Enforcing Column-level Encryption and Avoiding Data Duplication With PII
Using Fernet encryption libraries, UDFs, and Databricks secrets to unobtrusively secure PII data
by Keyuri Shah and Fred Kimball
This is a guest post by Keyuri Shah, lead software engineer, and Fred Kimball, software engineer, Northwestern Mutual.
Protecting PII (personally identifiable information) is very important as the number of data breaches and records with sensitive information exposed every day are trending upwards. To avoid becoming the next victim and protect users from identity theft and fraud, we need to incorporate multiple layers of data and information security.
As we use the Databricks platform, we need to make sure we are only allowing the right people access to sensitive information. Using a combination of Fernet encryption libraries, user-defined functions (UDFs), and Databricks secrets, Northwestern Mutual has developed a process to encrypt PII information and allow only those with a business need to decrypt it, with no additional steps needed by the data reader.
The need for protecting PII
Managing any amount of customer data these days almost certainly requires protecting PII. This is a large risk for organizations of all sizes as cases such as the Capital One data breach resulted in millions of sensitive customer records being stolen due to a simple configuration mistake. While encryption of the storage device and column-masking at the table level are effective security measures, unauthorized internal access to this sensitive data still poses a major threat. Therefore, we need a solution that restricts a normal user with file or table access from retrieving sensitive information within Databricks.
However, we also need those with a business need to read sensitive information to be able to do so. We don’t want there to be a difference in how each type of user reads the table. Both normal and decrypted reads should happen on the same Delta Lake object to simplify query construction for data analysis and report construction.
Building the process to enforce Column-level Encryption
Given these security requirements, we sought to create a process that would be secure, unobtrusive, and easy to manage. The below diagram provides a high-level overview of the components required for this process
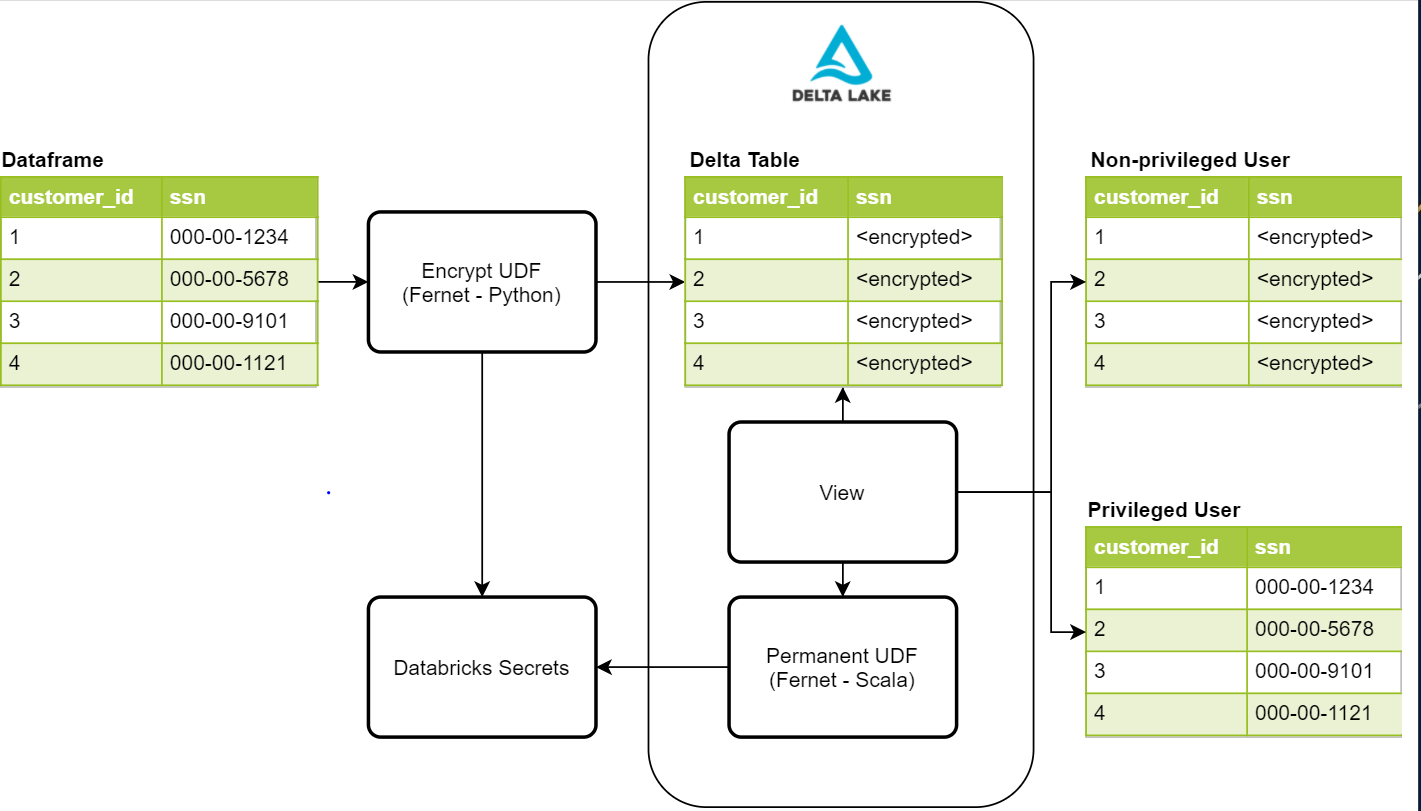
Writing protected PII with Fernet
The first step in this process is to protect the data by encrypting it. One possible solution is the Fernet Python library. Fernet uses symmetric encryption, which is built with several standard cryptographic primitives. This library is used within an encryption UDF that will enable us to encrypt any given column in a dataframe. To store the encryption key, we use Databricks Secrets with access controls in place to only allow our data ingestion process to access it. Once the data is written to our Delta Lake tables, PII columns holding values such as social security number, phone number, credit card number, and other identifiers will be impossible for an unauthorized user to read.
Reading the protected data from a view with custom UDF
Once we have the sensitive data written and protected, we need a way for privileged users to read the sensitive data. The first thing that needs to be done is to create a permanent UDF to add to the Hive instance running on Databricks. In order for a UDF to be permanent, it must be written in Scala. Fortunately, Fernet also has a Scala implementation that we can leverage for our decrypted reads. This UDF also accesses the same secret we used in the encrypted write to perform the decryption, and, in this case, it is added to the Spark configuration of the cluster. This requires us to add cluster access controls for privileged and non-privileged users to control their access to the key. Once the UDF is created, we can use it within our view definitions for privileged users to see the decrypted data.
Currently, we have two view objects for a single dataset, one each for privileged and non-privileged users. The view for non-privileged users does not have the UDF, so they will see PII values as encrypted values. The other view for privileged users does have the UDF, so they can see the decrypted values in plain text for their business needs. Access to these views is also controlled by the table access controls provided by Databricks.
In the near future, we want to leverage a new Databricks feature called dynamic view functions. These dynamic view functions will allow us to use only one view and easily return either the encrypted or decrypted values based on the Databricks group they are a member of. This will reduce the amount of objects we are creating in our Delta Lake and simplify our table access control rules.
Either implementation allows the users to do their development or analysis without worrying about whether or not they need to decrypt values read from the view and only allows access to those with a business need.
Advantages of this method of column-level encryption
In summary, the advantages of using this process are:
- Encryption can be performed using existing Python or Scala libraries
- Sensitive PII data has an additional layer of security when stored in Delta Lake
- The same Delta Lake object is used by users with all levels of access to said object
- Analysts are unobstructed whether or not they are authorized to read PII
For an example of what this may look like, the following notebook may provide some guidance:
Additional resources:
Fernet Libraries
Create Permanent UDF
Dynamic View Functions
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.