Operationalize 100 Machine Learning Models in as Little as 12 Weeks with Azure Databricks

In rapidly changing environments, Azure Databricks enables organizations to spot new trends, respond to unexpected challenges and predict new opportunities. Organizations are leveraging machine learning and artificial intelligence (AI) to derive insight and value from their data and to improve the accuracy of forecasts and predictions. Data teams are using Delta Lake to accelerate ETL pipelines and MLflow to establish a consistent ML lifecycle.
Solving the complexity of ML frameworks, libraries and packages
Customers frequently struggle to manage all of the libraries and frameworks for machine learning on a single laptop or workstation. There are so many libraries and frameworks to keep in sync (H2O, PyTorch, scikit-learn, MLlib). In addition, you often need to bring in other Python packages, such as Pandas, Matplotlib, numpy and many others. Mixing and matching versions and dependencies between these libraries can be incredibly challenging.

Diagram: Databricks Runtime for ML enables ready-to-use clusters with built-in ML Frameworks
With Azure Databricks, these frameworks and libraries are packaged so that you can select the versions you need as a single dropdown. We call this the Databricks Runtime. Within this runtime, we also have a specialized runtime for machine learning which we call the Databricks Runtime for Machine Learning (ML Runtime). All these packages are pre-configured and installed so you don't have to worry about how to combine them all together. Azure Databricks updates these every 6-8 weeks, so you can simply choose a version and get started right away.
Establishing a consistent ML lifecycle with MLflow
The goal of machine learning is to optimize a metric such as forecast accuracy. Machine learning algorithms are run on training data to produce models. These models can be used to make predictions as new data arrive. The quality of each model depends on the input data and tuning parameters. Creating an accurate model is an iterative process of experiments with various libraries, algorithms, data sets and models. The MLflow open source project started about two years ago to manage each phase of the model management lifecycle, from input through hyperparameter tuning. MLflow recently joined the Linux Foundation. Community support has been tremendous, with over 200 contributors, including large companies. In June, MLflow surpassed 2.5 million monthly downloads.
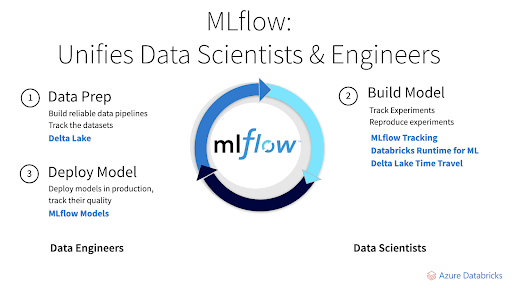
Diagram: MLflow unifies data scientists and data engineers
Ease of infrastructure management
Data scientists want to focus on their models, not infrastructure. You don’t have to manage dependencies and versions. It scales to meet your needs. As your data science team begins to process bigger data sets, you don’t have to do capacity planning or requisition/acquire more hardware. With Databricks, it’s easy to onboard new team members and grant them access to the data, tools, frameworks, libraries and clusters they need.
Building your first machine learning model with Azure Databricks
To help you get a feel for Azure Databricks, let’s build a simple model using sample data in Azure Databricks. Often a data scientist will see a blog post about an algorithm, or have some data they want to use for exploratory ML. It can be very hard to take a code snippet found online, shape a dataset to fit the algorithm, then find the correct infrastructure and libraries to pull it all together. With Azure Databricks, all that hassle is removed. This blog post talks about time-series analysis with a library called Prophet. It would be interesting to take this idea, of scaling single-node machine learning to distributed training with Spark and Pandas UDFs, and apply it to a COVID-19 dataset available on Azure Databricks.
Installing the library is as simple as typing fbprophet in a PyPi prompt, then clicking Install. From there, once the data has been read into a pandas DataFrame and transformed into the format expected by Prophet, trying out the algorithm was quick and simple.
With a DataFrame containing the predictions, plotting the results within the same notebook just takes a call to display().
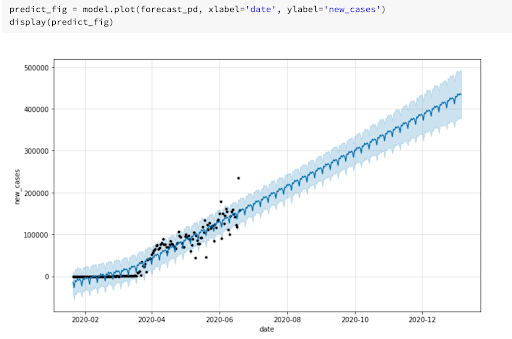
Diagram: Creating a machine learning model in Azure Databricks
The referenced blog then used a Pandas UDF to scale up this model to much larger amounts of data. We can do the same, and train models in parallel on several different World Health Organization (WHO) regions at once. To do this we wrap the single-node code in a Pandas UDF:
We can then apply the function to each WHO region and view the results:
Finally, we can use the Azure Databricks notebooks’ SQL functionality to quickly visualize some of our predictions:
From our results we can see that this dataset is not ideal for time-series forecasting. However, we were able to quickly experiment and scale up our model, without having to set up any infrastructure or manage libraries. We could then share these results with other team members just by sending the link of the collaborative notebook, quickly making the code and results available to the organization.
Alignment Healthcare
Alignment Healthcare, a rapidly growing Medicare insurance provider, serves one of the most at-risk groups of the COVID-19 crisis—seniors. While many health plans rely on outdated information and siloed data systems, Alignment processes a wide variety and large volume of near real-time data into a unified architecture to build a revolutionary digital patient ID and comprehensive patient profile by leveraging Azure Databricks. This architecture powers more than 100 AI models designed to effectively manage the health of large populations, engage consumers, and identify vulnerable individuals needing personalized attention—with a goal of improving members’ well-being and saving lives.
Start building your machine learning models on Azure Databricks
Try out the notebook hosted here and learn more about building ML models on Azure Databricks by attending this webinar, From Data to AI with Microsoft Azure Databricks, this Azure Databricks ML training module on MS Learn and our next Azure Databricks Office Hours. If you are ready to grow your business with machine learning in Azure Databricks, schedule a demo.

