MLflow Joins the Linux Foundation to Become the Open Standard for Machine Learning Platforms

Watch Spark + AI Summit Keynotes here
At today's Spark + AI Summit 2020, we announced that MLflow is becoming a Linux Foundation project.
Two years ago, we launched MLflow, an open source machine learning platform to let teams reliably build and productionize ML applications. Since then, we have been humbled and excited by the adoption of the data science community. With more than 2.5 million monthly downloads, 200 contributors from 100 organizations, and 4x year-on-year growth, MLflow has become the most widely used open source ML platform, demonstrating the benefits of an open platform to manage ML development that works across diverse ML libraries, languages, and cloud and on-premise environments.
Together with the community, we intend to keep growing MLflow. Thus, we're happy to announce that we’ve moved MLflow into the Linux Foundation as a vendor-neutral non-profit organization to manage the project long-term. We are excited to see how this will bring even more contributions to MLflow.
At Databricks, we're also doubling down on our investment in MLflow. At Spark+AI Summit we talked about three ongoing efforts to further simplify the machine learning lifecycle: autologging, model governance and model deployment.
Autologging: data versioning and reproducibility
MLflow already has the ability to track metrics, parameters and artifacts as part of experiments. You can manually declare each element to record, or simply use the autologging capability to log all this information with just one line of code for the supported libraries. Since introducing this feature last year, we've seen rapid adoption of autologging, so we're excited to extend the capabilities of this feature.
One of the biggest challenges machine learning practitioners face is how to keep track of intermediate data sets (training and testing) used during model training. Therefore, we introduced autologging for Apache Spark data sources in MLflow 1.8, our first step into data versioning with MLflow. This means that if you're using Spark to create your features or training pipelines, you can turn on Spark autologging and automatically record exactly which data was queried for your model.
And if you're using Delta Lake — which supports table versioning and traveling back in time to see an old version of the data — we also record exactly which version number was used. This means that if you're training a model based on a Delta table and use Spark autologging, MLflow automatically records which version of the data was used. This information can be useful for debugging your models or reproducing a previous result.
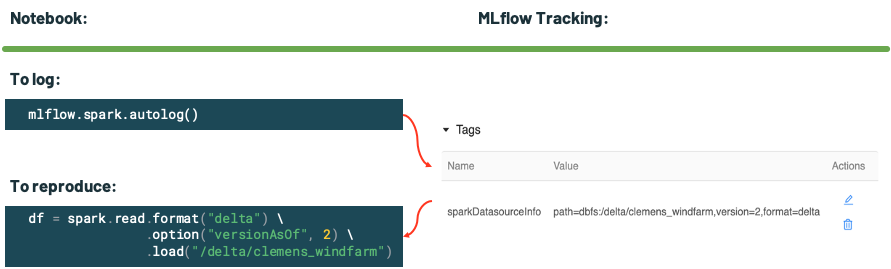
Figure 1: MLflow 1.8 introduced autologging from Spark data sources including Delta table versions
Autologging currently supports six libraries: TensorFlow, Keras, Gluon, LightGBM, XGBoost and Spark. There is also ongoing work from Facebook to add support for PyTorch soon, and from Databricks to add support for scikit-learn.
For users of the Databricks platform, we’re also integrating autologging with the cluster management and environment features in Databricks. This means that if you’re tracking your experiments on Databricks — from a notebook or a job — we will automatically record the snapshot of the notebook that you used, the cluster configuration, and the full list of library dependencies.
This will allow you and your peers to quickly recreate the same conditions from when the run was originally logged. Databricks will clone the exact snapshot of the Notebook, create a new cluster with the original cluster specification, and install all library dependencies needed. This makes it easier than ever to pick up from a previous run and iterate on it, or to reproduce a result from a colleague.
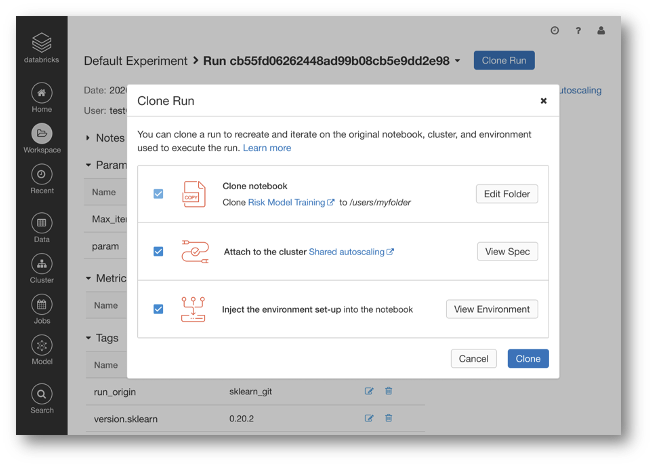
Figure 2: MLflow supports reproducibility by allowing data teams to replicate a run based on the auto-logged notebook snapshot, cluster configuration, and library dependencies on Databricks.
Stronger model governance with model schemas and MLflow Model Registry tags
Once you've logged your experiments and have produced a model, MLflow provides the ability to register your model into one centralized repository - the MLflow Model Registry - for model management and governance. The MLflow Model Registry rate of adoption is growing exponentially and we're seeing hundreds of thousands of models being registered on Databricks every week. We're excited to add more features to strengthen model governance with the Model Registry.
One of the most common pain points when deploying models is making sure that the schema for production data used to score your models is compatible to the schema of data used when training the model, and that the output from a new model version is what you expect in production. Therefore, we're extending the MLflow model format to include support for model schemas, which will store the features and predictions requirements for your models (inputs/outputs names and data types). One of the most common sources of production outages in ML is a mismatch of model schemas when a new model is deployed. With the integration of the model schema and the model registry, MLflow will allow you to compare model versions and their schemas, and alert you if there are incompatibilities.
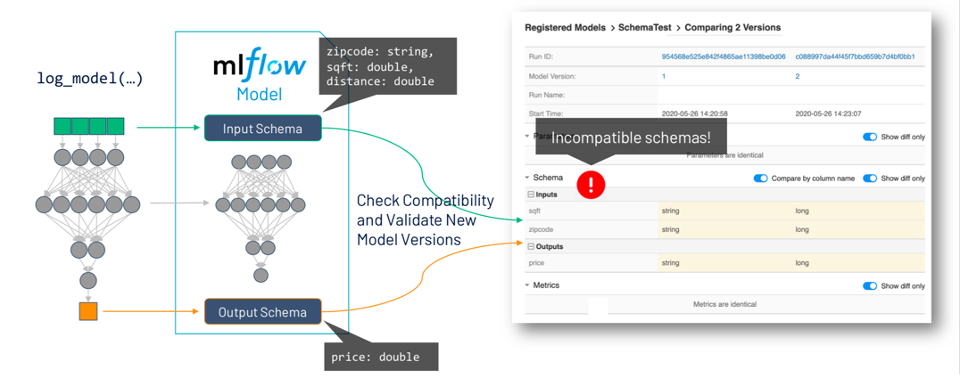
Figure 3: With built-in model schemas compatibility checking, MLflow Model Registry eliminates the possibility for mismatched model schemas --one of the biggest sources of ML production outages.
To make custom model management workflows easier and more automated, we're introducing custom tags as part of the MLflow Model Registry.
Many organizations have custom internal processes for validating models. For example, models may have to pass legal review for GDPR compliance or pass a performance test before deploying them to edge devices. Custom tags allow you to add your own metadata for these models and keep track of their state. This capability is also provided through APIs so you can run automatic CI/CD pipelines that test your models, add these tags, and make it very easy to check whether your model is ready for deployment.

Figure 4: The introduction of custom tags in MLflow Model Registry makes it easier for data teams to validate and monitor the state of their models.
Accelerating model deployment with simplified API and model serving on Databricks
MLflow already has integrations with several model deployment options, including batch or real-time serving platforms. Because we've seen an increasing number of contributions in this space, we wanted to provide the community with a simpler API to manage model deployment.
The new Deployments API for managing and creating deployment endpoints will give you the same commands to deploy to a variety of environments, removing the need to write custom code for the individual specifications of each. This is already being used to develop two new endpoints for RedisAI and Google Cloud Platform, and we are working on porting a lot of the past integrations (including Kubernetes, SageMaker and AzureML) to this API. This will give you a simple and uniform way to manage deployments and to push the models to different serving platforms as needed.
mlflow deployments create -t gcp -n spam -m models:/spam/production
mlflow deployments predict -t gcp –n spam -f emails.json
Finally, for Databricks customers, we are excited to announce that we've integrated Model Serving as a turnkey solution on Databricks.
Setting up environments to serve ML models as REST endpoints can be cumbersome and require significant integration work. With this new capability Databricks streamlines the process of taking models from experimentation to production. While this service is in preview, we recommend its use for low throughput and non-critical applications.
https://www.youtube.com/watch?v=RPIDdmYYY8s
Figure 5: MLflow’s integrated Model Serving solution streamlines the process of taking models from experimentation to production.
Next Steps
You can watch the official announcement and demo by Matei Zaharia and Sue Ann Hong at Spark + AI Summit:
Ready to get started with MLflow? You can read more about MLflow and how to use it on AWS or Azure. Or you can try an example notebook [AWS] [Azure]
If you are new to MLflow, read the open source MLflow quickstart with the lastest MLflow 1.9 to get started with your first MLflow project. For production use cases, read about Managed MLflow on Databricks and get started on using the MLflow Model Registry.

