Benchmark: Koalas (PySpark) and Dask
by Xinrong Meng and Hyukjin Kwon
Koalas is a data science library that implements the pandas APIs on top of Apache Spark so data scientists can use their favorite APIs on datasets of all sizes. This blog post compares the performance of Dask’s implementation of the pandas API and Koalas on PySpark. Using a repeatable benchmark, we have found that Koalas is 4x faster than Dask on a single node, 8x on a cluster and, in some cases, up to 25x.
First, we walk through the benchmarking methodology, environment and results of our test. Then, we discuss why Koalas/Spark is significantly faster than Dask by diving into Spark’s optimized SQL engine, which uses sophisticated techniques such as code generation and query optimizations.
Methodology
The benchmark was performed against the 2009 - 2013 Yellow Taxi Trip Records (157 GB) from NYC Taxi and Limousine Commission (TLC) Trip Record Data. We identified common operations from our pandas workloads such as basic statistical calculations, joins, filtering and grouping on this dataset.
Local and distributed execution were also taken into account in order to cover both single node cases and cluster computing cases comprehensively. The operations were measured with/without filter operations and caching to consider various real-world workloads.
Therefore, we performed the benchmark in the dimensions below:
- Standard operations (local & distributed execution)
- Operations with filtering (local & distributed execution)
- Operations with filtering and caching (local & distributed execution)
Dataset
The yellow taxi trip record dataset contains CSV files, which consist of 17 columns with numeric and text types. The fields include pick-up and drop-off dates/times, pick-up and drop-off locations, trip distances, itemized fares, rate types, payment types and driver-reported passenger counts. The CSV files were downloaded into Databricks File System (DBFS), and then were converted into Parquet files via Koalas for better efficiency.
Operations
We analyzed multiple existing pandas workloads and identified several patterns of common operations. Below is some pseudocode of the derived operations.
The operations were executed with/without filtering and caching respectively, to consider the impact of lazy evaluation, caching and related optimizations in both systems, as shown below.
- Standard operations
- Operations with filtering
- The filter operation finds the records that received a tip between $1 - 5 dollars, and it filters down to 36% of the original data.
- Operations with filtering and caching
- When caching was enabled, the data was fully cached before measuring the operations.
For the entire code used in this benchmark, please refer to the notebooks included on the bottom of this blog.
Environment
The benchmark was performed on both a single node for local execution, as well as a cluster with 3 worker nodes for distributed execution. To set the environment up easily, we used Databricks Runtime 7.6 (Apache Spark 3.0.1) and Databricks notebooks.
System environment
- Operating System: Ubuntu 18.04.5 LTS
- Java: Zulu 8.50.0.51-CA-linux64 (build 1.8.0_275-b01)
- Scala: 2.12.10
- Python: 3.7.5
Python libraries
- pandas: 1.1.5
- PyArrow: 1.0.1
- NumPy: 1.19.5
- Koalas: 1.7.0
- Dask: 2021.03.0
Local execution
For local execution, we used a single i3.16xlarge VM from AWS that has 488 GB memory and 64 cores with 25 Gigabit Ethernet.

Distributed execution
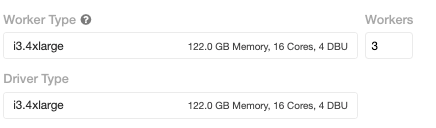
For distributed execution, 3 worker nodes were used with a i3.4xlarge VM that has 122 GB memory and 16 cores with (up to) 10 Gigabit Ethernet. This cluster has the same total memory as the single-node configuration.
Results
The benchmark results below include overviews with geometric means to explain the general performance differences between Koalas and Dask, and each bar shows the ratio of the elapsed times between Dask and Koalas (Dask / Koalas). Because the Koalas APIs are written on top of PySpark, the results of this benchmark would apply similarly to PySpark.
Standard operations
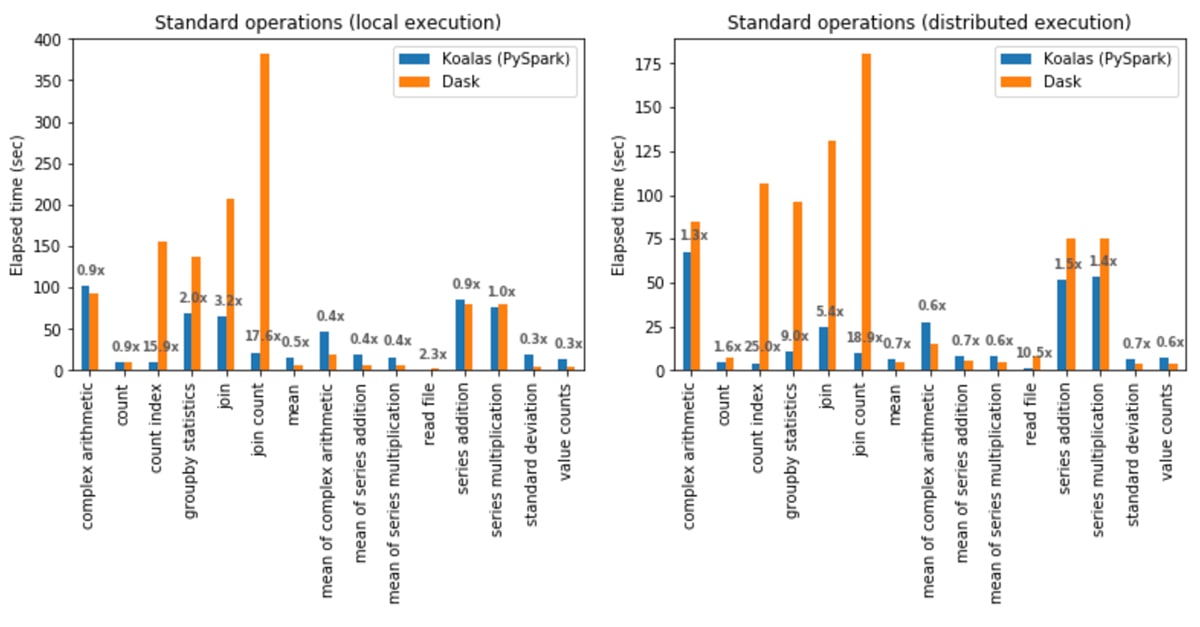
In local execution, Koalas was on average 1.2x faster than Dask:
- In Koalas, join with count (join count) was 17.6x faster.
- In Dask, computing the standard deviation was 3.7x faster.
In distributed execution, Koalas was on average 2.1x faster than Dask:
- In Koalas, the count index operation was 25x faster.
- In Dask, the mean of complex arithmetic operations was 1.8x faster.
Operations with filtering
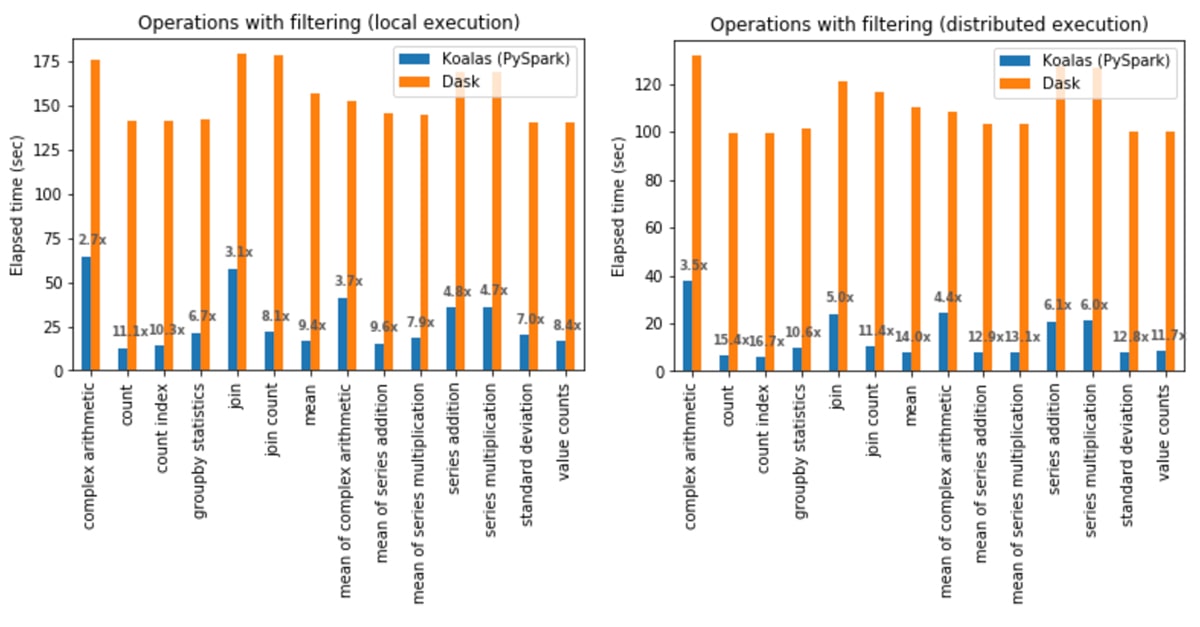
In local execution, Koalas was on average 6.4x faster than Dask in all cases:
- In Koalas, the count operation was 11.1x faster.
- Complex arithmetic operations had the smallest gap in which Koalas was 2.7x faster.
In distributed execution, Koalas was on average 9.2x faster than Dask in all cases:
- In Koalas, the count index operation was 16.7x faster.
- Complex arithmetic operations had the smallest gap in which Koalas was 3.5x faster.
Operations with filtering and caching
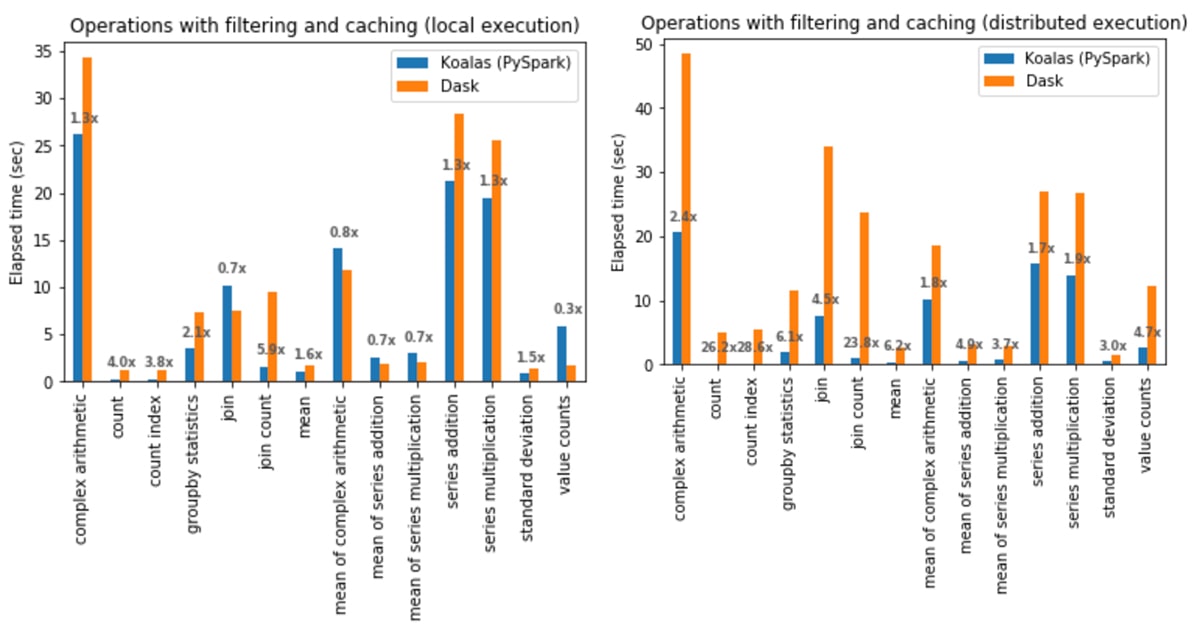
In local execution, Koalas was on average 1.4x faster than Dask:
- In Koalas, join with count (join count) was 5.9x faster.
- In Dask,
Series.value_counts(value counts) was 3.6x faster.
In distributed execution, Koalas was on average 5.2x faster than Dask in all cases:
- In Koalas, the count index operation was 28.6x faster.
- Complex arithmetic operations had the smallest gap in which Koalas was 1.7x faster.
Analysis
Koalas (PySpark) was considerably faster than Dask in most cases. The reason seems straightforward because both Koalas and PySpark are based on Spark, one of the fastest distributed computing engines. Spark has a full optimizing SQL engine (Spark SQL) with highly-advanced query plan optimization and code generation. As a rough comparison, Spark SQL has nearly a million lines of code with 1600+ contributors over 11 years, whereas Dask’s code base is around 10% of Spark’s with 400+ contributors around 6 years.
In order to identify which factors contributed to Koalas’ performance the most out of many optimization techniques in Spark SQL, we analyzed these operations executed in distributed manner with filtering when Koalas outperformed Dask most:
- Statistical calculations
- Joins
We dug into the execution and plan optimization aspects for these operations and were able to identify the two most significant factors: code generation and query plan optimization in Spark SQL.
Code generation
One of the most important execution optimizations in Spark SQL is code generation. The Spark engine generates optimized bytecodes for each query at runtime, which greatly improves performance. This optimization considerably affected statistical calculations and joins in the benchmark for Koalas by avoiding virtual function dispatches, etc. Please read the code generation introduction blog post to learn more.
For example, the same benchmark code of mean calculation takes around 8.37 seconds and the join count takes roughly 27.5 seconds with code generation disabled in a Databricks production environment. After enabling the code generation (on by default), calculating the mean takes around 1.26 seconds and the join count takes 2.27 seconds. It is an improvement of 650% and 1200%, respectively.
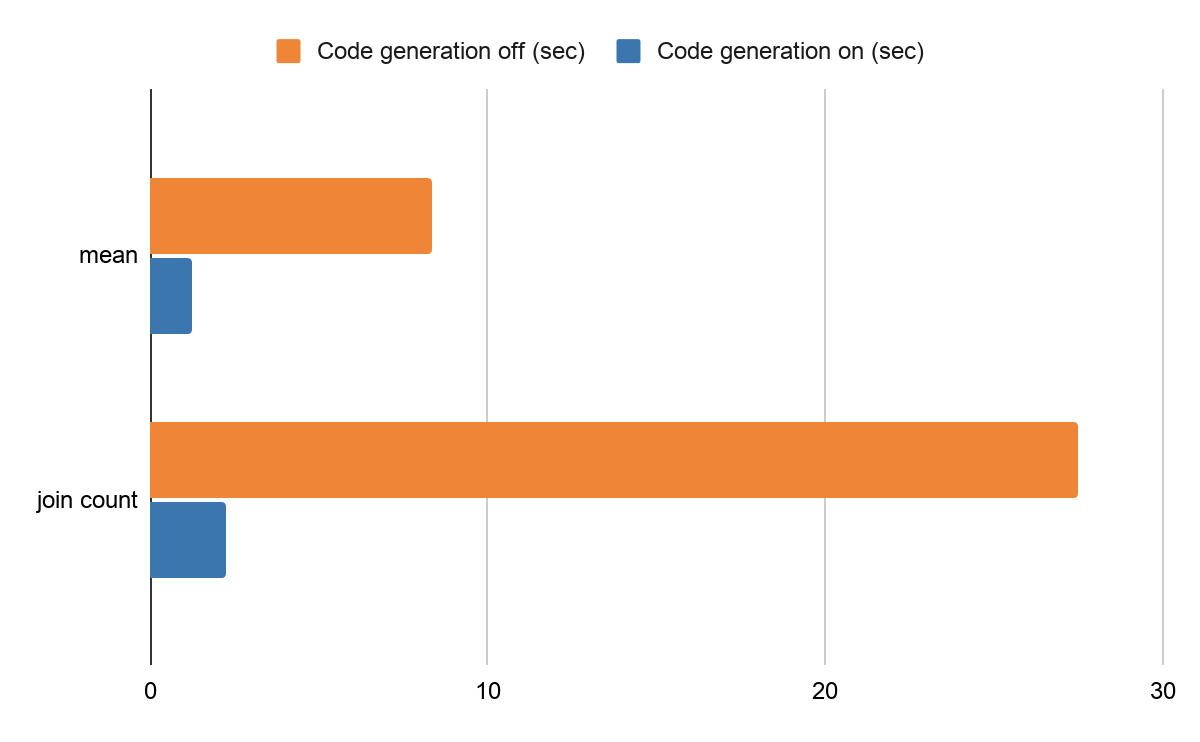
Performance difference by code generation
Query plan optimization
Spark SQL has a sophisticated query plan optimizer: Catalyst, which dynamically optimizes the query plan throughout execution (Adaptive query execution). In Koalas’ statistics calculations and join with filtering, the Catalyst optimizer also significantly improved the performance.
When Koalas computes the mean without leveraging the Catalyst query optimization, the raw execution plan in Spark SQL is roughly as follows. It uses brute-force to read all columns, and then performs projection multiple times with the filter in the middle before computing the mean.
It applies not only column pruning and filter pushdown but also removes the shuffle step by broadcasting the smaller DataFrame. Internally, it sends the smaller DataFrame to each executor, and performs joins without exchanging data. This removes an unnecessary shuffle and greatly improves the performance.
Conclusion
The results of the benchmark demonstrated that Koalas (PySpark) significantly outperforms Dask in the majority of use cases, with the biggest contributing factors being Spark SQL as the execution engine with many advanced optimization techniques.
Koalas' local and distributed executions of the identified operations were much faster than Dask's as shown below:
- Local execution: 2.1x (geometric mean) and 4x (simple average)
- Distributed execution: 4.6x (geometric mean) and 7.9x (simple average)
Secondly, caching impacted the performance of both Koalas and Dask, and it reduced their elapsed times dramatically.
Lastly, the biggest performance gaps were shown in the distributed execution for statistical calculations and joins with filtering, in which Koalas (PySpark) was 9.2x faster at all identified cases in geometric mean.
We have included the full self-contained notebooks, the dataset and operations, and all settings and benchmark codes for transparency. Please refer to the notebooks below:
- Dataset
- Standard operations (local execution)
- Standard operations (distributed execution)
- Operations with filtering (local execution)
- Operations with filtering (distributed execution)
- Operations with filtering and caching (local execution)
- Operations with filtering and caching (distributed execution)
- Local execution summary
- Distributed execution summary
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.