Allow Simple Cluster Creation with Full Admin Control Using Cluster Policies
by Greg Wood and Rebecca Li
What is a Databricks cluster policy?
A Databricks cluster policy is a template that restricts the way users interact with cluster configuration. Today, any user with cluster creation permissions is able to launch an Apache Spark™ cluster with any configuration. This leads to a few issues:
- Administrators are forced to choose between control and flexibility. We often see clusters being managed centrally, with all non-admins being stripped of cluster creation privileges; this provides acceptable control over the environment, but creates bottlenecks for user productivity. The alternative—allowing free reign to all users— can lead to problems like runaway costs and an explosion of cluster types across the enterprise.
- Users are forced to choose their own configuration, even when they may not need or want to. For many users, the number of options when creating a new cluster can be overwhelming—many users just want to create a small, basic cluster for prototyping, or to recreate a cluster that someone else has already configured. In these cases, more options is not better.
- Standardization of configurations—for the purpose of things such as tagging, chargeback, user onboarding, and replicability across environments—is often manual. These can mostly be accomplished via API workarounds, but they are not well-integrated.
To help solve these problems, we are introducing cluster policies to allow the creation of reusable, admin-defined cluster templates. These will control what a user can see and select when creating a cluster, and can be centrally managed and controlled via group or user privileges. We see two broad areas of benefit: increasing the ability of admins to balance control and flexibility, and simplifying the user experience for non-admins.
How do cluster policies help admins balance admin control and user flexibility?
While admins have historically had to choose between control and flexibility in designing usage patterns within Databricks, cluster policies will allow coexistence of both. By defining a set of templates that can be assigned to specific users or groups, admins can meet organizational guidelines on usage and governance without hampering the agility of an ad-hoc cluster model. To this end, policies will allow some of the most common patterns to be replicated and enforced automatically:
- Maximum DBU burndown per cluster per hour can be enforced to prevent users from spinning up overly large or expensive clusters
- Tagging of clusters can be mandated to enable chargeback/showback based on AWS resource tags
- Instance types and number of instances can be controlled via whitelisting, range specification, and even regular expressions, providing fine-grained controls over the type and size of clusters created
- Cluster type can be restricted to ensure users run jobs only on job clusters instead of all-purpose clusters
More complex templates- such as enforcing passthrough, enabling an external metastore, etc., can also provide a reusable framework; instead of struggling with a complex configuration every time a cluster is created, it can be done once and then applied to new clusters repeatedly. All of this combines to provide better visibility, control, and governance to Databricks administrators and Cloud Ops teams, without taking away from the flexibility and agility that makes Databricks valuable to so many of our customers.
How do cluster policies help simplify the experience of non-admin users?
As a user of Databricks today, I need to make several choices when creating a cluster, such as what instance type and size to use for both my driver and worker nodes, how many instances to include, the version of Databricks Runtime, autoscaling parameters, etc. While some users may find these options helpful and necessary, a majority of users need to make only basic choices when creating a cluster, such as choosing small, medium or large. The advanced options might be unnecessarily overwhelming to non-sophisticated users. Cluster policies will let such users pick a basic policy (such as “small”), provide a cluster name, and get directly to their notebook. For example, instead of the full create cluster screen all users see today, a minimal policy might look like this:
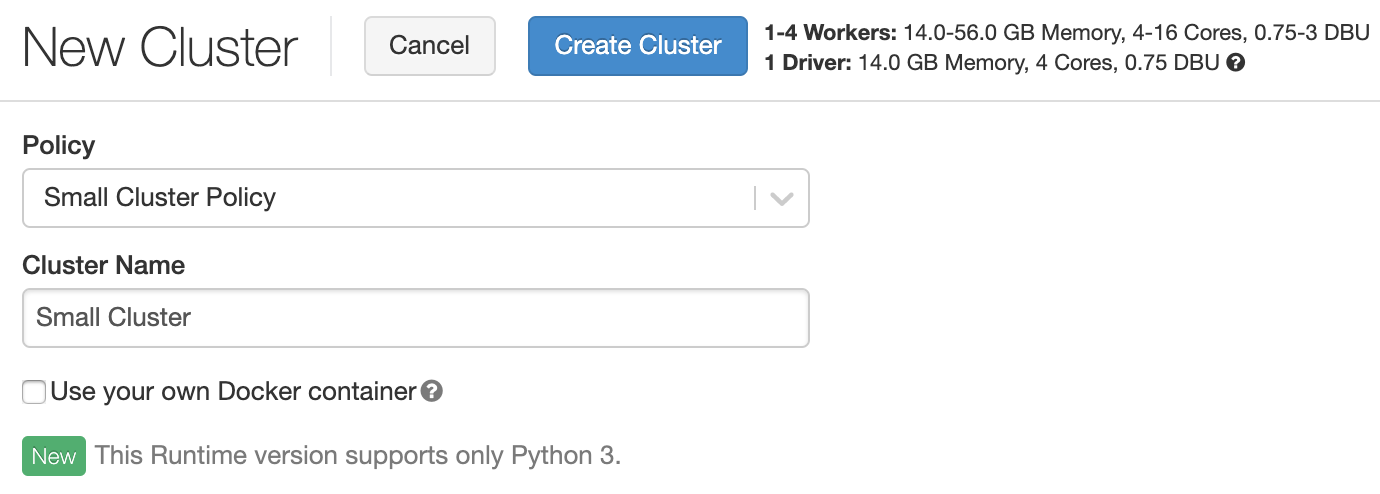
This is especially useful for users who may be new to the cloud computing world, or who are unfamiliar with Apache SparkTM; they can now rely on templates provided to them, instead of guessing. More advanced users might require additional options, for which policies could be created and assigned to specific users or groups. Policies are flexible enough to allow many levels of granularity, so that data science or data engineering teams can see the exact level of detail that they need to, without additional complexity that causes confusion and slows productivity.
What are some examples of cluster policies?
Although cluster policies will continue to evolve as we add more endpoints and interfaces, we have already taken some of the best practices from the field and formed them into a starting point to build upon. Some examples of these templates include:
- Small/Medium/Large “t-shirt size” clusters: minimal clusters that require little to no configuration by the user; we use a standard i3.2xlarge node type with auto-scaling and auto-termination enforced. Users only need to provide a cluster name.
- Max DBU count: allow all of the parameters of the cluster to be modified, but provide a limit (i.e., 50 DBUs per hour) to prevent users from creating an excessively large or expensive cluster
- Single-Node machine learning (ML) Clusters: limit runtime to Databricks ML Runtimes, enforce 1 driver and 0 workers, and provide options for either GPU or CPU machines acceptable for ML workloads
- Jobs-only clusters: users can only create a jobs cluster and run Databricks jobs using this policy, and cannot create shared, all-purpose clusters
These are a small sample of the many different types of templates that are possible with cluster policies.
General Cluster Policy
DESCRIPTION: this is a general purpose cluster policy meant to guide users and restrict some functionality, while requiring tags, restricting maximum number of instances, and enforcing timeout.
Note: For Azure users, “node_type_id” and “driver_node_type_id” need to be Azure supported VMs instead.
Simple Medium-Sized Policy
DESCRIPTION: this policy allows users to create a medium Databricks cluster with minimal configuration. The only required field at creation time is cluster name; the rest is fixed and hidden.
Note: For Azure users, “node_type_id” and “driver_node_type_id” need to be Azure supported VMs instead.
Job-Only Policy
DESCRIPTION: this policy only allows users to create Databricks job (automated) clusters and run jobs using the cluster. Users cannot create an all-purpose (interactive) cluster using this policy.
Note: For Azure users, “node_type_id” and “driver_node_type_id” need to be Azure supported VMs instead.
High Concurrency Passthrough policy
DESCRIPTION: this policy allows users to create clusters that have passthrough enabled by default, in high concurrency mode. This simplifies setup for the admin, since users would need to set the appropriate Spark parameters manually.
External Metastore policy
DESCRIPTION: this policy allows users to create a Databricks cluster with an admin-defined metastore already attached. This is useful to allow users to create their own clusters without requiring additional configuration.
How can I get started?
You need to be on Databricks Premium Tier (Azure Databricks or AWS) and plus (see pricing details) to use cluster policies.
As a Databricks admin, you can go to the “Clusters” page, the “Cluster Policies” tab to create your policies in the policy JSON editor. Alternatively, you can create policies via API. See details in Databricks documentation - Cluster Policies (AWS, Azure).
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.