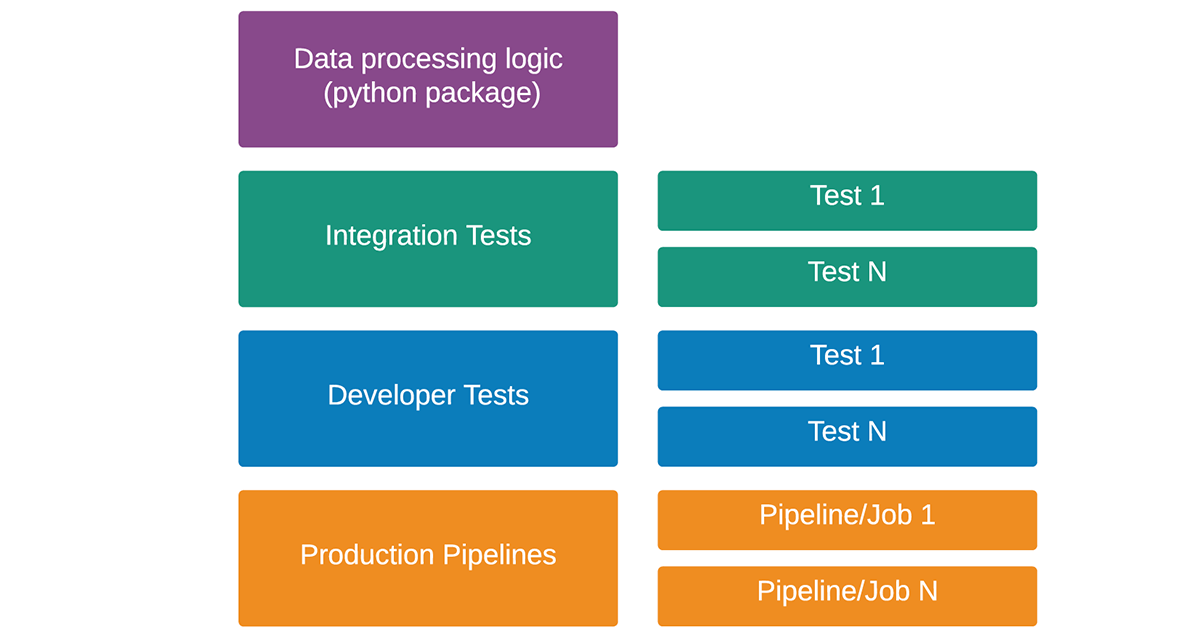
Data ingestion, validation, and transformation logic, together with feature engineering and machine learning models, can be developed in the python package. This logic can be utilized by production pipelines and be tested using developer and integration tests. Databricks Labs CI/CD Templates can deploy production pipelines as Databricks Jobs, including all dependencies, automatically. These pipelines must be placed in the ‘pipelines’ directory and can have their own set of dependencies, including different libraries and configuration artifacts. Developers can utilize a local mode of Apache Spark or Databricks Connect to test the code while developing in IDE installed on their laptop. In case they would like to run these pipelines on Databricks, they can use the Databricks Labs CI/CD Templates CLI. Developers can also utilize the CLI to kick off integration tests for the current state of the project on Databricks.
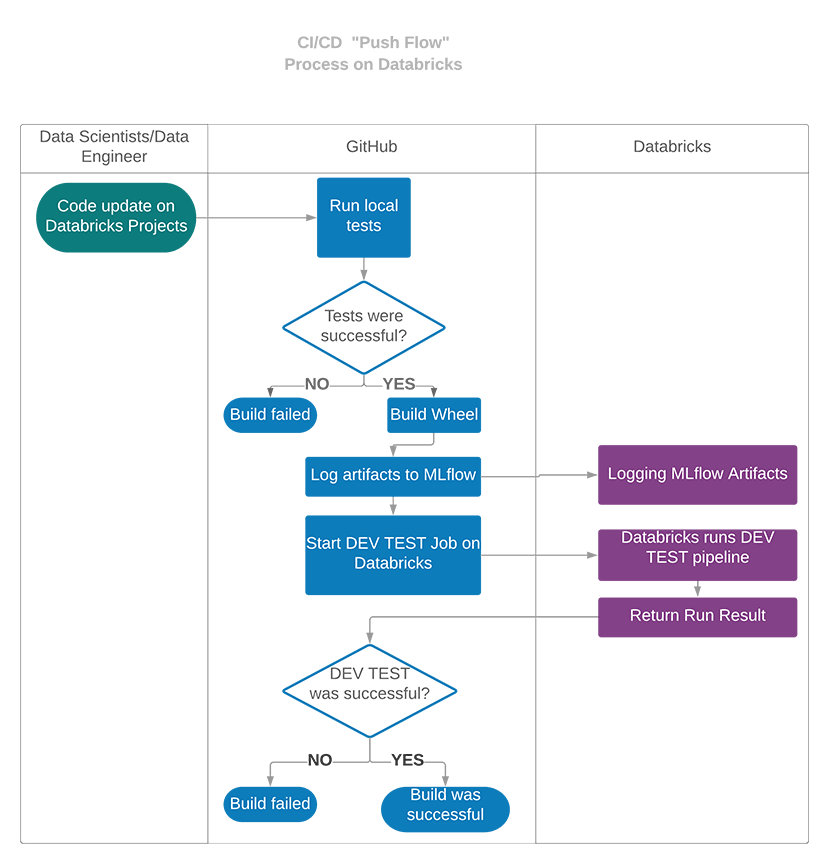
After that, users can push changes to GitHub, where they will be automatically tested on Databricks using GitHub Actions configuration. After each push, GitHub Actions starts a VM that checks out the code of the project and runs the local pytest tests in this VM. If these tests were successful, it will build the python wheel and deploy it along all other dependencies to Databricks and run developer tests on Databricks.
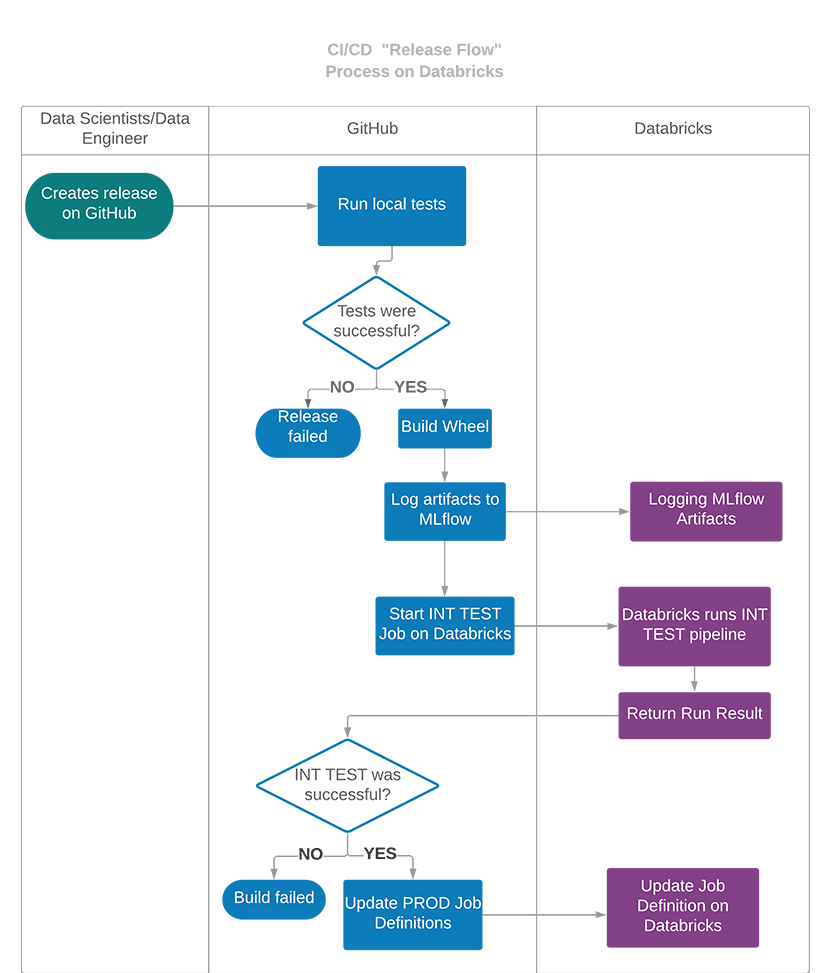
At the end of the development cycle, the whole project can be deployed to production by creating a GitHub release, which will kick off integration tests in Databricks and deployment of production pipelines as Databricks Jobs. In this case the CI/CD pipeline will look similarly to the previous one, but instead of developer tests, integration tests will be run on Databricks and if they are successful, the production job specification on Databricks will be updated.
How to create and deploy a new data project with Databricks Labs CI/CD Templates in 10 minutes?
Create a new project using the Databricks Labs CI/CD Templates project template
- Install Cookiecutter python package:
pip install cookiecutter - Create your project using our cookiecutter template:
cookiecutter https://github.com/databrickslabs/cicd-templates.git - Answer the questions…
After that, the new project will be created for you. It will have the following structure:
The name of the project we have created is ‘cicd_demo’, so the python package name is also ‘cicd_demo’, so our transformation logic will be developed in the ‘cicd_demo’ directory. It can be used from the pipelines that will be placed in ‘pipelines’ directory. In ‘pipelines’ directory we can develop a number of pipelines, each of them in its own directory.
Each pipeline must have an entry point python script, which must be named ‘pipeline_runner.py’. In this project, we can see two sample pipelines created. Each of these pipelines has python script and job specification json file for each supported cloud. These files can be used to define cluster specification (e.g., number of nodes, instance type, etc.), job scheduling settings, etc.
‘Dev-tests’ and ‘integration-tests’ directories are used to define integration tests that test pipelines in Databricks. They should also utilize the logic developed in the python package and evaluate the results of the transformations.
Let’s deploy our project to target Databricks workspace
Databricks Deployments is tightly integrated with GitHub Actions. We will need to create a new GitHub repository where we can push our code and where we can utilize GitHub Actions to test and deploy our pipelines automatically. In order to integrate GitHub repository with the Databricks workspace, workspace URL and Personal Authentication token (PAT) must be configured as GitHub secrets. Workspace URL must be configured as DATABRICKS_HOST secret and token as DATABRICKS_TOKEN.
Now we can initialize a new git repository in the project directory. After that, we can add all files to git and push them to the remote GitHub repository. After we have configured our tokens and proceeded with our first push GitHub Actions will run dev-test automatically on target Databricks Workspace and our first commit will be marked green if the tests are successful.
It is possible to initiate run of production pipelines or individual tests on Databricks from the local environment by running run_pipeline.py script:
This command will run test_pipeline from the pipelines folder on Databricks.
Test Automation using Databricks Deployments
The newly created projects are preconfigured with two standard CI/CD pipelines: one of them is executed for each push and runs dev-tests on Databricks workspace.
Another one is run for each created GitHub release and runs integration-tests on Databricks workspace. In the case of a positive result of integration tests, the production pipelines are deployed as jobs to the Databricks workspace.
Deploying production pipelines using Databricks Deployments
In order to deploy pipelines to production workspace, GitHub release can be created. It will automatically start integration tests and if they are positive, the production pipelines are deployed as jobs to the Databricks workspace. During the first run, the jobs will be created in Databricks workspace. During the subsequent release, the definition of existing jobs will be updated.
Dependency and configuration management
Databricks Deployments supports dependency management on two levels:
- Project level:
- project level python package dependencies, which are needed during production runtime, can be placed in runtime_requiremnets.txt
- It is also possible to use project level JAR or Python Whl dependencies. They can be placed in dependencies/jars and dependencies/wheels directories.
- Pipeline dependencies:
- Pipeline level python/maven/other dependencies can be specified in job specification json directly in libraries section
- Jars and wheels can be placed in dependencies/jars and dependencies/wheels directories respectively in pipeline folder
Configuration files can be placed in the pipeline directory. They will be logged to MLflow together with python script. During execution in Databricks the job script will receive the path to the pipeline folder as first parameter. This parameter can be used to open any files that were present in the pipeline directory.
Let’s discuss how we can manage dependencies using Databricks Deployments using the following example:
This pipeline has two dependencies on pipeline level: one jar file and one wheel. Train_config.yaml file contains configuration parameters that pipeline can read using the following code:
Outlook and next steps
There are different directions of the further development of Databricks Deployments. We are thinking of extending a set of CI/CD tools we provide the templates for. As of now it is just GitHub Actions, but we can add a template that integrates with CircleCI or Azure DevOps.
Another direction can be supporting development of pipelines developed in Scala.
How to contribute?
Databricks Labs CI/CD Templates is an open source tool and we happily welcome contributions to it. You are welcome to submit a PR!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.