Delta vs. Lambda: Why Simplicity Trumps Complexity for Data Pipelines
Get orders of magnitude performance gains for ETL pipelines by switching from Lambda to Delta architecture
by Hector Leano
“Everything should be as simple as it can be, but not simpler” - Albert Einstein
Generally, a simple data architecture is preferable to a complex one. Code complexity increases points of failure, requires more compute to run jobs, adds latency, and increases the need for support. As a result, data pipeline performance degrades over time, increasing costs while decreasing productivity as your data engineers spend more time troubleshooting and downstream users wait longer for data refreshes.
Complexity was perceived as a necessary evil for the automated data pipelines feeding business reporting, SQL analytics, and data science because the traditional approach for bringing together batch and streaming data required a lambda architecture. While a lambda architecture can handle large volumes of batch and streaming data, it increases complexity by requiring different code bases for batch and streaming, along with its tendency to cause data loss and corruption. In response to these data reliability issues, the traditional data pipeline architecture adds even more complexity by adding steps like validation, reprocessing for job failures, and manual update & merge.
While you can fine-tune the cost or performance of individual services, you cannot make significant (orders of magnitude) improvements in cost or performance for the total job in this architecture.
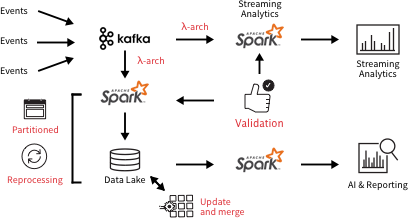
Typical data pipeline architecture requiring additional functions like validation, reprocessing, and updating & merging, adding latency, cost, and points of failure.
However, the Delta Architecture on Databricks is a completely different approach to ingesting, processing, storing, and managing data focused on simplicity. All the processing and enrichment of data from Bronze (raw data) to Silver (filtered) to Gold (fully ready to be used by analytics, reporting, and data science) happens within Delta Lake, requiring less data hops.
Lambda is complicated, requiring more to set up and maintain, whereas batch + streaming just work on Delta tables right out of the box. Once you’ve built a Bronze table for your raw data and converted existing tables to Delta Lake format, you’ve already solved the data engineer’s first dilemma: combining batch and streaming data. From there, data flows into Silver tables, where it is cleaned and filtered (e.g., via schema enforcement). By the time it reaches our Gold tables it receives final purification and stringent testing to make it ready for consumption for creating reports, business analytics, or ML algorithms. You can learn more about simplifying lambda architectures in our virtual session, Beyond Lambda: Introducing Delta Architecture.
Read Rise of the Data Lakehouse to explore why lakehouses are the data architecture of the future with the father of the data warehouse, Bill Inmon.
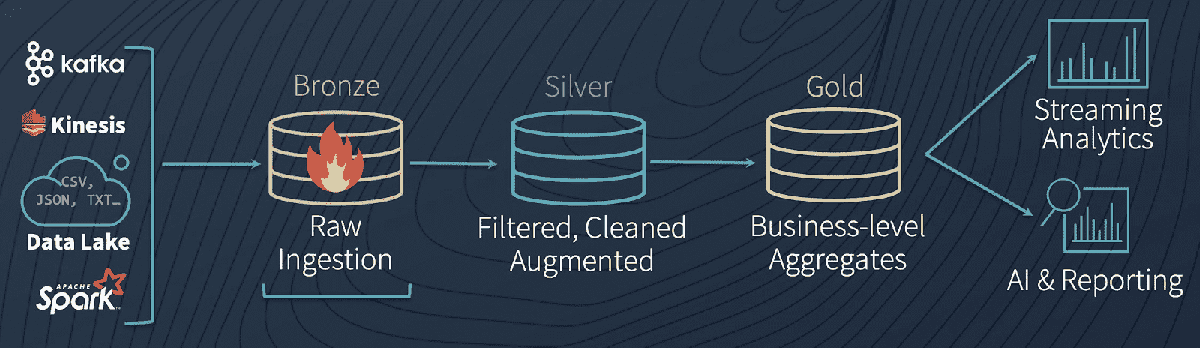
The simplicity of the Delta Architecture on Databricks from ingest to downstream use. This simplicity is what lowers cost while increasing the reliability of automated data pipelines.
These are the advantages that the simplified Delta Architecture brings for these automated data pipelines:
- Lower costs to run your jobs reliably: By reducing 1) the number of data hops, 2) the amount of time to complete a job, 3) the number of job fails, and 4) the cluster spin-up time, the simplicity of the Delta architecture cuts the total cost of ETL data pipelines. While we certainly run our own benchmarks, the best benchmark is your data running your queries. To understand how to evaluate benchmark tests for automated data pipelines, read our case study for how Germany’s #1 weather portal, wetter.com, evaluated different pipeline architectures, or reach out to sales@databricks.com to get your own custom analysis.
- Single source of truth for all downstream users: In order to have data in a useful state for reporting and analytics, enterprises will often take the raw data from their data lake and then copy and process a small subset into a data warehouse for downstream consumption. These multiple copies of the data create versioning and consistency issues that can make it difficult to trust the correctness and freshness of your data. Databricks however serves as a unified data service, providing a single source of consumption feeding downstream users directly or through your preferred data warehousing service. As new use cases are tested and rolled out for the data, instead of having to build new, specialized ETL pipelines, you can simply query from the same Silver or Gold tables.
- Less code to maintain: In order to ensure all data has been ingested and processed correctly, the traditional data pipeline architecture approach needs additional data validation and reprocessing functions. Lambda architecture isn’t transactional, so if your data pipeline write job fails halfway through, now you have to manually figure out what happened / fix it / deal with partial write or corrupted data. With Delta on Databricks however you ensure data reliability with ACID transactions and data quality guarantees. As a result, you end up with a more stable architecture, making troubleshooting much easier and more automated. When Guosto rebuilt their ETL pipelines on Databricks, they noted that, “a good side effect was the reduction in our codebase complexity. We went from 565 to 317 lines of Python code. From 252 lines of YML configuration to only 23 lines. We also don't have a dependency on Airflow anymore to create clusters or submit jobs, making it easier to manage.”
- Merge new data sources with ease: While we have seen an increase in alternative data sources (e.g., IoT or geospatial), the traditional way of building pipelines makes them highly rigid. Layering in new data sources to, for example, better understand how new digital media ads impact foot traffic to brick & mortar locations, typically means several weeks or months of re-engineering. Delta Lake’s schema evolution makes merging new data sources (or handling changes in formats of existing data sources) simple.
In the end, what the simplicity of Delta Architecture means for developers is less time spent stitching technology together and more time actually using it.
To see how Delta can help simplify your data engineering, drop us a line at sales@databricks.com.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.