Spark + AI Summit Reflections
by Jules Damji
Developers attending a conference have high expectations: what knowledge gaps they’ll fill; what innovative ideas or inspirational thoughts they’ll take away; who to contact for technical questions, during and after the conference; what technical trends are emerging in their domain of expertise; what serendipitous connections they’ll make and foster; and what theme will resonate across the conference content.
As developer advocates, we offer a developer’s perspective by reflecting on Spark + AI Summit 2020, held June 22–26 with nearly 70K registrants from 125+ countries.
As part of a data team of data engineers, scientists, architects and analysts, you’ll want to get to the heart of the matter. So let’s consider keynotes first.
Technical keynotes
Setting the overarching narrative of the conference, Ali Ghodsi, CEO and co-founder of Databricks, asserted why, more than ever, data teams must come together. By citing the social and health crises facing the world today, he elaborated on how data teams in organizations have embraced the idea of Data + AI as a team sport that heeds a clarion call: unlock the power of data and machine learning. This unifying theme resounded across products and open-source project announcements, training courses and many sessions.
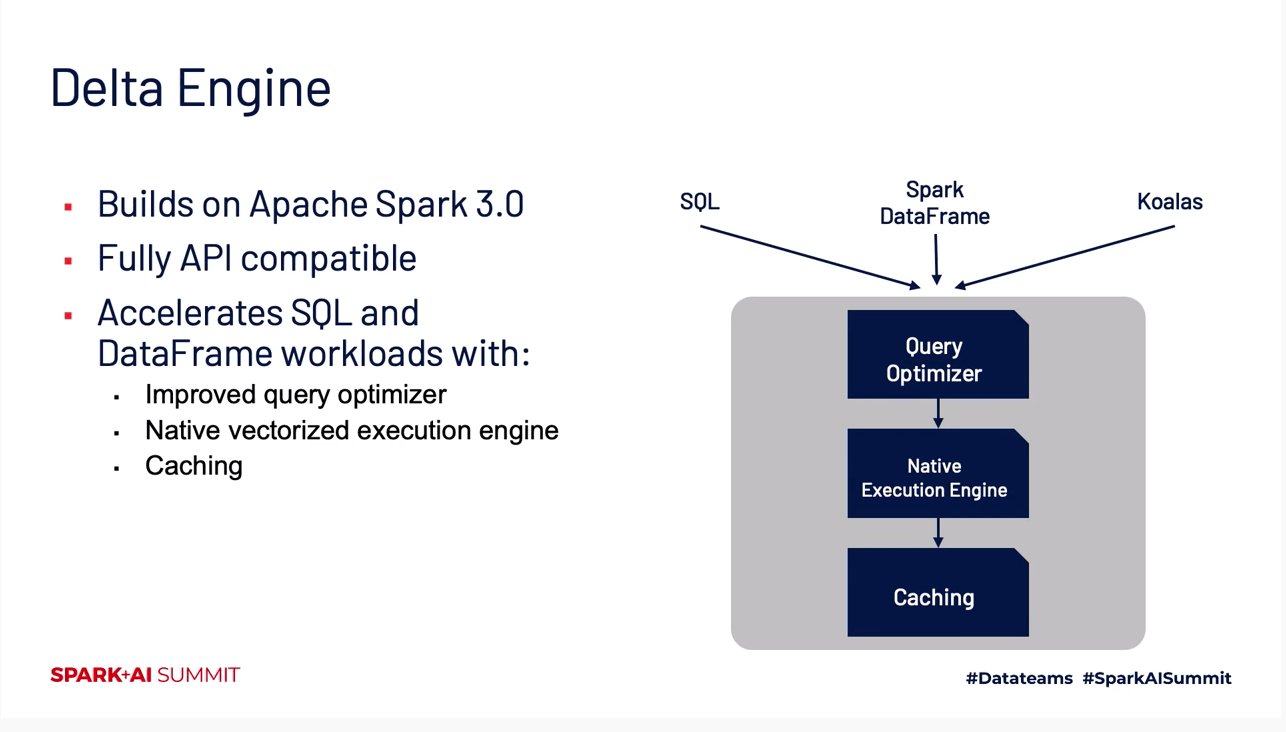
We developers are enthralled to technical details: We expect to see architectural diagrams, an under-the-hood glimpse, code, notebooks and demos. We ensure that we’ve got all the technical details on what, why and how Lakehouse, a new data paradigm built atop Delta Lake and compatible with Apache Spark 3.0, allows data engineers and data scientists to amass oceans of structured, semi-structured and unstructured data for a myriad of use cases. All the historical issues attributed to data lakes, noted Ghodsi, are now addressed by this “opinionated” standard for building reliable Delta Lakes. At length, we got an under-the-hood view of how Delta Lake provides a transactional layer for processing your data.

Adding to the conversation about how the Lakehouse stack of technologies helps data teams tackle tough data problems, Reynold Xin, chief architect and co-founder of Databricks, delivered a deep dive of a new component called Delta Engine. Built on top of Apache Spark 3.0 and compatible with its APIs, the Delta Engine affords developers on the Databricks platform “massive performance” when using DataFrame APIs and SQL workloads in three primary ways:
- Extends cost-based query optimizer and adaptive query execution with advanced statistics
- Adds a native vectorized execution engine written in C++ called Photon
- Implements caching mechanisms for high IO throughput for the Delta Lake storage layer
Though no developer APIs exist for this engine, it offers under-the-hood acceleration of Spark workloads running on Databricks. However, for developers using SQL, Spark DataFrames or Koalas on Databricks, it’s good news. Photon is a native-execution engine purpose-built for performance; it capitalizes on data-level and CPU instructions-level parallelism, taking advantage of modern hardware. Written in C++, it optimizes modern workloads that comprise mainly of string processing and regular expressions.
In a similar technical format and through the lens of one of the original creators of Apache Spark, Matei Zaharia, we journeyed through 10 years of Apache Spark. Zaharia explained how Spark improved with each release — incorporating feedback from its early users and developers; adopting new use cases and workloads, such as accelerating R and SQL interactive queries and incremental data set updates for streaming; expanding access to Spark with programming languages, machine learning libraries, and high-level, structured APIs — and always kept developers’ needs front and center for Spark’s ease of use in its APIs.

Zaharia’s key takeaways for developers as it relates to Apache Spark 3.0 include:
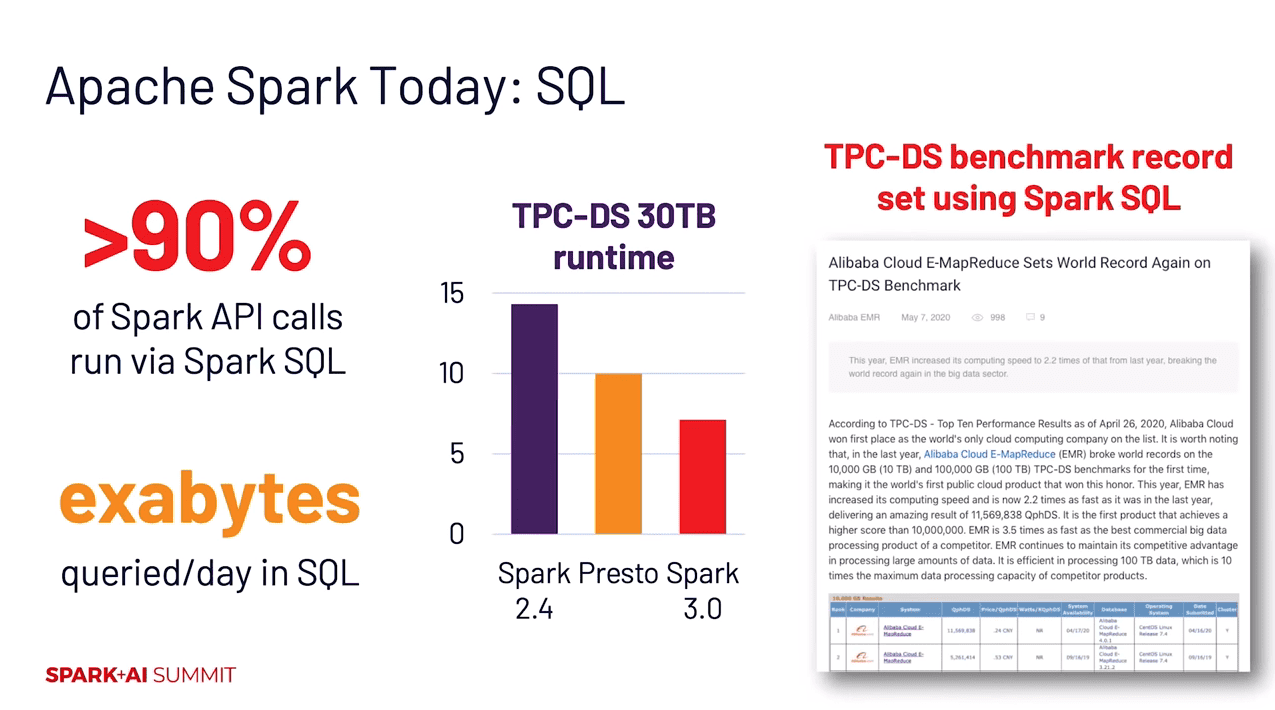
- Significant performance improvements under the hood for Spark SQL (Adaptive Query Execution and Dynamic Partitioning Pruning)
- ANSI SQL compliance
- Notable improvements in usability for Python and PySpark and a new Python Project Zen
- An impressive 3,400 Jira issues resolved (with 46% toward Spark SQL)
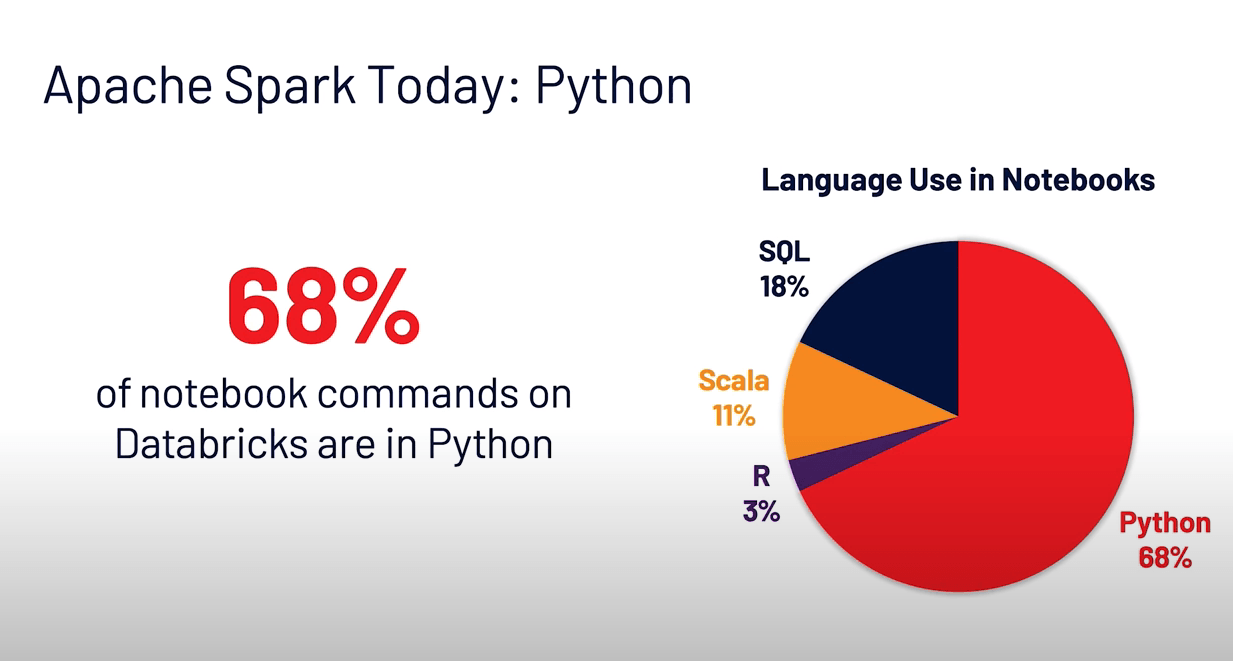
One salient observation that Zaharia noted: 68% of commands in the Databricks notebooks developers issue are in Python and 18% in SQL, with Scala trailing at 11%. This observation is fitting with Spark 3.0’s emphasis on Spark SQL and Python enhancements.
All these were not just a litany of slides; we saw code, pull requests, stacktraces, notebooks, tangible code with performance improvements, demos, etc.
Even better, you can download Spark 3.0, get a complimentary copy of “Learning Spark, 2nd Edition,” and start using the latest features today!
Data visualization narrates a story. Redash joining Databricks brings a new set of data visualization capabilities. For data analysts more fluent in SQL than Python, it affords them the ability to explore, query, visualize dashboards, and share data from many data sources, including Delta Lakes. You can see how you can augment data visualization with Redash.
As an open-source project, with over 300 contributors and 7,000 deployments, the Redash acquisition reaffirms Databricks’ commitment to the open-source developer community.
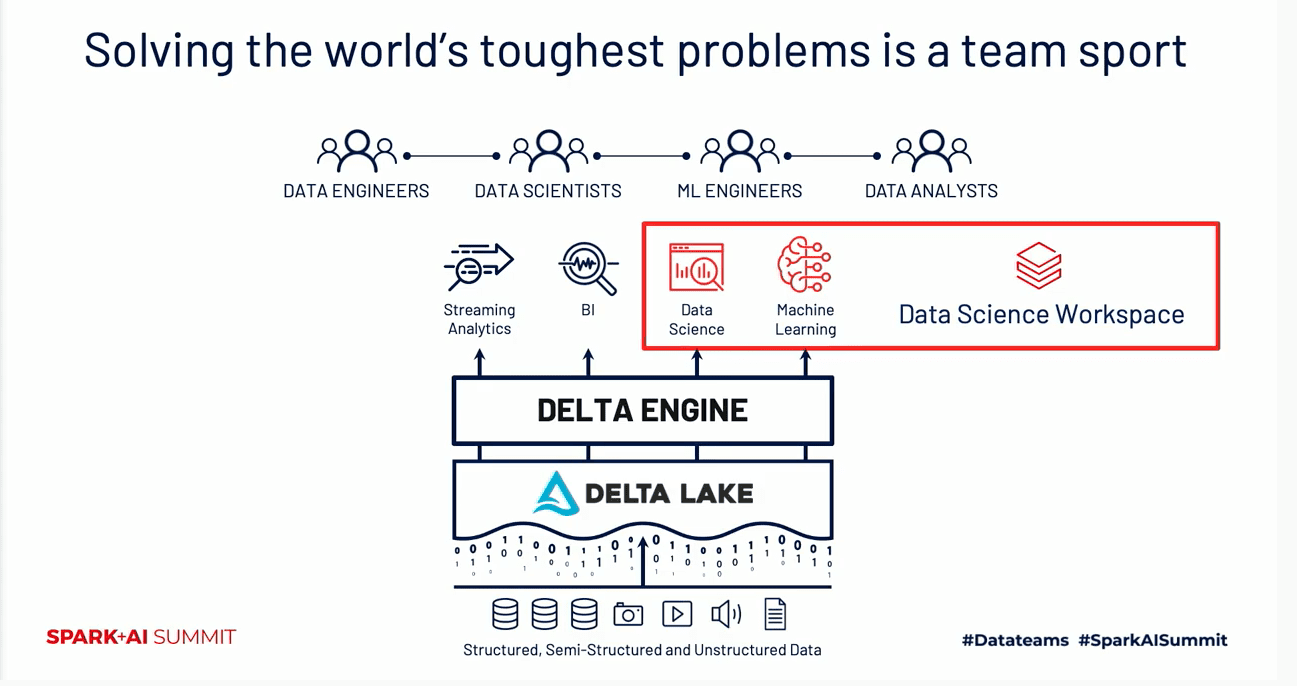
Finally, two keynotes completed the narrative with the use of popular software development tools for data teams. First, Clemens Mewald and Lauren Richie walked us through how data scientists, using the newly introduced Databricks next-generation Data Science Workspace, could work collaboratively through a new concept — Projects — using their favorite Git repository.

Four easy steps allow you to create a Project as part of your Databricks workspace:
- Create a new Project
- Clone your master Git repository and create a branch for collaboration
- Open a Jupyter notebook, if one exists in the repository, into the Databricks notebook editor
- Start coding and collaborating with developers in the data team
- Pull, commit and push your code as desired
Not much different from your Git workflow on your laptop, this collaborative process is now available in private preview in Databricks workspace, on a scalable cluster, giving you the ability to access data in the Lakehouse and configure a project-scoped Conda environment (coming soon) if required for your project.
Second, this last bit finished the narrative of how data teams come together with new capabilities in MLflow, a platform for a complete machine learning lifecycle. Presented by Matei Zaharia and Sue Ann Hong, the key takeaways for developers were:
- The state of the MLflow project and community, new features and what’s the future
- Databricks contributes MLflow to the Linux Foundation Project, expanding its scope and expecting contributions from the larger machine learning developer community
- MLflow on Databricks announces easy Model Serving
- The MLflow 1.9 release introduces stronger model governance, experiment autologging capabilities in some of its ML libraries, and pluggable deployment APIs
All in all, these announcements from a developer’s lens afford us a sense of new trends and paradigms in the big data and AI space; they offer new tools, APIs, and insights into how data teams can come together to solve tough data problems.
Meetups and Ask Me Anything
Let’s shift focus to communal developer activities. Since the earliest days of this conference, there’s always been a kick-off meetup with cold brew and tech banter. By the end of the meetup, excitement is in the air and the eagerness in the venue is palpable — all for the next few days of keynotes and break-away sessions. This time, we hosted the meetup virtually. And the eagerness was just as palpable — in attendance and through interactivity via the virtual Q&A panels.
Just concluded our Brew Banter & AI for Social Good @SparkAISummit with @dennylee Rob Reed & @lmoroney. Huge virtual turn up; loads of engaging questions; and attendees from across the globe, in different timezones. Thank you all! #DataTeams #sparkaisummit. pic.twitter.com/Fe213Nueed
— { Jules Damji } ? (@2twitme) June 22, 2020
Like meetups, Ask Me Anything (AMA) sessions are prevalent at conferences. As an open forum, developers from around the globe asked unfiltered questions to committers, contributors, practitioners and subject matter experts on the panel. We hosted over a half dozen AMAs, including the following:
- Four Delta Lake AMAs
- MLflow AMA
- Apache Spark 3.0 and Koalas AMA
- AMA with Matei Zaharia
- AMA with Nate Silver
Training, tutorials and tracks
Next, the jewels in the oasis of knowledge. Catering to a range of developer roles — data scientist, data engineer, SQL analyst, platform administrator, and business leader — Databricks Academy conducted paid training for two days, with half-day repeated sessions. Equally rich in technical depth were the diverse break-away sessions, deep dives and tutorials across tracks and topics aimed at all skill levels: beginner, intermediate and advanced.
These sessions are the pulsing heartbeat of knowledge that we relish to hear about when we attend conferences. They are what propel us to travel lands and cross oceans. Except this time, you could do it from your living room, without the panic of missing sessions or running across hallways and buildings to get to the next session in time. One participant noted that this virtual conference set a high bar for technical content and engagement as she attends future virtual conferences.
Swag, parties and camaraderie
Well, you can’t have delicious curry without masala, can you? Naturally, the key conference ingredients of swag, parties and camaraderie are as important as technical sessions. Got to have the T-shirt and goodies! But this time, you didn’t have to carry your backpack to hold the goodies. Instead, you could shop at the online Summit shop, redeem your Summit points (accumulated by attending numerous events, including the two nights of virtual parties with games and activities), and have your swag shipped to you — some restrictions applied for some global destinations.
Throughout the five days, you could pose for selfies and share on social media, interact and make new connections with a global community on the virtual platform, and schedule an appointment at the DevHub to ask technical questions — and follow up later.
As a developer advocate, judging by our initial expectations, they were met beyond a doubt. Had it not been for the inimitable Spark + AI Summit organizing committee uniting as a #datateam, this virtual event would not have been possible. So huge kudos and hats off to them and the global community!
What’s next
Well, if you missed some sessions, all are online now for perusal. A few favorite picks include:
- Deep Dive into the New Features of Apache Spark 3.0
- Pandas UDF and Python Type Hint in Apache Spark 3.0
- Koalas: Making an Easy Transition from Pandas to Apache Spark
- Machine Learning Data Lineage with MLflow and Delta Lake
- Patterns and Operational Insights from the First Users of Delta Lake
- Adaptive Query Execution: Speeding Up Spark SQL at Runtime
- A Guide to the MLflow Talk at Spark + AI Summit 2020

Free 2nd Edition includes updates on Spark 3.0, including the new Python type hints for Pandas UDFs, new date/time implementation, etc.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.