Databricks Announces the First Feature Store Co-designed with a Data and MLOps Platform
by Clemens Mewald and Mani Parkhe
Today, we announced the launch of the Databricks Feature Store, the first of its kind that has been co-designed with Delta Lake and MLflow to accelerate ML deployments. It inherits all of the benefits from Delta Lake, most importantly: data stored in an open format, built-in versioning and automated lineage tracking to facilitate feature discovery. By packaging up feature information with the MLflow model format, it provides lineage information from features to models, which facilitates end-to-end governance and model retraining when data changes. At model deployment, the models look up features from the Feature Store directly, significantly simplifying the process of deploying new models and features.
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
The data problem in AI
Raw data (transaction logs, click history, images, text, etc.) cannot be used directly for machine learning (ML). Data engineers, data scientists and ML engineers spend an inordinately large amount of time transforming data from its raw form into the final "features" that can be consumed by ML models. This process is also called "feature engineering" and can involve anything from aggregating data (e.g. number of purchases for a user in a given time window) to complex features that are the result of ML algorithms (e.g. word embeddings).
This interdependency of data transformations and ML algorithms poses major challenges for the development and deployment of ML models.
- Online/offline skew: For some of the most meaningful ML use cases, models need to be deployed online at low latency (think of a recommendation model that needs to run in tens of milliseconds when a webpage loads). The transformations that were used to compute features at training time (offline) now need to be repeated in model deployment (online) at low latency. This often leads teams to reimplement features multiple times, introducing subtle differences (called online/offline skew) that have significant impact on the model quality.
- Reusability and discoverability: In most cases, features get reimplemented several times because they are not discoverable, and if they are, they are not managed in a way that facilitates reuse. Naive approaches to this problem provide search based on feature names, which requires data scientists to correctly guess which names someone else used for their features. Furthermore, there is no way that data scientists can know which features are used where, making decisions such as updating or deleting a feature table difficult.
The Databricks Feature Store takes a unique approach to solving the data problem in AI
The Databricks Feature Store is the first of its kind that is co-designed with a data and MLOps platform. Tight integration with the popular open source frameworks Delta Lake and MLflow guarantees that data stored in the Feature Store is open, and that models trained with any ML framework can benefit from the integration of the Feature Store with the MLflow model format. As a result, the Feature Store provides several unique differentiators that help data teams accelerate their ML efforts:
- Eliminating online/offline skew with native model packaging: MLflow integration enables the Feature Store to package up feature lookup logic hermetically with the model artifact. When an MLflow model that was trained on data from the Feature Store is deployed, the model itself will look up features from the appropriate online store. This means that the client that calls the model can be oblivious to the fact that the Feature Store exists in the first place. As a result, the client becomes less complex and feature updates can be made without any changes to the client that calls the model.
- Enabling reusability and discoverability with automated lineage tracking: Computing features in a data-native environment enables the Databricks Feature Store to automatically track the data sources used for feature computation, as well as the exact version of the code that was used. This facilitates lineage-based search: a data scientist can take their raw data and find all of the features that are already being computed based on that same data. In addition, integration with the MLflow model format provides downstream lineage from features to models: the Feature Store knows exactly which models and endpoints consume any given feature, facilitating end-to-end lineage, as well as safe decision-making on whether a feature table can be updated or deleted.
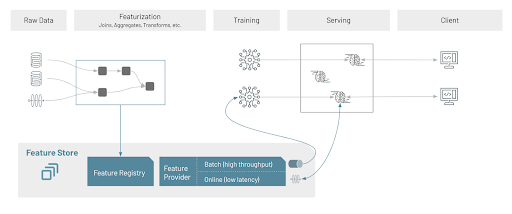
The Feature Store UI as a central repository for discovery, collaboration and governance
The Feature Store is a central repository of all the features in an organization. It provides a searchable record of all features, their definition and computation logic, data sources, as well as producers and consumers of features. Using the UI, a data scientist can:
- Search for feature tables by feature table name, feature, or data source
- Navigate from feature tables to their features and connected online stores
- Identify the data sources used to create a feature table
- Identify all of the consumers of a particular features, including Models, Endpoints, Notebooks and Jobs
- Control access to feature table's metadata
Feature Store search using feature name 'customer_id', feature tables with 'feature_pipeline', and 'raw_data' sources in their name.
The Databricks Feature Store is fully-integrated with other Databricks components. This native integration provides full lineage of the data that was consumed to compute features, all of the consumers that request features, and models in the Databricks Model Registry that were trained using features from the Feature Store.
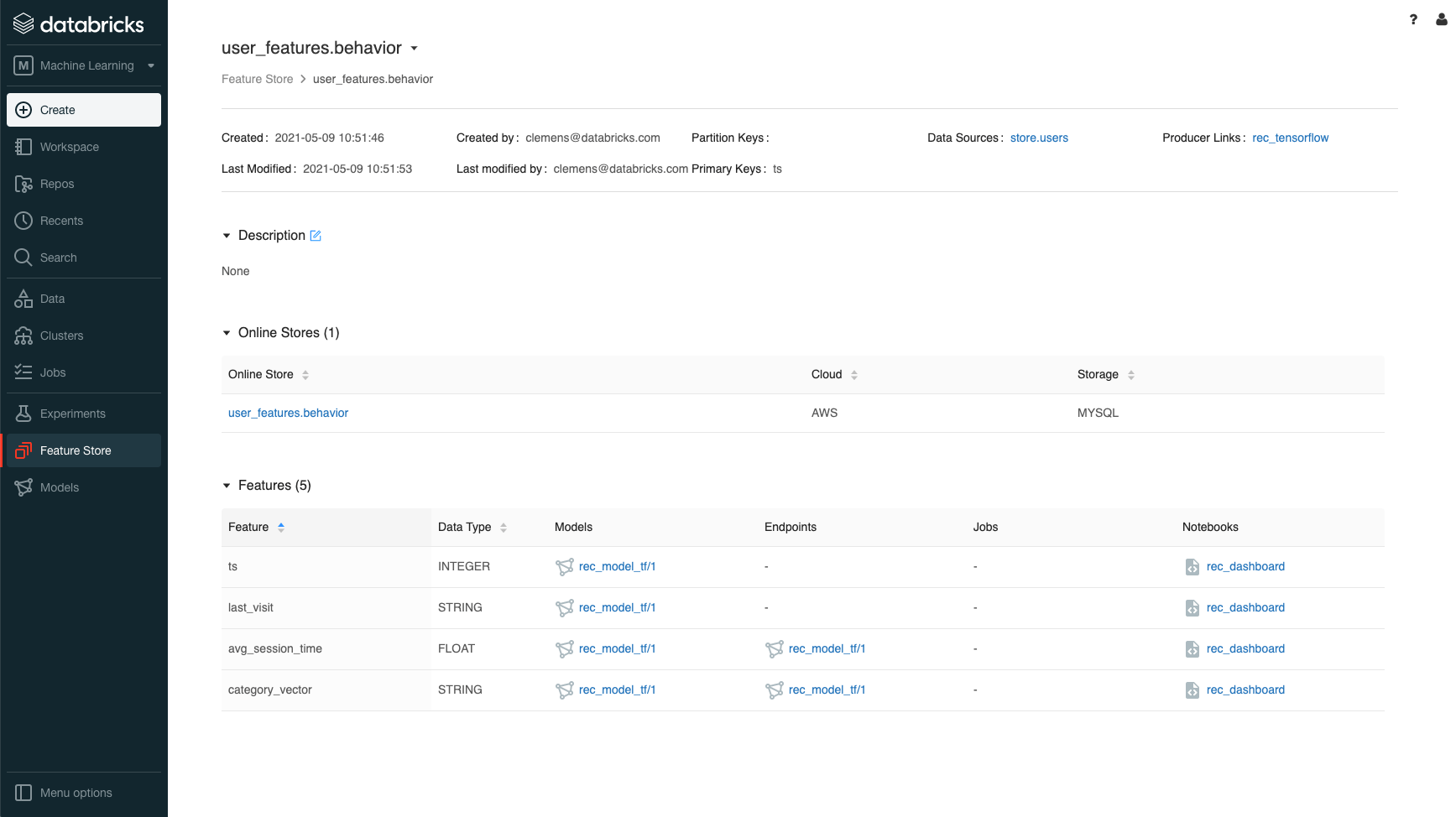
Feature table 'user_features.behavior', shows lineage to data sources and producers notebook; models; as well as consumer models, endpoints, and notebooks
Consistent access to features offline at high throughput and online at low latency
The Feature Store supports a variety of offline and online feature providers for applications to access features. Features are served in two modes. The batch layer provides features at high throughput for training of ML models and batch inference. Online providers serve features at low latency for the consumption of the same features in online model serving. An online provider is defined as a pluggable common abstraction that enables support for a variety of online stores and support APIs to publish features from offline to online stores and to look-up features.
Features are computed using batch computation or as streaming pipelines on Databricks and stored as Delta tables. These features can then be published using a scheduled Databricks Job or as a streaming pipeline. This ensures consistency of features used in batch training and features used in batch or online model inference, guaranteeing that there is no drift between features that were consumed at training and at serving time.
Model packaging
Integration with the MLflow Model format ensures that feature information is packaged with the MLflow model. During model training, the Feature Store APIs will automatically package the model artifact with all the feature information and code required at runtime for looking up feature information from the Feature Registry and fetching features from suitable providers.
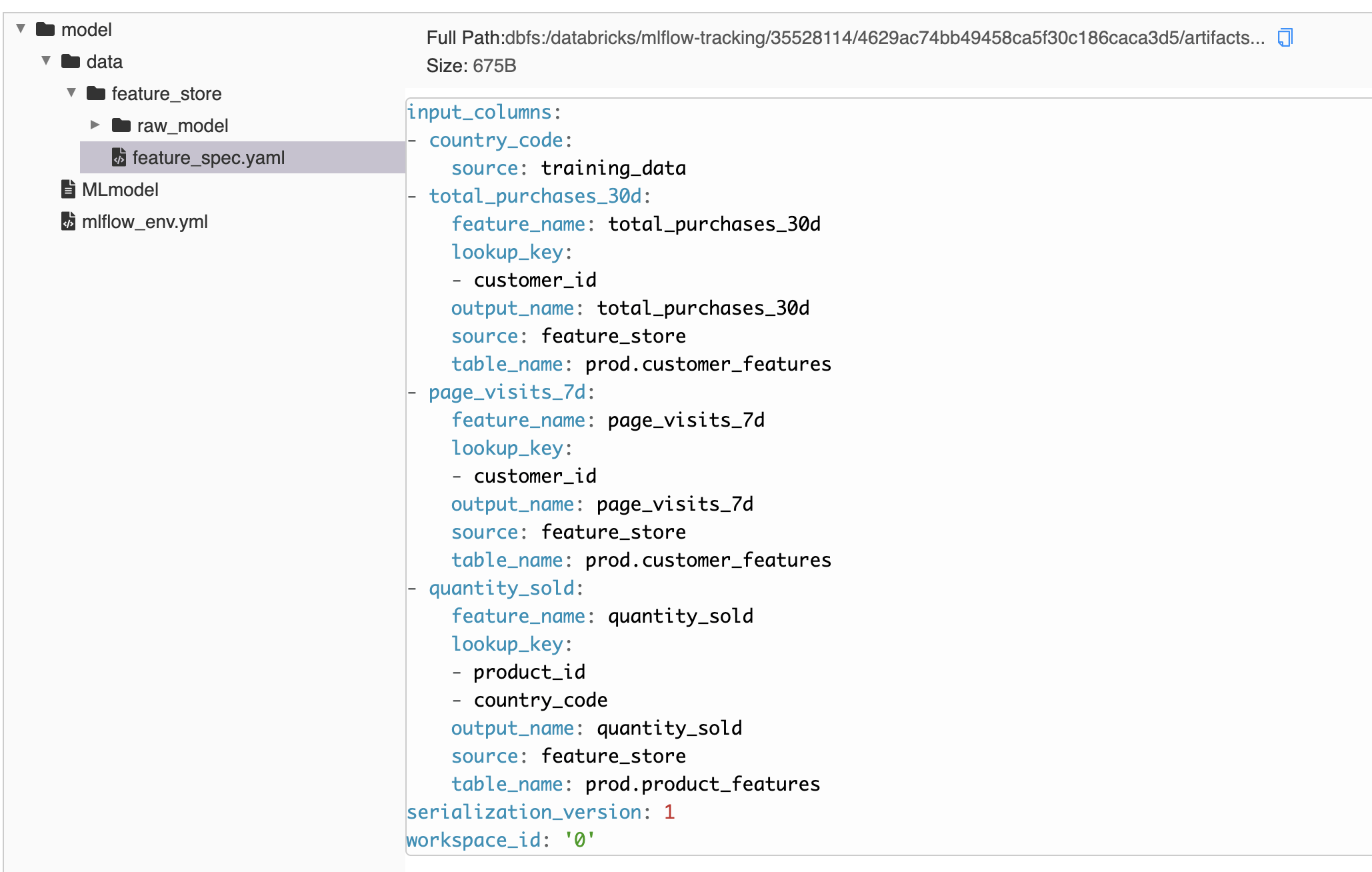
feature_spec.yaml containing feature store information is packaged with the MLflow model artifact.
This feature spec, packaged with the model artifact, provides the necessary information for the Feature Store scoring APIs to automatically fetch and join the features by the stored keys for scoring input data. At model deployment, this means the client that calls the model does not need to interact with the Feature Store. As a result, features can be updated without making changes to the client.
Feature Store API workflows
The FeatureStoreClient Python library provides APIs to interact with the Feature Store components to define feature computation and storage, use existing features in model training and automatic lookup for batch scoring, and publish features to online stores. The library comes automatically packaged with Databricks Runtime for Machine Learning (v 8.3 or later).
Creating new features
The low level APIs provide a convenient mechanism to write custom feature computation code. Data scientists write a Python function to compute features using source tables or files.
To create and register new features in the Feature Registry, call the create_feature_table API. You can specify a specific database and table name as destinations for your features. Each feature table needs to have a primary key to uniquely identify the entity's feature values
Training a model using features from the Feature Store
In order to use features from the Feature Store, create a training set that identifies the features required from each feature table and describes the keys from your training data set that would be used to lookup or join with feature tables.
The example below uses two features ('total_purchases_30d' and 'page_visits_7d') from the customer_features table, and uses the customer_id from the training dataframe to join with the feature tables' primary key. Additionally, it uses 'quantity_sold' from the product_features table and the 'product_id' and 'country_code' as composite primary keys to lookup features from that table. Then it uses the create_training_set API to build the training set, excluding keys not required for model training.
You can use any ML framework to train the model. The log_model API will package feature lookup information along with the MLmodel. This information is used for feature lookup during model inference.
Feature lookup and batch scoring
When scoring a model packaged with feature information, these features are looked up automatically during scoring. The user only needs to provide the primary key lookup columns as input. The Feature Store's score_batch API, under the hood, will use the feature spec stored in the model artifact to consult the Feature Registry for the specific tables, feature columns and the join keys. Then the API will perform the efficient joins with the appropriate feature tables to produce a dataframe of the desired schema for scoring the model. The following simple use code depicts this operation with the model trained above.
Publishing features to online stores
To publish a feature table to an online store, first specify a type of an online store spec and use the publish_table API. The following version will overwrite the existing table with recent features from the customer_features table from the batch provider.
publish_features supports various options to filter out specific feature values (by date or any filter condition). In the following example, today's feature values are streamed into the online stores and merged with existing features.
Get started with the Feature Store
Ready to get started or try it out for yourself? You can read more about Databricks Feature Store and how to use it in our documentation at AWS, Azure and GCP.

Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.