Bucket Brigade — Securing Public S3 Buckets
Are your Amazon S3 buckets secure? Do you know which ones are public or private? Do you even know which ones are supposed to be?
Data breaches are expensive. Facebook notoriously exposed 540 million records of its users recently, which was a contributing factor of the $5 billion fine they were issued by the FTC. Unfortunately, these kinds of breaches feel increasingly common. By one account, 7% of all Amazon Web Services (AWS) S3 buckets are publicly accessible. While some of these buckets are intentionally public, it’s all too common for non-public sensitive data to be exposed accidentally in public-facing buckets.
The Databricks security team recently encountered this situation ourselves. We were alerted to a potentially non-public object contained in one of our public buckets. While the result was benign, we set out to improve our overall bucket security posture and be able to affirmatively answer the questions above at all times. We set out to provide not only tighter controls around what was and was not public, but also to monitor our intentionally public resources for unintentional exposures.
Our S3 Bucket Security Solution
As a response to our initial alert, we took action to identify all of our S3 buckets and the public / non-public status. Since Databricks is a cloud-native company, we had already deployed JupiterOne, a commercial cloud asset management solution that allowed us to quickly query and determine which assets were public. Open-source tools are available, such as Cartography from Lyft, which allow for similar query capabilities. With the outputs of our queries, we were able to quickly identify and triage our public buckets and determine whether they should remain public.
Having verified whether our buckets should be public, we wanted to address a few questions:
- Did we have any existing non-public files in our intentionally public buckets?
- How could we prevent buckets, and their objects, from becoming public unintentionally?
- How could we continuously monitor for secrets in our public buckets and get real-time alerts?
Tools
To address each of these questions, we found, implemented and created tools. Each tool below addresses one of the above questions.
YAR: (Y)et (A)nother (R)obber
To address our first question whether we had any existing non-public files in our intentionally public buckets, we repurposed Níels Ingi’s YAR tool – typically used for scanning Github repositories for secrets – to scan our existing public buckets. We spun up EC2 instances, synchronized the bucket contents, customized the YAR configuration with additional patterns specific to our secrets, and ran YAR. In order to speed this up, we wrote a script that wraps YAR and allows for parallel execution and applies pretty formatting to the results.
Sample YAR Output with Secret Context
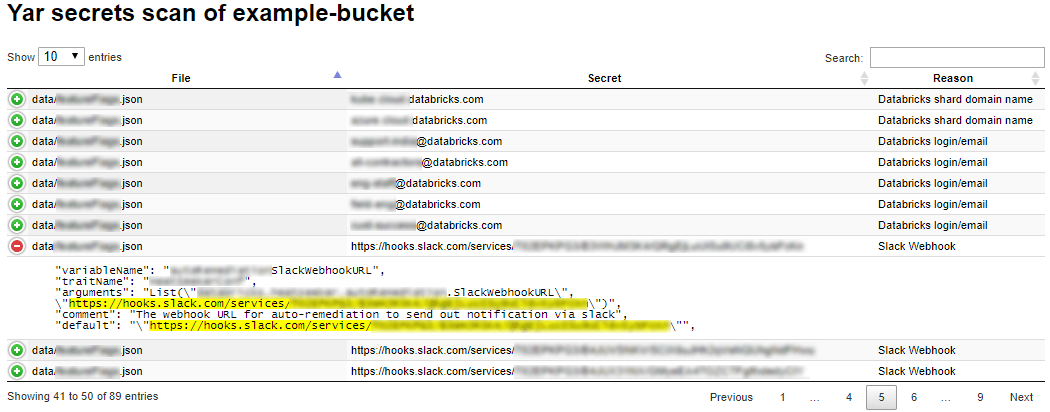
As shown above, YAR provides context for lines surrounding the secret, which allowed us to more quickly triage identified potential secrets.
Cloud Custodian Access Management
To address our second question of how we could prevent buckets, and their objects, from becoming public unintentionally, we employed Cloud Custodian. We had already deployed this self-identified “opensource cloud security, governance and management” tool for other purposes, and it became clear it could help us in this effort too. Cloud Custoidan’s real-time compliance uses AWS Lambda functions and CloudWatch events to detect changes to configuration.
We added a Cloud Custodian policy to automatically enable AWS public access blocks for buckets and their objects exposed publicly through any access control lists (ACLs). We created an internal policy and process to get exceptions for intentionally public buckets that required this functionality to remain disabled. This meant that between Cloud Custodian’s enforcement and JupiterOne’s alerting for buckets configured with public access, we could ensure that none of our buckets were unintentionally public or exposing objects.
S3 Secrets Scanner
To address our third question, how we could continuously monitor for secrets in our public buckets and get real-time alerts, we wanted additional assurance that objects in our intentionally public buckets did not get updated with non-public objects. Importantly we wanted to get this information as quickly as possible to limit our exposure in the event of accidental exposure.
We developed a simple solution. We employed S3 events to trigger on any modification to objects in our S3 buckets. Whenever bucket objects are created or updated, the bucket’s event creates an SQS queue entry for the change. Lambda functions then process these events inspecting each file for secrets using pattern matching (similar to the YAR method). If any matches are found, the output is sent to an alert queue. The security team receives alerts from the queue, allowing for a near-real-time response to the potential exposure.
S3 Secrets Scanner Architecture
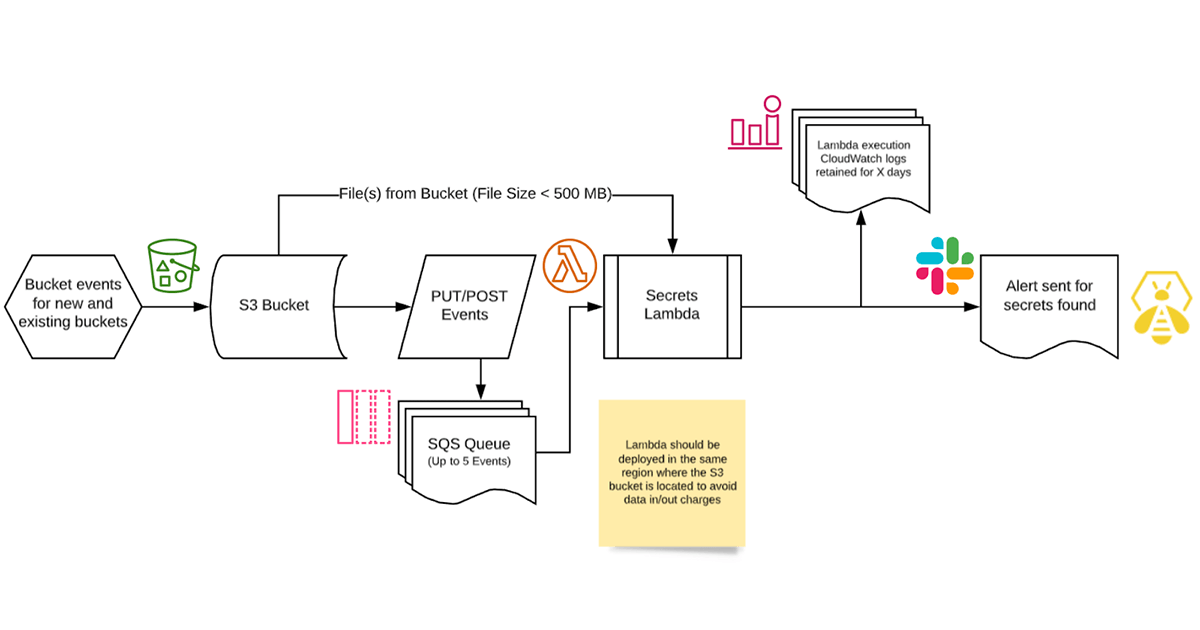
With all of the above questions addressed, we were feeling pretty good until …
Complications
Shortly after we deployed the above tooling, the Databricks security team was alerted to an outage that appeared to be caused by our new tooling and processes. In order to resolve the immediate issue we had to roll-back our Cloud Custodian changes. Through Databricks’s postmortem process, it became clear that despite having sent notifications about the tooling and process changes, it hadn’t been sufficient. Our solution was not universally understood and was causing confusion for people who suddenly had buckets enforcing access limits. Additionally, in one case, a bucket was nearly deleted when the security team followed up on an alert that it was public. The owner indicated that the bucket was no longer needed, but after removing access – a precaution prior to deleting the bucket – we discovered that an unknown team was using the bucket unknown to the apparent owner.
It became apparent that clear bucket ownership was key to our success for securing our buckets. Clear, authoritative ownership meant that we would be able to get quick answers to alerts and would provide an accountable party for the exception process for intentionally public buckets.
While we’d adopted some best practices for ownership identification using tags, we had some inconsistencies in the implementation. This meant that even when people were “doing the right thing”, the result was inconsistent and made it difficult to clearly identify owners.
Our Solution Revisited
We stepped back from enforcing our initial solution while we could get clearer ownership information and provide better communication.
We turned to JupiterOne again to query our S3 ownership information. Armed with a literal bucket list, we went to each AWS account owner for help in identifying clear owners for each bucket. We published policies around required tagging standards for ownership to ensure that there was consistency in the method used. We also published policies clarifying the Cloud Custodian public access blocks and exception process. Our CISO sent notifications to both leadership and the broader company creating awareness and support aligning behind our new policies and process.
We added ownership tagging enforcement via Cloud Custodian to our overall technical strategy. Importantly, our communication process helped identify some modifications to our enforcement approach. Originally, we identified that we would remove buckets missing compliant ownership tags. While this was appropriate for non-production resources, it was too aggressive for production resources. Instead, for production resources we updated Cloud Custodian to create tickets within our ticketing system with defined service level agreements (SLAs) to ensure that ownership would not be missing for long and without putting critical resources at risk.
Implementing a clear ownership process and providing clear communication to leadership, AWS account owners and users took more time than our original technical solution implementation, but it meant that this time we could enable it without any concern of an outage or accidentally removing important contents.
Databricks Loves to Open Source
Databricks is a big participant in the open source community – we are the original creators of Apache Spark™, Delta Lake™, Koalas and more – and secure data is extremely important to us. So, naturally having solved this problem for ourselves, we wanted to share the result with the community.
However, as security professionals, we considered what should be part of our offering. We have commonly seen tools open sourced, but in this case we identified that equally important to our tooling was the communication, policies and process surrounding those tools. For this reason, we are open sourcing Bucket Brigade – a complete solution for securing your public buckets.
The open source repository includes a detailed write-up of each of the solution phases with step-by-step implementation guides, including the code for the tools implemented. Perhaps equally importantly, it also includes policies for maintaining clear bucket ownership, enforcing public access blocks and getting exceptions. It extends the policies with email templates for leadership and user communication to ensure that the policies and process are well-understood prior to implementation.
Let’s all be able to answer the questions about our public S3 data and avoid being part of the problem.
Check out our open source Bucket Brigade solution.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.