Announcing the Labelbox Connector for Databricks
Productionize unstructured data for AI and analytics at scale
by Nick Lee
This is a guest authored post by Nick Lee, partnership integration lead, at Labelbox
Large data lakes typically house a combination of structured and unstructured data. Data teams often use Apache Spark™ to analyze structured data, but may struggle to apply the same analysis to unstructured, unlabeled data (specifically in the form of images, video, etc). To tackle these challenges, Fortune 500 enterprises such as WarnerMedia and Stryker are leveraging Labelbox’s training data platform to quickly produce structured data from unstructured data. Labelbox has been used to support a variety of production AI use cases, including improved marketing personalization through visual search, manufacturing defect detection and smart camera development.
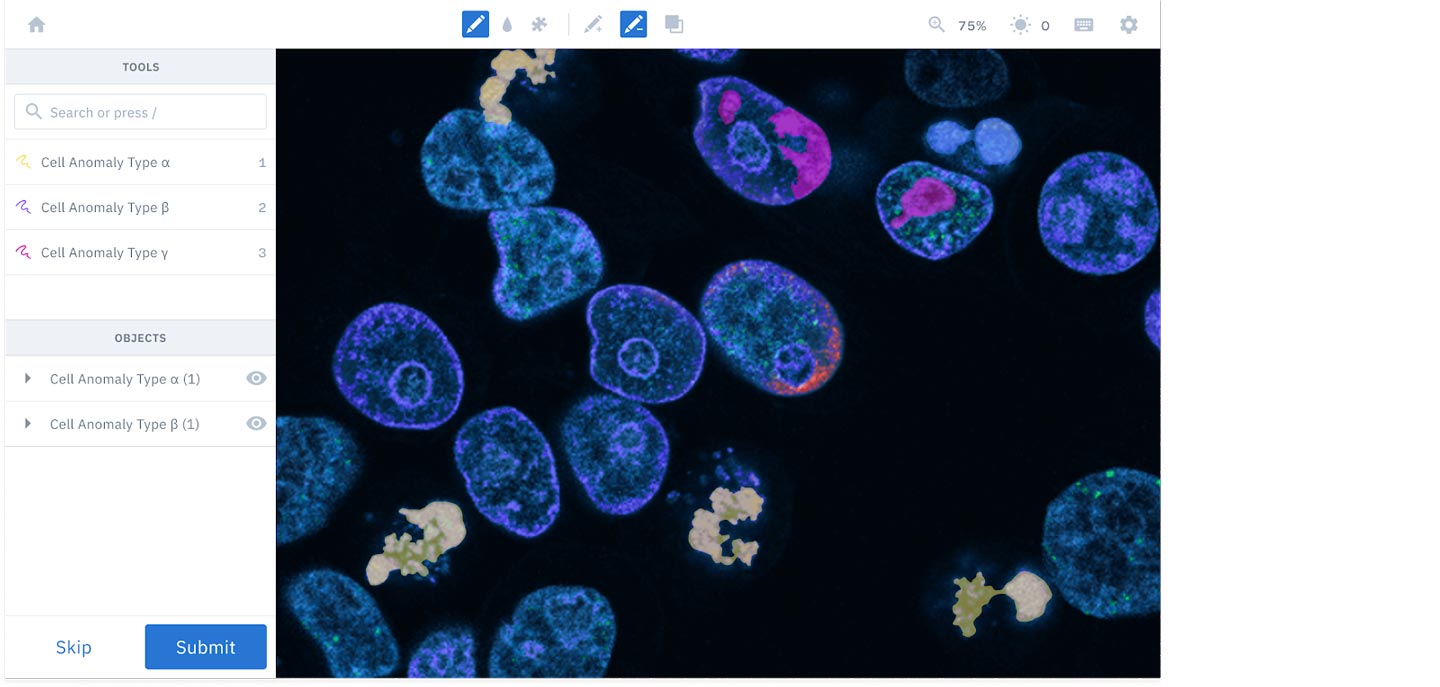
In the past, AI/ML teams had to use expensive, manual processes to transform their unstructured data into something more useful — either by paying a third-party to label their data, buying a labeled dataset or narrowing the scope of their project to leverage public datasets. Finding faster and more cost effective ways to convert unstructured data into structured data is highly beneficial towards supporting more advanced use cases built around companies’ unique, unstructured datasets.
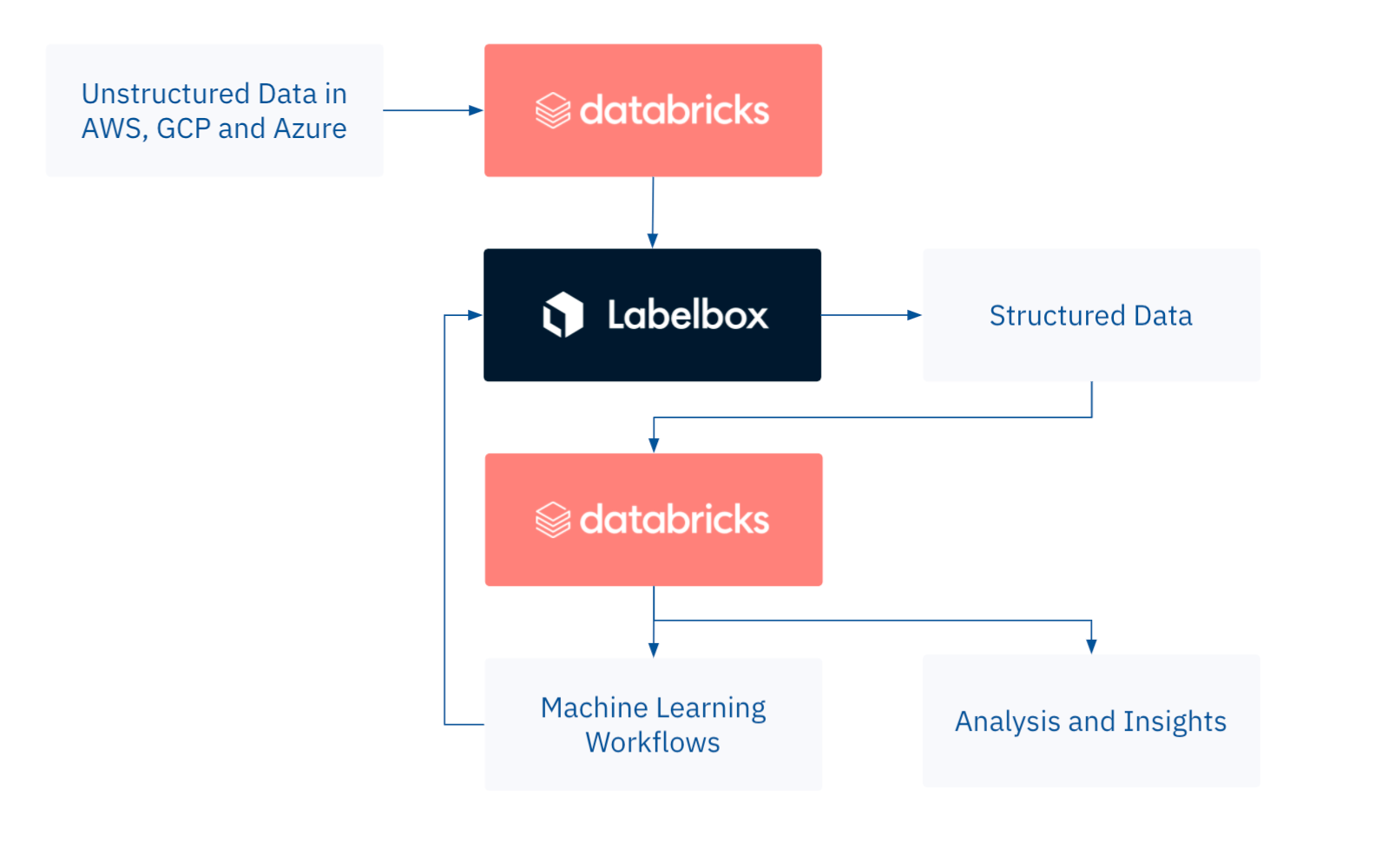
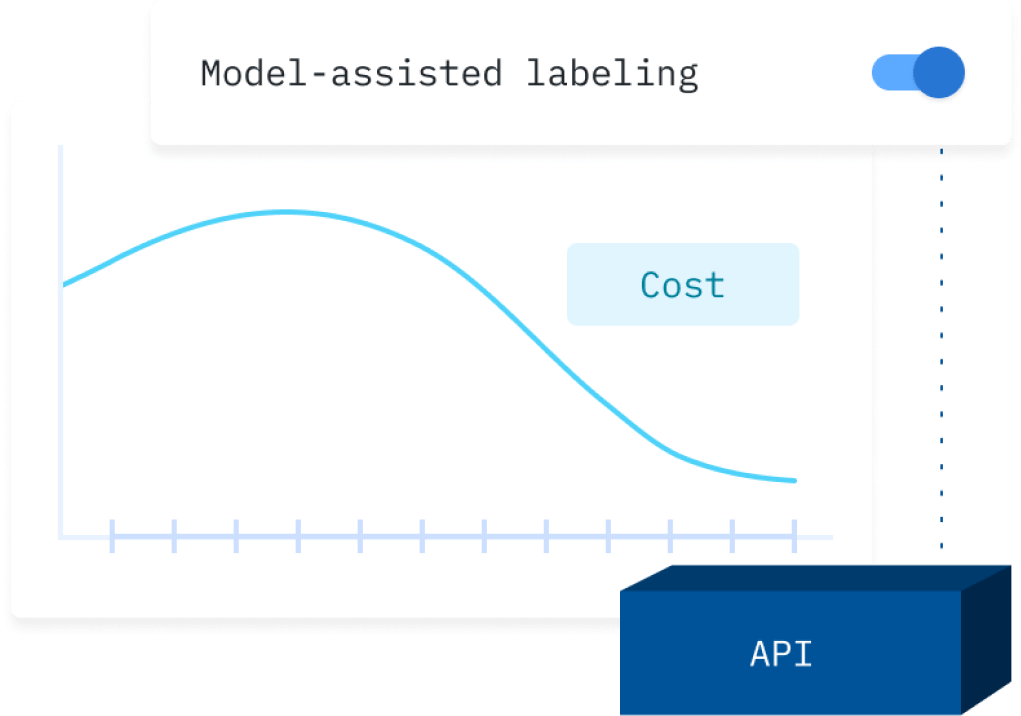
With Databricks, data science and AI teams can now easily prepare unstructured data for AI and analytics. Teams can label data with human effort, machine learning models in Databricks, or a combination of both. Teams can also employ a model-assisted labeling workflow that allows humans to easily inspect and correct a model’s predicted labels. In terms of time and cost savings, this process can drastically reduce the amount of unstructured data you need to achieve strong model performance.
Labelbox has recently launched a connector between Databricks and Labelbox so teams can connect an unstructured dataset to Labelbox. With the Labelbox Connector on Databricks, teams can programmatically set up an ontology for labeling and return the labeled dataset in a Spark DataFrame. Combining Databricks and Labelbox gives data and AI teams an end-to-end environment for unstructured data workflows, along with a query engine built around Delta Lake, coupling fast annotation tools with a powerful machine learning compute environment.
Learn more about using Databricks with Labelbox and see a live technical demo of the workflow at the Productionizing Unstructured Data for AI and Analytics session at Data + AI Summit 2021.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.