New Features to Accelerate the Path to Production With the Next Generation Data Science Workspace
Today, at the Data + AI Summit Europe 2020, we shared some exciting updates on the next generation Data Science Workspace - a collaborative environment for modern data teams - originally unveiled at Spark + AI Summit 2020.
The power of data and artificial intelligence is already disrupting many industries, yet we've only scratched the surface of its potential, and data teams still face many challenges on a daily basis. This is partially due to the lack of smooth hands-off among a variety of roles involved at different stages of the lifecycle. In addition, the rapid innovation in that field means that most open-source software and tools provided are not production ready yet. And finally, traditional software engineering and DevOps tools built for production were designed when software wasn’t as closely tied to data as it is today, and they haven’t caught up with emerging practices in data science and machine learning.
The next-generation Data Science Workspace navigates these challenges to provide an open and unified collaborative experience for modern data teams by bringing together notebook environments with best-of-breed developer workflows for Git-based collaboration and reproducibility. This in turns gets fully automated with low-friction CI/CD pipelines from experimentation to production deployments.
In this blog, we'll cover the new features added to the Next Generation Data Science Workspace to continue to increase data science productivity and simplify hand-offs for data teams, specifically Table of Contents, TensorBoard, and Dark Mode as well as Staging of Changes, Diff View, and Enterprise Security features for Git-based Projects.
Introducing Embedded TensorBoard, Table of Contents, and Dark Mode for Databricks Notebooks
Data scientists and engineers alike already love Databricks notebooks for their collaborative and productivity features including support for multiple programming languages (Python, Scala, SQL, or R), commenting, co-authoring, co-presence, built-in visualizations, and the ability to track experiments along with the corresponding parameters, metrics, and code from a specific notebook version.
For example, Experiment Tracking on Databricks allows you to quickly see all of the runs that were logged using MLflow from within your notebook, with the click of a button. One common use case is to identify the best machine learning model by sorting by a metric. Now you can easily find the best run with the lowest loss. Because of the tight integration with the notebook, you can also go back to the exact version of the code that created this run, allowing you to reproduce it in the future as shown below.
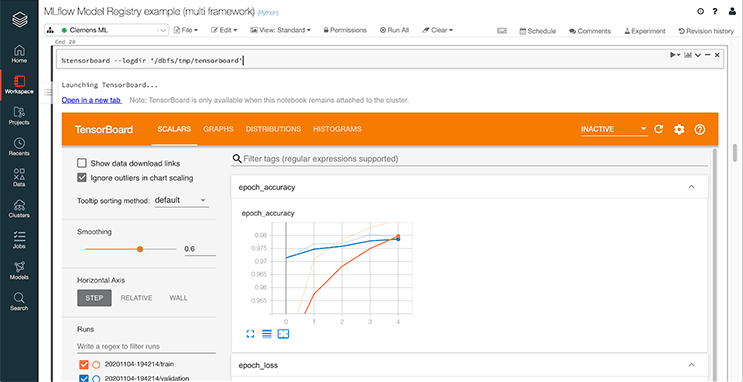
New TensorBoard support
TensorFlow and Keras are widely popular deep learning frameworks, and chances are that you'd like to use the TensorFlow backend for Keras. Now you can embed TensorBoard directly into your notebook, so you can monitor your training progress right in context.
New Table-of-Contents
Because Notebooks can become quite long, the new Table-of-Contents feature uses Markdown headings to allow you to easily navigate through a notebook. The notebook example below trains a Keras model, and you can see how you can now quickly navigate to that section.
Introducing Dark Mode
Finally, we're very excited to introduce Dark Mode on Databricks. We know a lot of our users are as excited about this feature as we are. Simply go to User Settings > Notebook Settings > and Turn on Dark Mode for notebook editor to flip the switch.
Many people think that such a collaborative platform can only be useful for exploration and experimentation. It has proven difficult to combine the ease-of-use and collaborative features of notebooks with the rigor of large-scale production deployments. For managing code versioning, CI/CD, and production-grade deployments, the industry is already leveraging best practices for robust code management in complex settings, and they are Git based.
Therefore Git-based Databricks Projects fully integrate with the Git ecosystem to bring those best practices to data engineering and data science, where reproducibility is becoming more and more important.
Introducing nbformat support, diff view, and enterprise security features for Git-based Databricks Projects
Databricks Projects allow data scientists to use Git to carry out their work on Databricks, where they can access all of their data sets and use best of breed open-source tools in a secure and scalable environment. Today, we discussed new features coming soon to help data teams rapidly and confidently move experiments to production including native support for an open and standard notebook format (nbformat) to facilitate collaboration and interoperability, new diff view to easily compare code when merging branches, and enterprise security features to safeguard your intellectual property.
Native nbformat support for Databricks notebooks
Databricks Notebooks can already be exported into the ipynb file format, but one aspect of this is to support a rich data format that allows us to retain more metadata than just exporting source files.
Therefore, we have extended the nbformat that underlies ipynb, to retain some of the metadata from Databricks notebooks, so all your work gets saved and checked. So now, for example, Notebook Dashboards can be stored with the ipynb file.
By using ipynb, we wanted to ensure that you can benefit from the ecosystem around this open format. For example, most git providers can render ipynb files and give you a great code review experience.

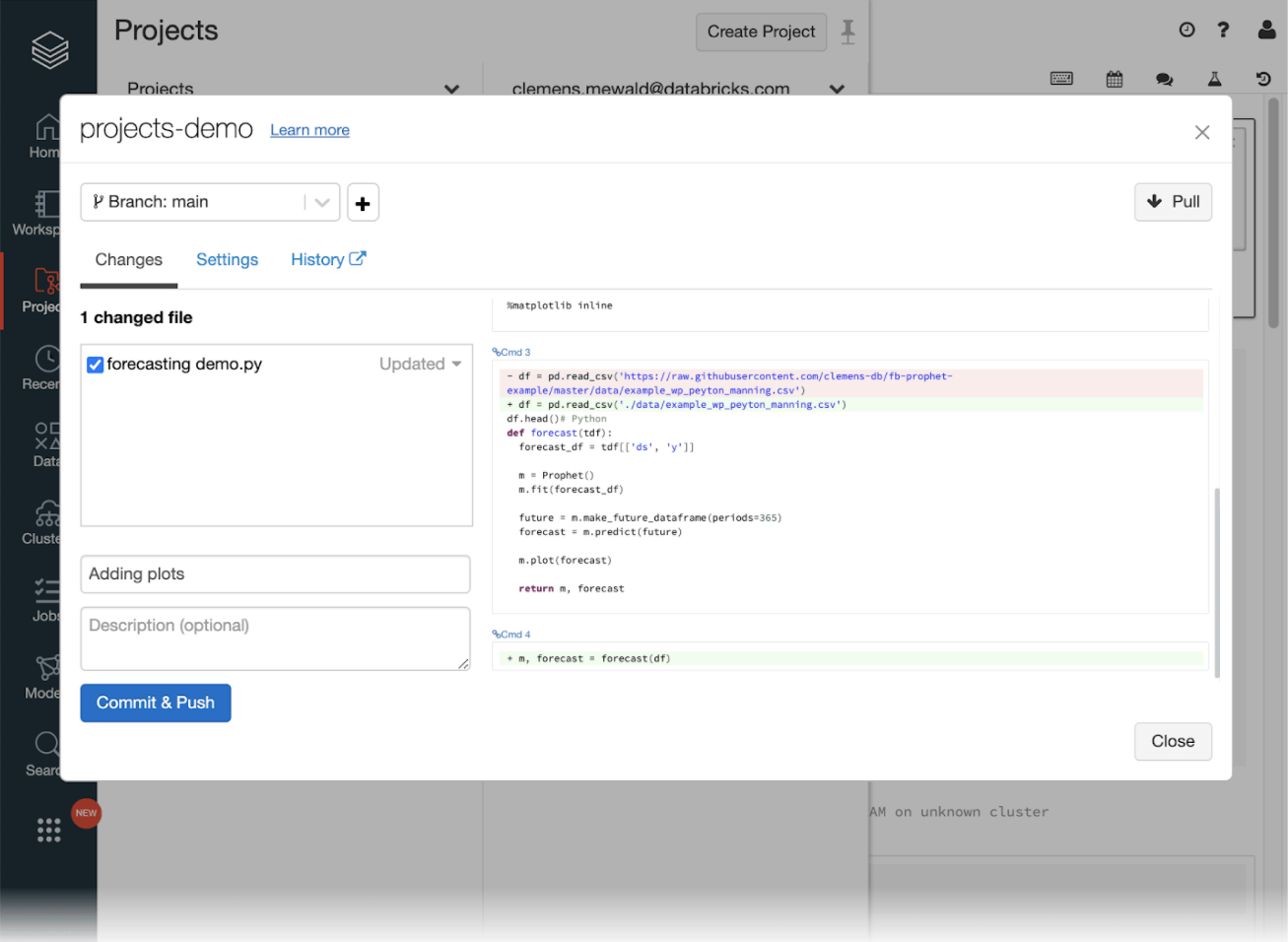
Staging and visual diff view
Once you’re done updating your code you can stage your files in the git dialog where we also added a visual diffing feature that allows you to preview pending changes.
This makes it much easier to decide which changes to check in, which to revert, or which still need some more work.
New Enterprise Security Features
To securely manage Git providers and what gets checked-in or checked-out, we've included new security features to help you protect your intellectual property.
Now admins can configure allow lists that specify which git providers and repositories users have access to. The most common use case for this is to avoid code making its way to public repositories.
Another common pitfall are unprotected secrets checked into your code. Databricks Projects will detect those before you actually commit your code, to avoid exposing tokens, keys, etc… and helping safeguard your credentials.
Next Steps
To learn more, you can watch today's keynote: Introducing the Next-Generation Data Science Workspace.
We have worked hard with many customers to design these new experiences, and are very excited to bring all these innovations to public preview in the next couple of months. Sign-up here for future updates and be notified of public preview!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.