Using MLOps with MLflow and Azure
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
The blog contains code examples in Azure Databricks, Azure DevOps and plain Python. Please note that much of the code depends on being inside an Azure environment and will not work in the Databricks Community Edition or in AWS-based Databricks.
Most organizations today have a defined process to promote code (e.g. Java or Python) from development to QA/Test and production. Many are using Continuous Integration and/or Continuous Delivery (CI/CD) processes and oftentimes are using tools such as Azure DevOps or Jenkins to help with that process. Databricks has provided many resources to detail how the Databricks Unified Analytics Platform can be integrated with these tools (see Azure DevOps Integration, Jenkins Integration). In addition, there is a Databricks Labs project - CI/CD Templates - as well as a related blog post that provides automated templates for GitHub Actions and Azure DevOps, which makes the integration much easier and faster.
When it comes to machine learning, though, most organizations do not have the same kind of disciplined process in place. There are a number of different reasons for that:
- The Data Science team does not follow the same Software Development Lifecycle (SDLC) process as regular developers. Key differences in the Machine Learning Lifecycle (MLLC) are related to goals, quality, tools and outcomes (see diagram below).
- Machine Learning is still a young discipline and it is often not well integrated organizationally.
- The Data Science and deployment teams do not treat the resulting models as separate artifacts that need to be managed properly.
- Data Scientists are using a multitude of tools and environments which are not integrated well and don’t easily plug into the above mentioned CI/CD Tools.
To address these and other issues, Databricks is spearheading MLflow, an open-source platform for the machine learning lifecycle. While MLflow has many different components, we will focus on the MLflow Model Registry in this Blog.
The MLflow Model Registry component is a centralized model store, set of APIs, and a UI, to collaboratively manage the full lifecycle of a machine learning model. It provides model lineage (which MLflow experiment and run produced the model), model versioning, stage transitions (for example from staging to production), and annotations.
The Azure Databricks Unified Data and Analytics platform includes managed MLflow and makes it very easy to leverage advanced MLflow capabilities such as the MLflow Model Registry. Moreover, Azure Databricks is tightly integrated with other Azure services, such as Azure DevOps and Azure ML.
Azure DevOps is a cloud-based CI/CD environment integrated with many Azure Services. Azure ML is a Machine Learning platform which in this example will serve the resulting model. This blog provides an end-to-end example of how all these pieces can be connected effectively.
An end-to-end model governance process
To illustrate why an MLOps pipeline is useful, let’s consider the following business scenario: Billy is a Data Scientist working at Wine Inc. Wine Inc. is a global wholesaler of wines that prides itself on being able to find and promote high-quality wines that are a lot less expensive than comparable quality wines. The key success factor of Wine Inc. is a machine learning model for wine that can predict the quality of the wine (for example purposes we are using a public wine qualities dataset (published by Cortez et al.). Key features of the dataset include chemical ones such as fixed acidity, citric acid, residual sugar, chlorides, density, pH and alcohol. It also includes a sensory based quality score between 0 and 10. Billy is constantly rolling out improvements to the model to make it as accurate as possible. The main consumers of the model are the field wine testers. The field wine testers are testing wines across the globe and can quickly analyze the key features of the wine. Wine testers promptly enter the wine features in a mobile app which immediately returns a predictive quality score to the tasters. If a score is high enough, the tasters can acquire the wine for wholesale distribution on the spot.
Billy has started to use the MLFlow Model Registry to store and manage the different versions of his wine quality model. The MLflow Model Registry builds on MLflow’s existing capabilities to provide organizations with one central place to share ML models, collaborate on moving them from experimentation to testing and production, and implement approval and governance workflows.
The registry is a huge help in managing the different versions of the models and their lifecycle.
Once a machine learning model is properly trained and tested, it needs to be put into production. This is also known as the model serving or scoring environment. There are multiple types of architectures for ML model serving. The right type of ML production architecture is dependent on the answer to two key questions:
- Frequency of data refresh: How often will data be provided, e.g. once a day, a few times a day, continuously, or ad hoc?
- Inference request response time: How quickly do we need a response to inference requests to this model, e.g. within hours, minutes , seconds or sub-second/ milliseconds?
If the frequency is a few times a day and the inference request response time required is minutes to hours, a batch scoring model will be ideal. If the data is provided continuously, a streaming architecture should be considered, especially if the answers are needed quickly. If the data is provided ad hoc and the answer is needed within seconds or milliseconds, a REST API-based scoring model would be ideal.
In the case of Wine Inc., we assume that the latter is the case, i.e. the field testers request the results ad hoc and expect an immediate response. There are multiple options to provide REST based model serving, e.g. using Databricks REST Model serving or a simple Python based model server which is supported by MLFlow. Another popular option for model serving inside of the Azure ecosystem is using AzureML. Azure ML provides a container-based backend that allows for the deployment of REST-based model scoring. MLflow directly supports Azure ML as a serving endpoint. The remainder of this blog will focus on how to best utilize this built-in MLflow functionality.
The diagram above illustrates which end-to-end steps are required. I will use the diagram as the guide to walk through the different steps of the pipeline. Please note that this pipeline is still somewhat simplified for demo purposes.
The main steps are:
- Steps 1, 2 and 3: Train the model and deploy it in the Model Registry
- Steps 4 through 9: Setup the pipeline and run the ML deployment into QA
- Steps 10 through 13: Promote ML model to production
Steps 1, 2 and 3: Train the model and deploy it in the Model Registry
Please look at the following Notebook for guidance:
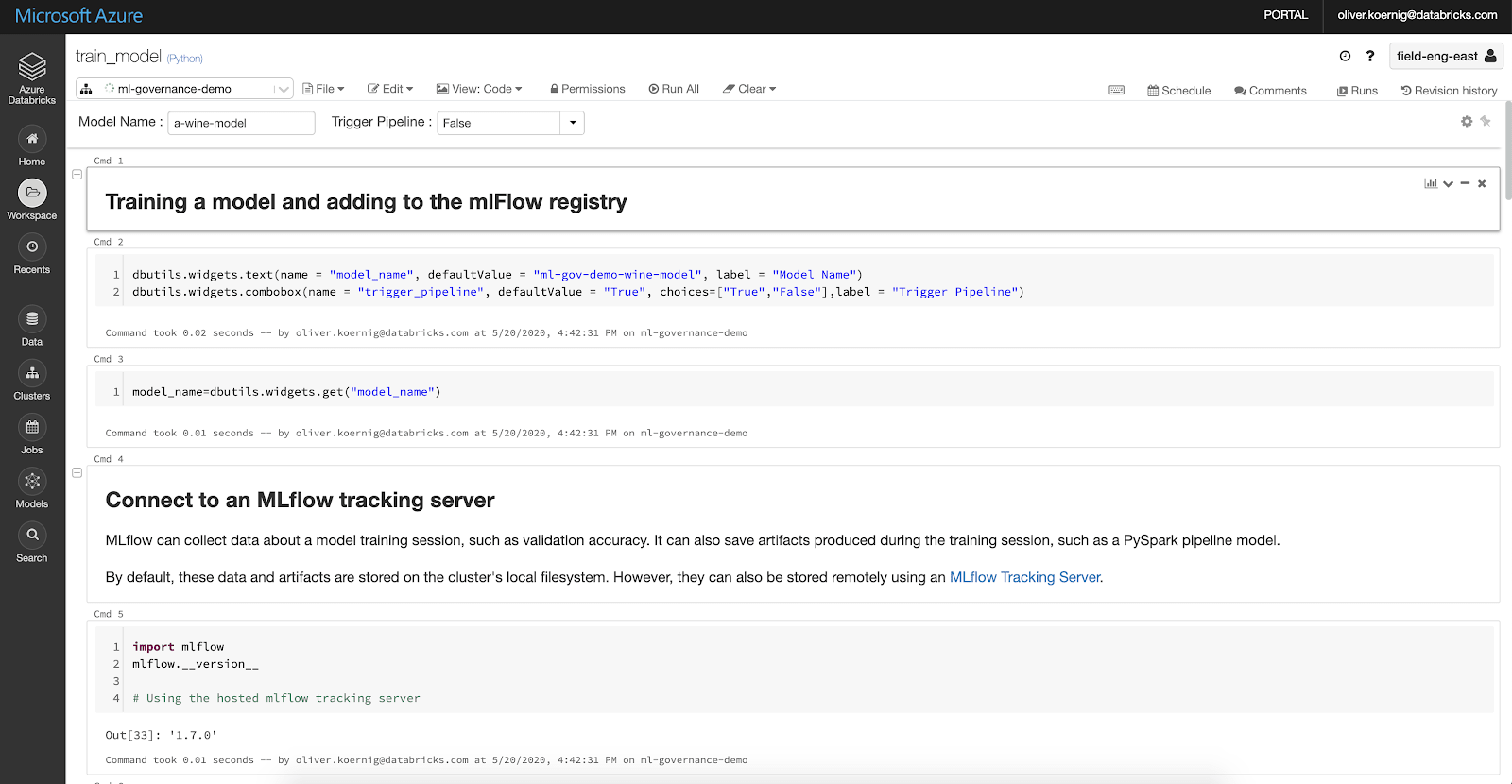
Billy continuously develops his wine model using the Azure Databricks Unified Data and Analytics Platform. He uses Databricks managed MLflow to train his models and run many model variations using MLFlow’s Tracking server to find the best model possible. Once Billy has found a better model, he stores the resulting model in the MLflow Model Registry, using the Python code below.
(The sleep step is needed to make sure that the registry has enough time to register the model).
Once Billy has identified his best model, he registers it in the Model Registry as a “staging” model.
Azure DevOps provides a way to automate the end-to-end process of promoting, testing and deploying the model in the Azure ecosystem. It requires the creation of an Azure DevOps pipeline. The remainder of this blog will dive into how best define the Azure DevOps pipeline and integrate it with Azure Databricks and Azure.
Once Billy defines the Azure DevOps pipeline, he can then trigger the pipeline programmatically, which will test and promote the model into the production environment used by the mobile app.
The Azure Pipeline is the core component of Azure DevOps. It contains all the necessary steps to access and run code that will allow the testing, promotion and deployment of a ML pipeline. More info on Azure pipelines can be found here.
Another core component of Azure DevOps is the repo. The repo contains all the code that is relevant for a build and deploy pipeline. The repo stores all the artifacts that are required, including:
- Python notebooks and/or source code
- Python scripts that interact with Databricks and MLflow
- Pipeline source files (YAML)
- Documentation/read me etc.
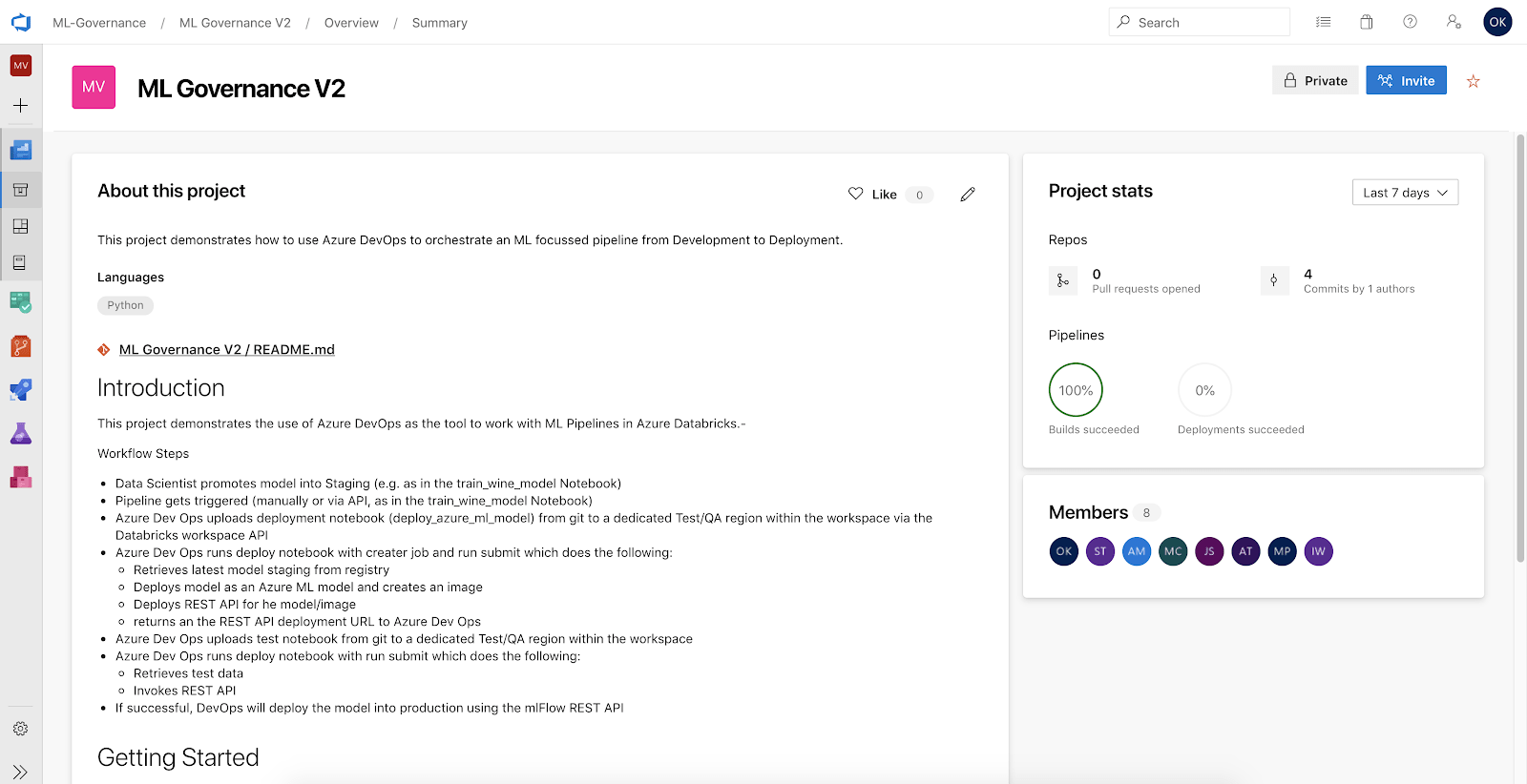
The image below shows the DevOps project and repo for the Wine Inc. pipeline:
The DevOps pipeline is defined in YAML. This is an example YAML file for the pipeline in this blog post,
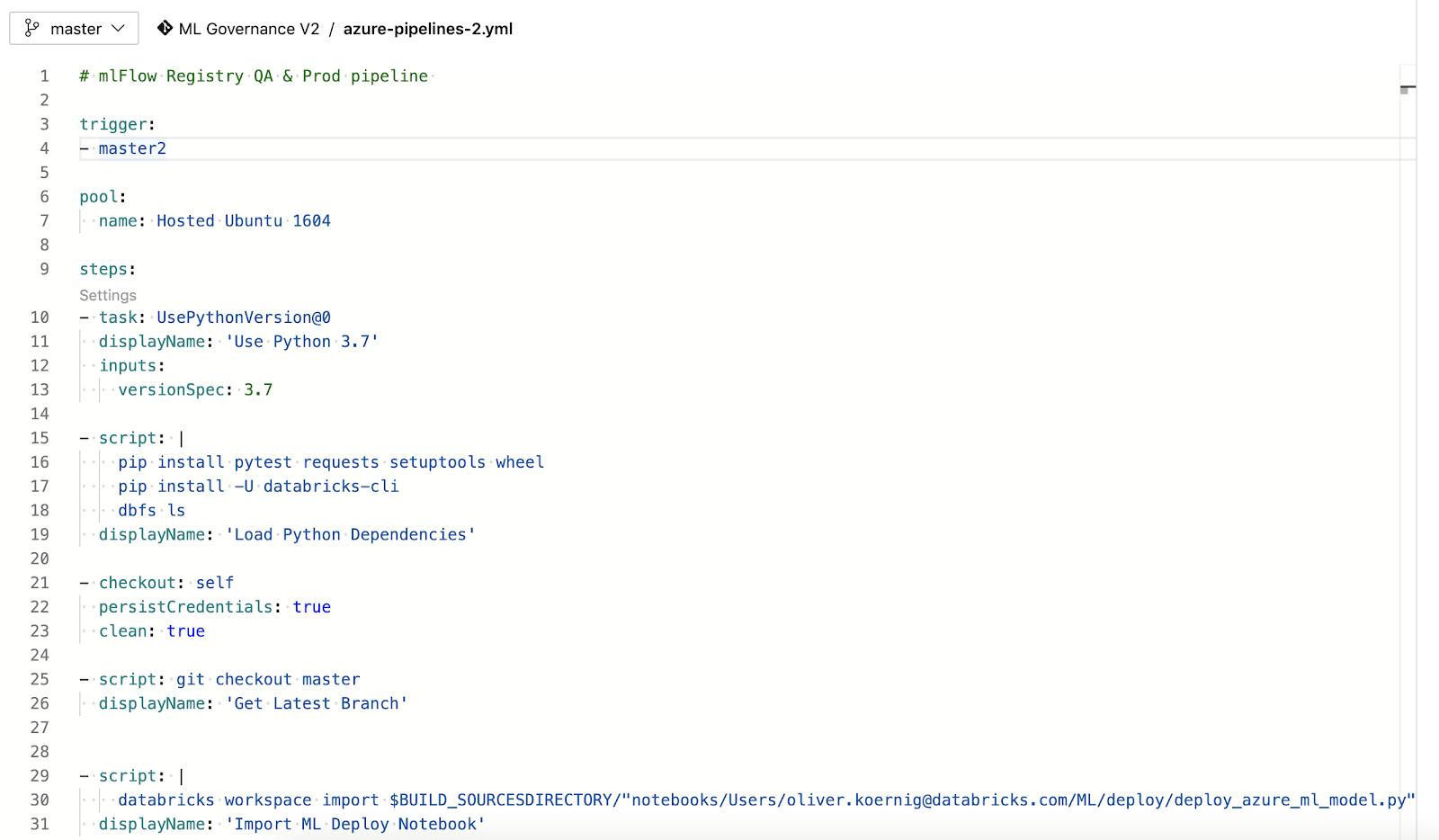
Line 3: Trigger: Oftentimes, pipelines will be triggered automatically by code changes. Since promoting a model in the Model Registry is not a code change, the Azure DevOps REST API can be used to trigger the pipeline programmatically. The pipeline can also be triggered manually via the UI.
This is the code in the training notebook that uses the DevOps REST API to trigger the pipeline:
Steps 4 through 9: Setup the pipeline and run the ML deployment into QA
The Azure pipeline is a YAML file. It will first setup the environment (all Python based) and then deploy the model into an Azure QA environment where it can be tested.

Line 15 to 19: Prerequisites: the pipeline installs a set of libraries that it needs to run the scripts. We are using Python to run the scripts. There are a variety of different options to run code in Python when using Azure Databricks. We will use a few of them in this blog.
Using the Databricks Command Line Interface: The Databricks CLI provides a simple way to interact with the REST API. It can create and run jobs, upload code etc. The CLI is most useful when no complex interactions are required. In the example the pipeline is used to upload the deploy code for Azure ML into an isolated part of the Azure Databricks workspace where it can be executed. The execution is a little more complicated, so it will be done using the REST API in a Python script further below.
Lines 32 to 37: This step executes the Python script executenotebook.py. It takes a number of values as parameters, e.g. the Databricks Host name, etc. It will also allow the passing of parameters into the notebook, such as the name of the Model that should be deployed and tested.
The code is stored inside the Azure DevOps repository along with the Databricks notebooks and the pipeline itself. Therefore it is always possible to reproduce the exact configuration that was used when executing the pipeline.
This Notebook “deploy_azure_ml_model” performs one of the key tasks in the scenario, mainly deploying an MLflow model into an Azure ML environment using the built in MLflow deployment capabilities. The notebook is parameterized, so it can be reused for different models, stages etc.
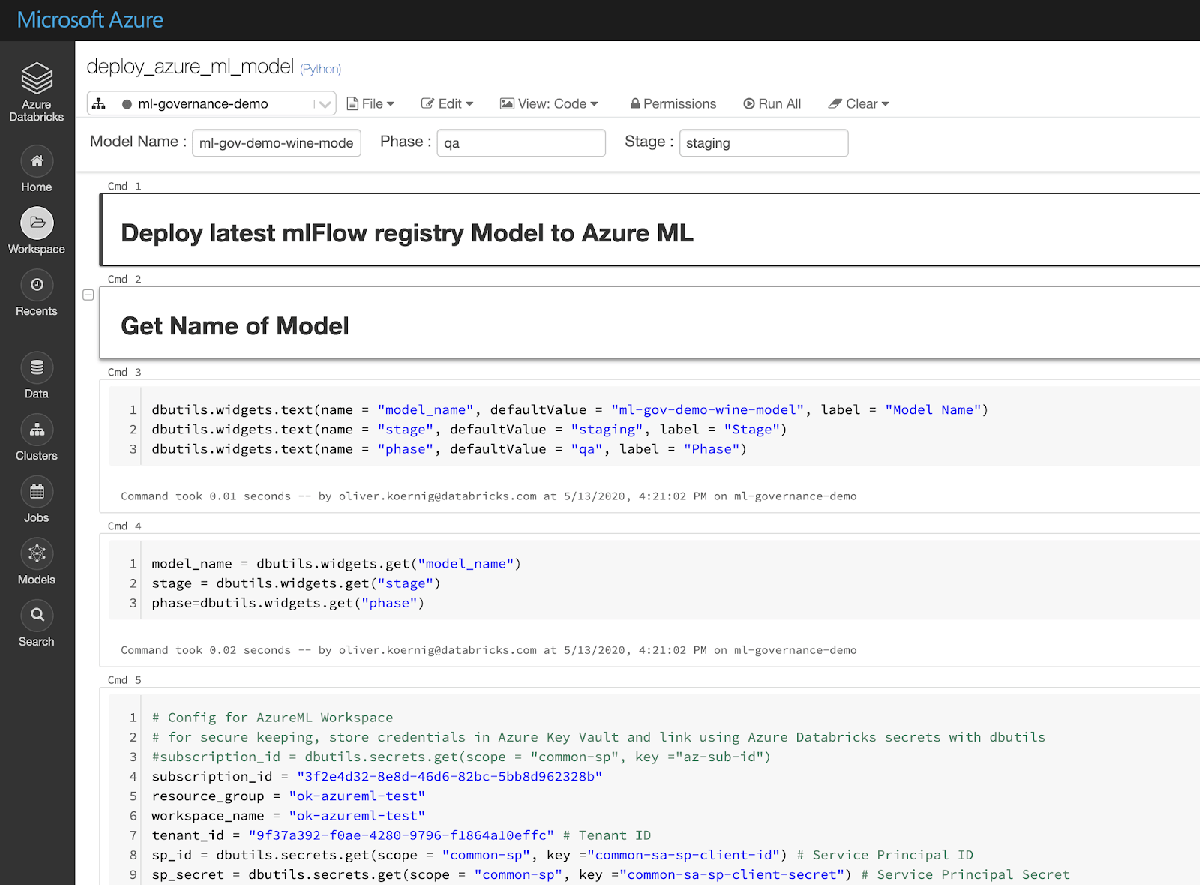
The following code snippet from the Notebook is the key piece that deploys the model in Azure ML using the MLflow libraries:
This will create a container image in the Azure ML workspace. The following is the resulting view within the Azure ML workspace:
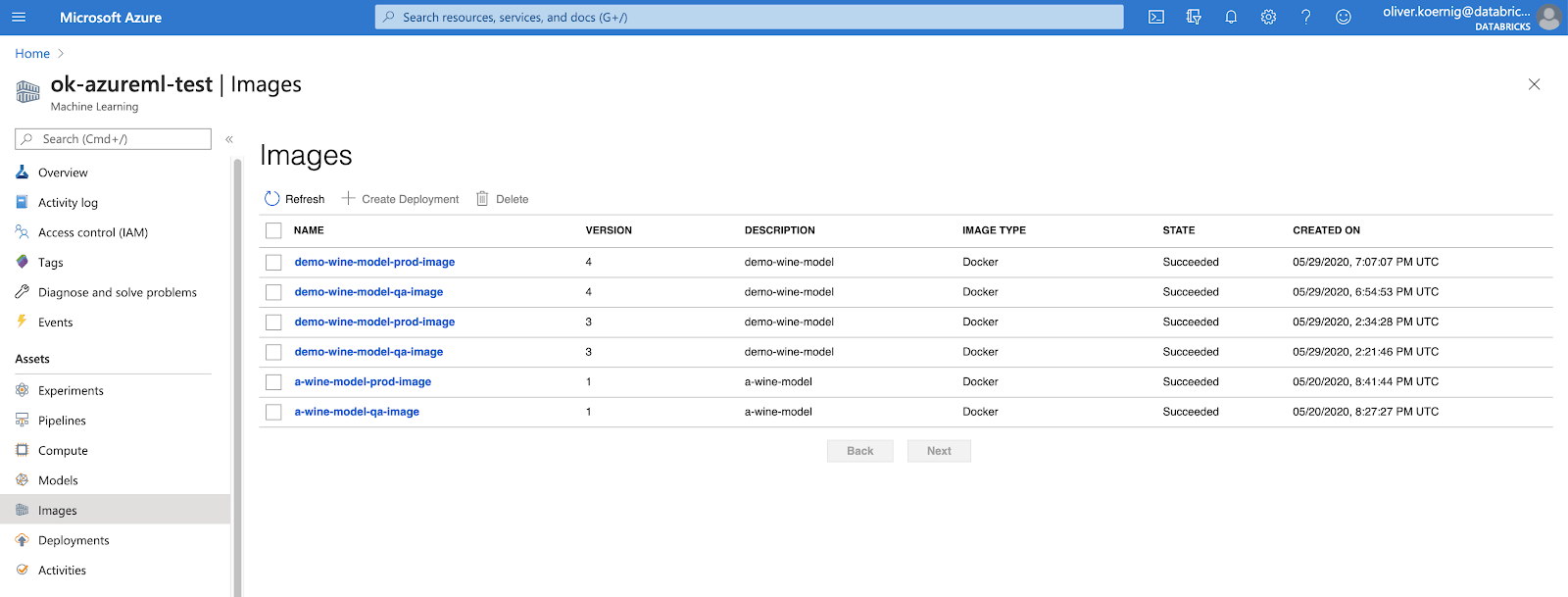
The next step is to create a deployment that will provide a REST API:
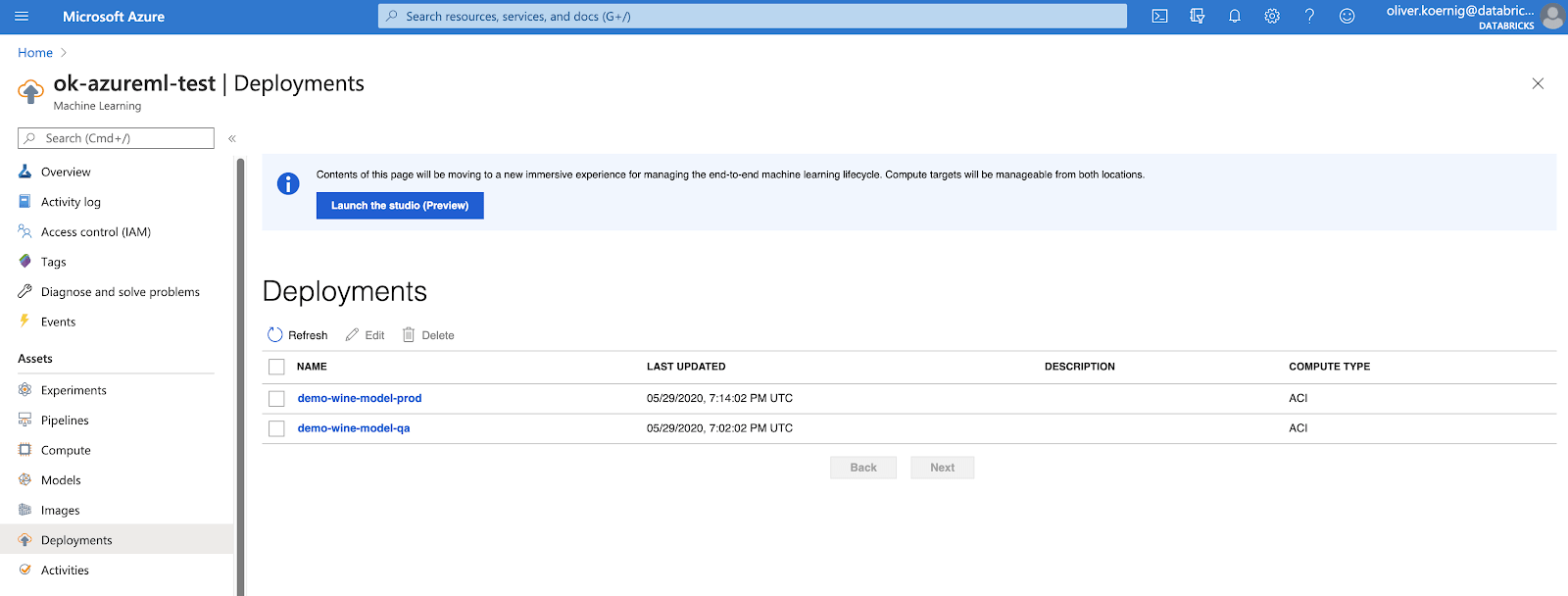
The Execution of this Notebook takes around 10-12 min. The executenotebook.py provides all the code that allows the Azure DevOps environment to wait until the Azure ML deployment task has been completed. It will check every 10 seconds if the job is still running and go back to sleep if indeed it is. When the model is successfully deployed on Azure ML, the Notebook will return the URL for the resulting model REST API. This REST API will be used further down to test if the model is properly scoring values.
When the pipeline is running, users can monitor the progress. The screen shot reveals the API calls and then 10 sec wait between calls.
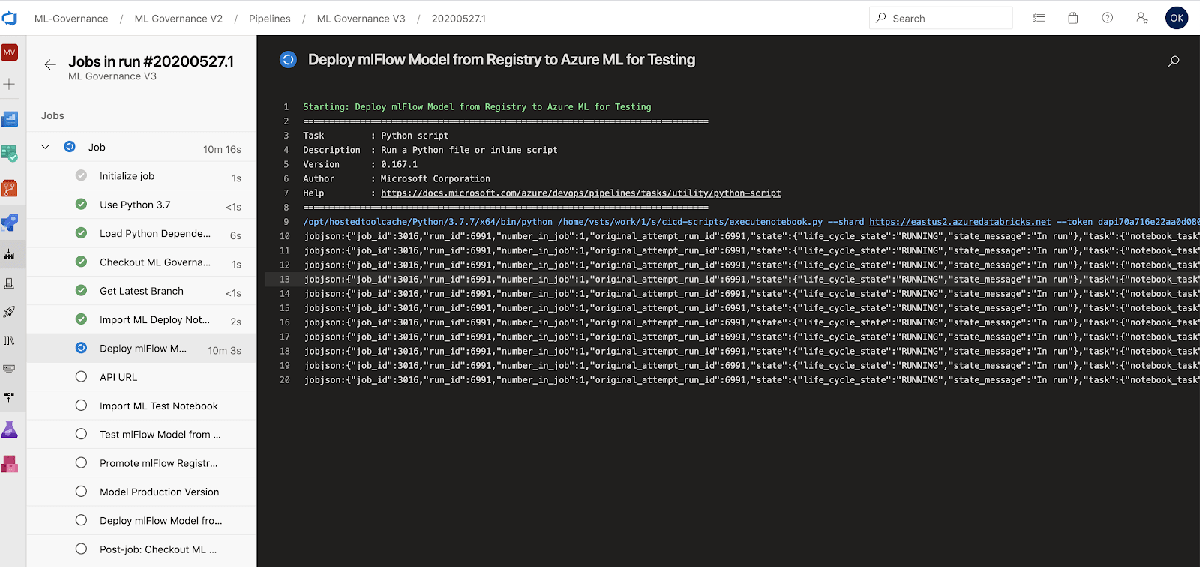
The next step is executing the test of the Notebook. Like the previous step it triggers the executenotebook.py code and passes the name of the test notebook (“test_api”) as well as the REST API from the previous step.
The testing code can be as simple or complicated as necessary. The “test_api” notebook simply uses a record from the initial training data and submits it via the model REST API from the Azure ML. If it returns a meaningful value the test is considered a success. A better way to test would be to define a set of expected results using the API and using a much larger set of records.
Steps 10 through 13: Promote ML model to production
Given a successful test, two things need to subsequently happen:
- The model in the MLflow Model Registry should be promoted to “Production”, which will tell Billy and other Data Scientists which model is the latest production model in use.
- The model needs to be put into production within Azure ML itself.
The next step will take care of the first step. It uses the managed MLflow REST API on Azure Databricks. Using the API, the model can be promoted (using the mlflow.py script within Dev Ops) w/o executing any code on Azure Databricks itself. It will only take a few seconds.
This script promotes the latest model with the given name out of staging into production
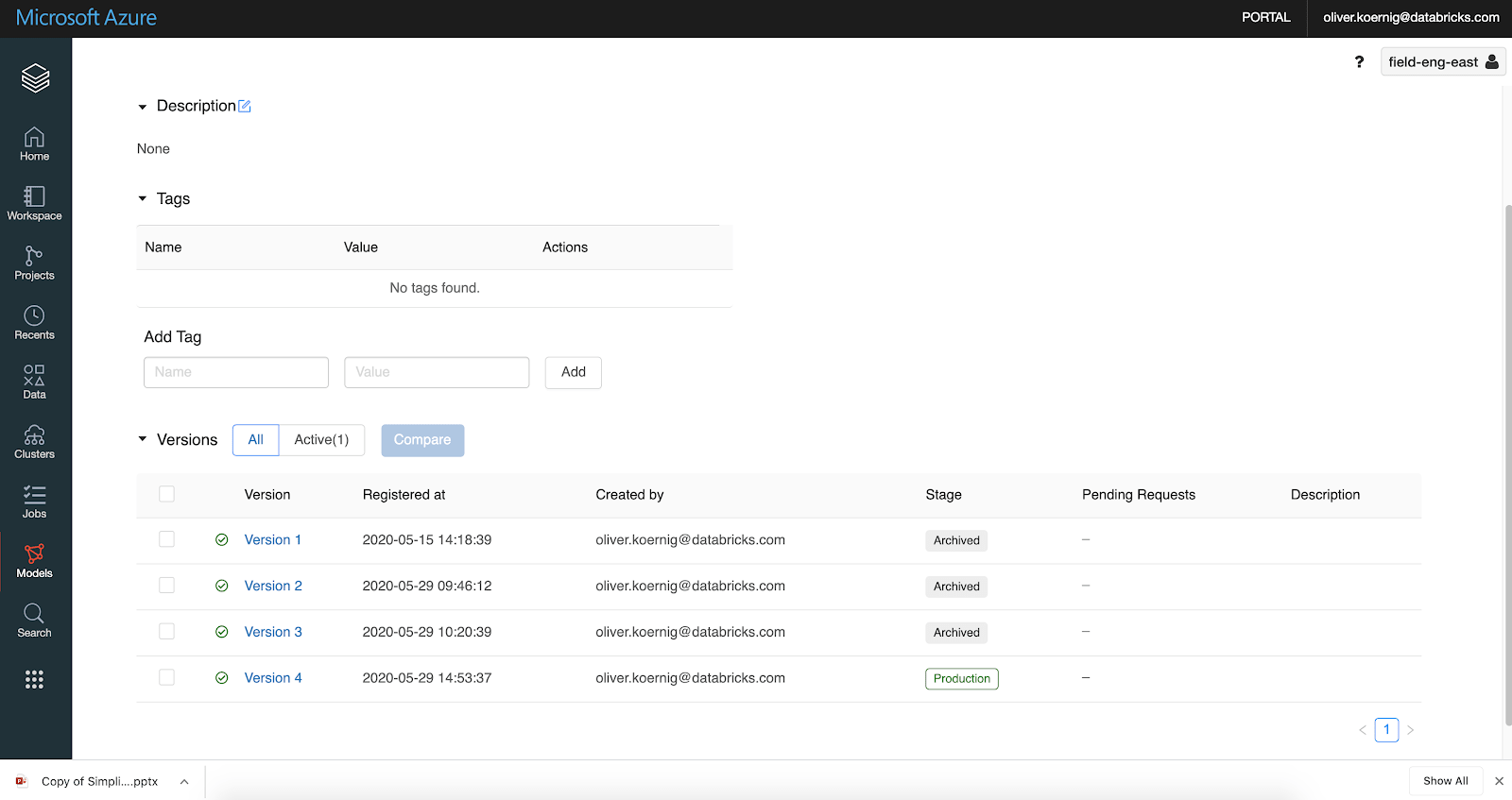
We can verify with the Azure Databricks Model UI that this has indeed happened: We can see that there is a new production level model (version 4). As a side note, while it is possible to have multiple models in production, we don’t consider that good practice, so all other production versions should be archived (MLflow provides a feature to automatically enable this by setting archive_existing_versions=true).
The next step is simply a repeat of steps 4 through 11. We will re-deploy the model in Azure ML and indicate that this is the production environment. Please note that Azure DevOps has a separate set of deploy pipelines which we are not utilizing in this blog in order to keep things a little simpler.
Discussion
This blog post has demonstrated how an MLLC can be automated by using Azure Databricks , Azure DevOps and Azure ML. It demonstrated the different ways Databricks can integrate with different services in Azure using the Databricks REST API, Notebooks and the Databricks CLI. See below for links to the three notebooks referenced in this blog
For questions or comments, please contact oliver.koernig@databricks.com.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.