Introducing Databricks on Google Cloud - Now in Public Preview
by Hiral Jasani
Last month, we announced Databricks on Google Cloud, a jointly-developed service that allows data teams (data engineering, data science, analytics, and ML professionals) to store data in a simple, open lakehouse platform for all data, AI and analytics workloads. Today, we are launching the public preview of Databricks on Google Cloud.
When speaking to our customers, one thing is clear: they want to build modern data architectures to drive real business impact, whether that’s by personalizing customer experiences with ML, improving in-product gaming experience or delivering life-saving medical supplies (just to name a few). But many find themselves bogged down with unmanageable amounts of data across data types – structured, unstructured, and semi-structured data – while simultaneously dealing with a variety of applications. For just the day-to-day work, data teams must stitch together various open source libraries and tools for further analytics. Multiple handoffs between data science, ML engineering and deployment teams slow down development. Complexity and cost of transferring data between multiple disparate data systems and challenges managing multiple copies of data and security models add to the overhead.
With these pain points in mind, we believe the way to build a best-in-class Lakehouse platform is to build with open standards. Open standards, open APIs, open platform -- it gives customers the choice to build their modern data architecture based on services with a simple, collaborative experience. Google Cloud shares this “vision of openness” with an open cloud service, meaning our joint customers have the choice to choose the right set of tools to solve any problem.
Open data lake with Delta Lake and Google Cloud Storage
The open technology that allows us to unify analytics and artificial intelligence (AI) with a lakehouse on top of your existing data lake is Delta Lake. Data lakes are an affordable way to store large amounts of raw data (structured, unstructured, video, text, audio), often in open source formats such as the widely-used Apache Parquet. Yet, many companies struggle to run their analytics and AI applications in production as they face many of the challenges listed below.
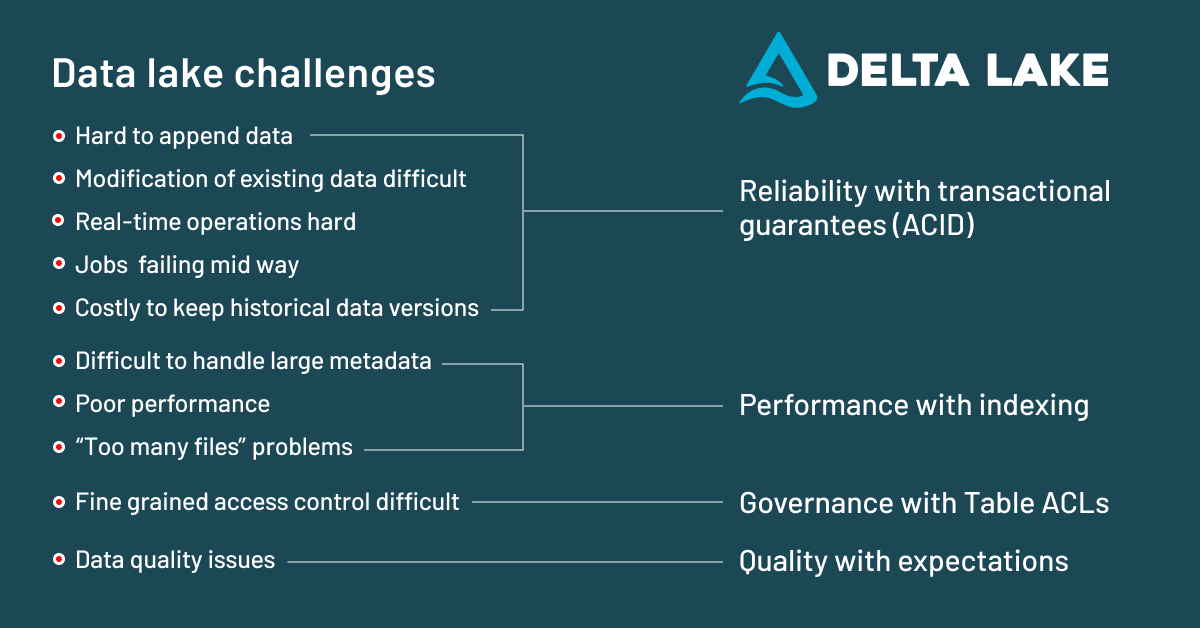
Delta Lake is an open format storage layer that delivers reliability, performance and governance to solve these data lake challenges. Databricks on Google Cloud is based on Delta Lake and the Parquet format, so you can keep all your data in Google Cloud Storage (GCS) without having to move it or copy it in several places. This allows you to store and manage all your data for analytics on your data lake.
Faster experimentation with easy-to-use ML & AI services
Once you have an open data lake, you have laid the foundation for your data science teams to develop and train their machine learning models. With the availability of Databricks on Google Cloud, data scientists and ML engineers can use our collaborative data science and managed MLflow capabilities with the data in Google Cloud Storage or BigQuery Storage.
Databricks on Google Cloud is also integrated with Google Cloud’s suite of AI services. For example, you can deploy MLflow models to AI Platform Predictions for online serving or use AI Platform’s pre-trained ML APIs and AutoML for vision, video, translation and natural language processing.
Conclusion
Databricks on Google Cloud brings a shared vision to combine the open platform with the open cloud for simplified data engineering, data science and data analytics. Want to learn more about how this joint solution unifies all your analytics and AI workloads? Register for our launch event with Databricks CEO & Co-founder Ali Ghodsi and Google Cloud CEO Thomas Kurian for a deep dive into the benefits of an open Lakehouse platform and how Databricks on Google Cloud drive data team collaboration.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.