How Outreach Productionizes PyTorch-based Hugging Face Transformers for NLP
by Andrew Brooks, Yong-Gang Cao and Yong Liu
This is a guest blog from the data team at Outreach.io. We thank co-authors Andrew Brooks, staff data scientist (NLP), Yong-Gang Cao, machine learning engineer, and Yong Liu, principal data scientist, of Outreach.io for their contributions.
At Outreach, a leading sales engagement platform, our data science team is a driving force behind our innovative product portfolio largely driven by deep learning and AI. We recently announced enhancements to the Outreach Insights feature, which is powered by the proprietary Buyer Sentiment deep learning model developed by the Outreach Data Science team. This model allows sales teams to deepen their understanding of customer sentiment through the analysis of email reply content, moving from just counting the reply rate to classification of the replier’s intent.
We use four primary classifications for email reply content: positive, objection, unsubscribe and referral, as well as finer sub-classifications. For example, for replies classified as an objection, we can break down how many replies are due to budget constraints vs. procurement timing issues. This is a gamechanger for the sales team, as it provides actionable insights for sales managers to coach their Sales Representatives to improve their strategies and performance.
This blog describes the technical details on how we develop the Buyer Sentiment deep learning model, which is a multiclass classifier for sales engagement email messages. In particular, we will explain an offline model development/experimentation, productionization and deployment steps.
Overview of an ML model lifecycle: development and production
As discussed in many recent articles, the development of a machine learning (ML) model requires three major artifacts: data, model and code. To successfully develop and ship a ML model in production, we need to embrace the full lifecycle development for ML projects. Figure 1 is a schematic view of Outreach’s full lifecycle development and production path, starting from data annotation to offline model development/experimentation, model productionization (model-preproduction), model deployment (staging and production) and, finally, online model monitoring and feedback loops. Databricks is used in model dev/pre-prod and CI/CD pipelines as execution servers (e.g., using GPU clusters in Databricks for model training).
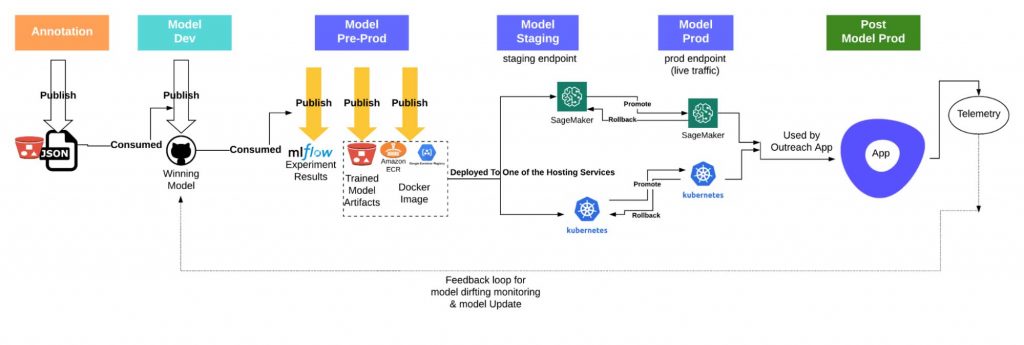
Figure 1: Full Lifecycle View of Model Development and Production at Outreach
During the offline model development/experimentation stage (i.e., Model Dev step as labeled in Figure 1), we tried different types of ML models, such as SVM, FastText and Pytorch-based Hugging Face transformers. Based on our requirements (classification f1 scores initially for the English language, with multiple languages planned for the longer term), we settled on using Pytorch-based Hugging Face transformer (bert-uncased-small) for its high-performance classification results1).
However, productizing a prototype is still one of the most painful experiences faced by ML practitioners. You can trade speed for discipline by enforcing production-grade standards from the very beginning. However, this is often premature optimization, as ML models require many iterations and nonlinear processes, and many fail or substantially pivot before they ever ship. You can also trade engineering discipline for maximum flexibility from day one. However, this makes the journey from prototype to production more painful once complexity reaches a tipping point where marginal costs exceed marginal gains from each new enhancement.
The trade-off between discipline and flexibility is somewhere in the middle. For us, that means we don’t directly ship our prototype code and experiments, but we enforce the minimal amount of structure needed to 1) register results from each prototype experiment, so we don’t need to repeat them, especially unsuccessful experiments; 2) link prototype experiment results to source code, so we know what logic produced them and ensure reproducibility; and 3) enable historical prototype models to be loaded for offline analysis.
Experiment, test, and deploy with MLflow Projects
Based on our full lifecycle analysis, we use MLflow Projects as the common thread between model development and deployment to achieve this trade-off. MLflow Projects is a reasonably lightweight layer that centralizes and standardizes entry points and environment definitions with a self-documenting framework.
Why we use MLflow Project:
MLflow projects add virtually no weight to your project, especially if you’re already using MLflow Tracking and MLflow Models, for which there are built-in integrations.
- Smooth execution of code developed in IDE of choice.
→ Support for running Databricks notebooks is first-class, but it can be cumbersome to run scripts. MLflow Project provides a smooth CLI for running .py and .sh files without unnecessary overhead like creating Apache Spark™ or Databricks jobs. - Strong provenance tracing from source code to model results.
→ Ability to run a script from a GitHub commit without pulling down code or losing provenance on local uncommitted code. - Flexibility to prototype locally and then scale to remote clusters
→ The MLflow Project API enables users to toggle from local to remote execution with the --backend argument, which points to a Databricks or kubernetes JSON cluster config created for a single-use operation. Dependencies are handled in code (Conda) rather than state (manually configured cluster), ensuring reproducibility.
Model development mirrors CI/CD pattern
→ While we refactor experiment code before deploying, the CI/CD pipeline invokes the train, test, and deploy pipeline following the same pattern from model development, so minimal “extra�” effort must go from prototype experiment to production. The ML model artifacts (binaries, results, etc.) and deployment status are centralized into one system, which eases debugging by smoothing provenance tracking back from production traffic and incidents.
How to use:
- Run local code locally (no provenance)
mlflow run ./ train - Run remote code locally (provenance, but bound by local compute)
mlflow run https://github.com/your-GH/your-repo train --version 56a5aas - Run remote code on a cluster (provenance + compute at scale)
mlflow run https://github.com/your-GH/your-repo train --config gpu_cluster_type.json --version 56a5aas
Three progressively wrapped model artifacts
One of our key considerations when developing a productionizable model is not just the model type (a fine-tuned Pytorch-based Huggingface transformer model), but also the pre/post-process steps and the internally developed Python libraries that are used by the pre/post-process steps. We took a rigorous approach to treat the entire model pipeline as a single serializable artifact in the MLflow artifact store without external dependencies on accessing a GitHub repo at deployment time. We use the scikit-learn Pipeline API for the model pipeline implementation, which is the most widely-used Python library for ML pipeline building. This opens doors to integrate other pre/post-processing steps that are also scikit-learn pipeline API compliant. Additional advantages of using this pipeline approach include preventing data leaking and maintaining reproducibility.
Taking this approach resulted in three progressively wrapped model artifacts: a fine-tuned PyTorch transformer model that implements scikit-learn baseEstimator and ClassifierMixin APIs, a scikit-learn Pipeline API compatible model pipeline that includes additional pre/post-processing steps (which we called pre-score filter and post-score filter) and a model pipeline that uses only locally bundled Python libraries without accessing any Github repos (Figure 2). Note that in the pre-score filter, we could add extra steps such as caching (for the same email message, we can serve the same prediction) and filtering out certain types of messages (e.g., bypassing those out-of-office messages). Similarly, in the post-score filter step, we can return the prediction and additional provenance tracking information about model versions and detailed score probabilities for the endpoint consumer app to use.
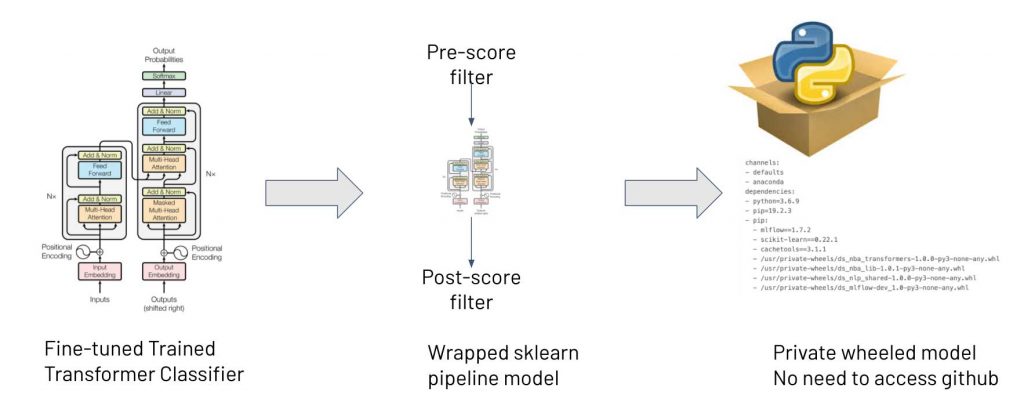
Figure 2: Three progressively wrapped models for deployment
Embrace the automation, CI/CD and monitoring
Like any other software system, the most boring, painful and error-prone part is the repetitive maintenance work in a machine learning system. Continuous Integration and Continuous Deployment/Delivery (CI/CD) is designed to bring automation and guard rails into a workflow – from building to deployments. We designed two flows (Figure 3); one serves a quick sanity check round for each pushed commit, which takes under 30 minutes. The other prepares, checks and deploys the entire model, which takes a few hours. (Note: You can watch this video for more details on utilizing MLflow and Databricks):
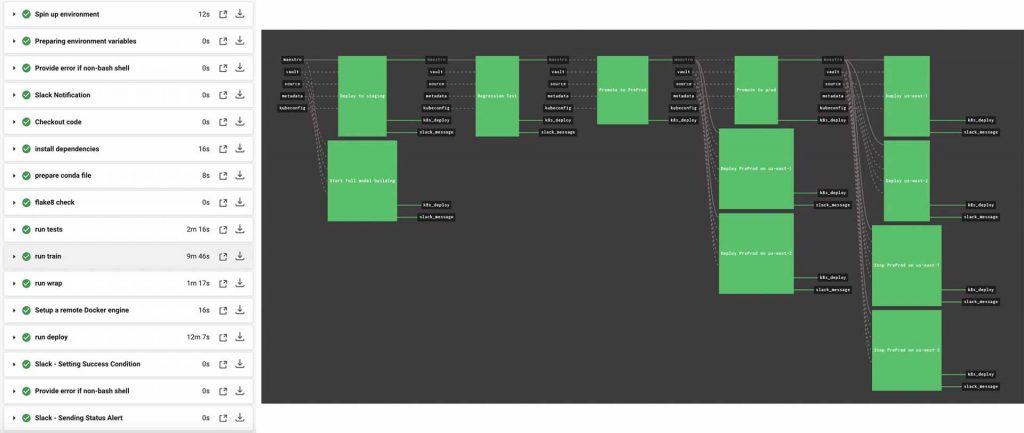
Figure 3: CI/CD flows
Integration with tools
As a SaaS company, Outreach has a wide choice of SaaS and open source tools to leverage. While most of our internal services use Ruby or Go languages, the data science team opted to use Python, Databricks and MLflow for at-scale job runs. Thus, there was a need to create piping and integrations for all those tools almost from scratch. We dynamically generate conda and Databricks cluster config files for MLflow runs and put effort into synchronizing each step to construct the flows. We even weaved CircleCI and Concourse together to let them trigger each other (the same CircleCI flow is reused in CD for entire model building with different behaviors).
To do those, we exploited most capabilities of APIs from service providers – thanks to the excellent documentation from providers, open-source code from Databricks and support from both internal and external teams. There were several pitfalls, including version issues over time. Still, the caveat here is that all the tools we chose were originally not designed or tested to work together. It was up to us to overcome those initial drawbacks and provide feedback to the providers to allow them to work together.
Version controls
No matter which programming languages you use, one big headache is dependency complexity. Any version change in the deep dependency graph can be a danger for the production system. In our CI/CD, we scan and freeze all versions and bundle all dependency binaries and models into the Docker image we use for deployments so that nothing changes in the production environment. Once the image is deployed, it’s no longer affected by external dependencies. We versioned our data in Amazon S3 and built models at different stages via Model Registry provided by MLflow.
Guarded and staged model releases
As you can see from our CI/CD flows, we added several guard-rail steps along with staged environments for deployments. Besides regular flake8-based style checks, unit tests and liveness checks, we automated and verified the entire lifecycle, from training to the endpoint test after the deployment of images for each commit (in less than half an hour). For the full model check (except for the stage environment), we created a pre-prod environment with identical resources with prod for canary test and staged release purposes (beta launch of new models). Beyond that, we also added a regression test step for a thorough examination against large datasets (around one hour load and quality tests) to ensure all quality and throughput variances would be captured before we proceed for beta or production release.
As a final defense, we also added human checkpoints against the regression test results or pre-production results to confirm the promotion of changes beyond automated threshold checks. To assist the understanding of the real-world impact of changes, besides producing overall metrics and utilizing MLflow for side-by-side comparisons, we made a polished visualization of the confusion matrix (Figure 4) from a logistic regression test, as MLflow hosted image artifacts to assist the comparison and judgments with details (true positive, false positive, false negative numbers and rates on each label and axis with colors for emphasis) since overall metrics don’t tell all the dangers to individual categories but do tell the error types. The human check could be lifted once we accumulated enough experiences from multiple upgrades/iterations, and those data points could be used for later automation.
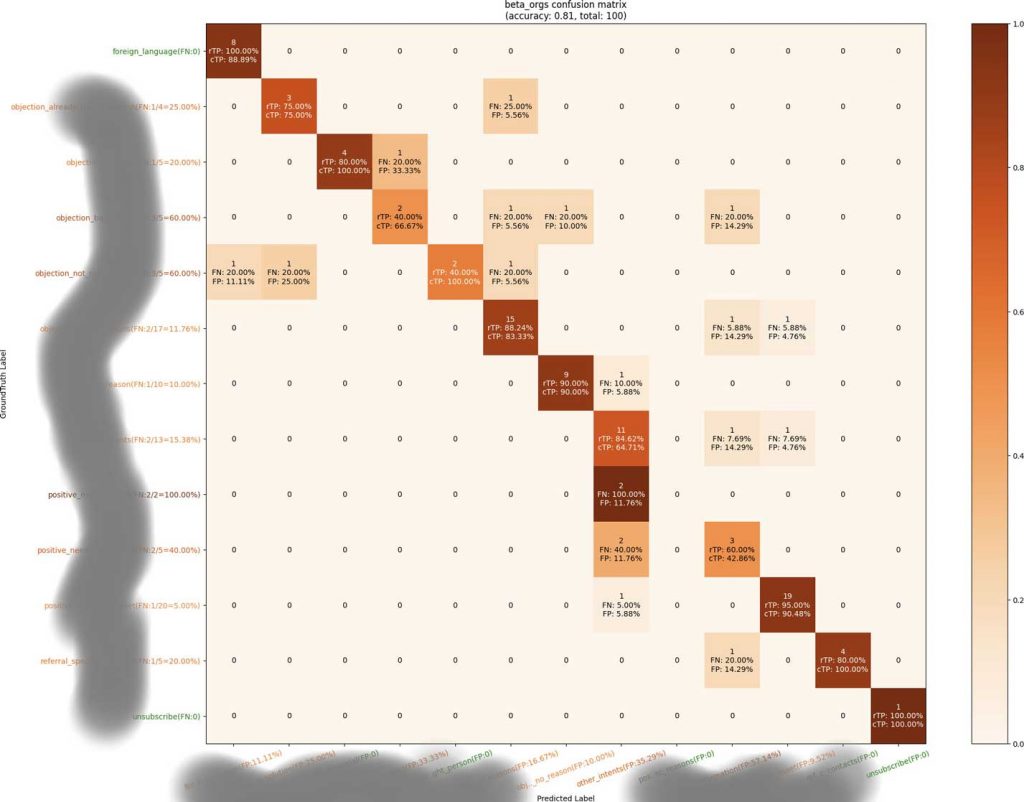
Figure 4: Polished Visualization of Confusion Matrix for Predictions
Optimizing and monitoring of services
Having CI/CD to produce healthy service is just a start, but optimal running behavior and continuous health monitoring are must-haves. To optimize for obvious cases and repetitive cases, we added shortcuts and a cache layer on API to speed up serving. We initially used SageMaker for hosting our endpoints, but we found metrics related to model performance and results are minimal, so we switched to using Kubernetes and integration with Datadog for more in-depth monitoring. This brought us many advantages, including closer alignment with other internal teams, security, control and cost savings. Below are our Datadog dashboards that monitor all types of prediction trends over time, as well as latency percentiles at will. It also makes it easy to make an online prediction comparison between a new model and an old model by just one screen (e.g., when we split traffic to 50% on each, they are supposed to be statistically identical if models are the same). As you can see from the example dashboard (Figure 5), the built-in caching ability does play a positive role (the service latency could become nearly zero-second from time to time because of caching).
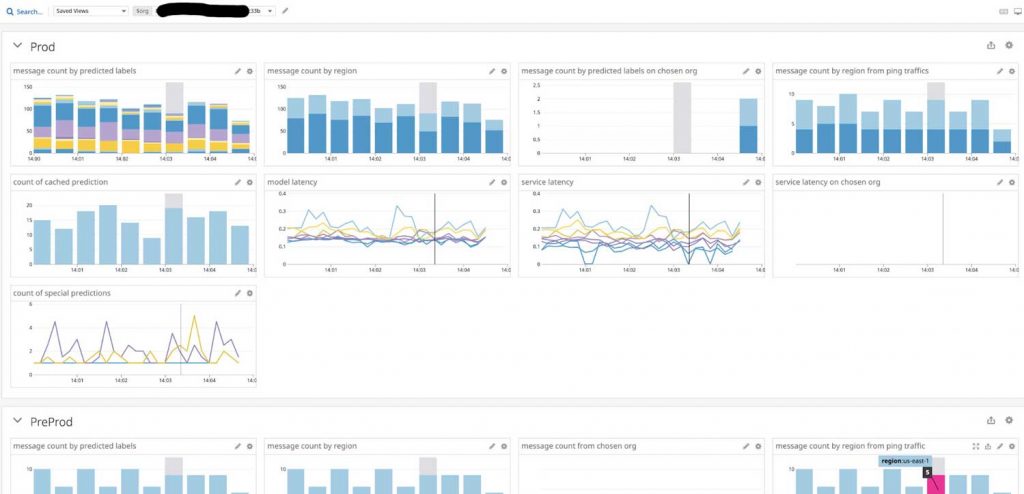
Figure 5: Datadog Dashboard Monitoring of the Model Endpoint Service
What’s next
This blog has focused on the end-to-end release of ML lifecycle as part of our product release using Databricks, MLflow, CircleCI, Concourse and other tools, including Datadog and Kubernetes. However, the iterative training and offline experimental flow can also benefit from additional automation. For example, standardizing how new training data is added and initiating training runs based on dynamic triggers like newly annotated data or user-provided feedback could improve overall system efficiency and shorten time-to-market for the top-performing model. More complete quality monitoring built-in to each stage with pre-set thresholds for gating releases could further improve efficiency.
Our deploy gate is still manual because, while we have target thresholds on critical metrics for releasing models, we haven’t codified every constraint and edge case that might give us pause before releasing a new model. Sometimes small offline error analyses are performed to provide the human understanding and confidence needed before releasing.
Another aspect that we have not covered in much detail is the annotation and feedback flow. While annotation provides the labeled data required to train and evaluate the model before releasing, the front-end of the released model can capture feedback directly from the users of the applications. We’ve integrated this feedback mechanism into the user experience such that user-corrected predictions produce data assets that can be incorporated into the training process. These labels are particularly impactful to model improvements as they push the model to change its behavior rather than duplicate simple patterns it already has learned and predicts correctly.
Finally, given our current flexibility to deploy to either Amazon SageMaker or local Kubernetes clusters for hosting services, we are also open to extending to other types of model hosting services such as TorchServ in the future.
For a more detailed look, check out the Summit session on the topic given by the blog's authors.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.