Monitoring ML Models With Model Assertions
by Daniel Kang, Deepti Raghavan, Peter Bailis and Matei Zaharia
This is a guest post from the Stanford University Computer Science Department. We thank Daniel Kang, Deepti Raghavan and Peter Bailis of Stanford University for their contributions.
Machine learning (ML) models are increasingly used in a wide range of business applications. Organizations deploy hundreds of ML models to predict customer churn, optimal pricing, fraud and more. Many of these models are deployed in situations where humans can’t verify all of the predictions - the data volumes are simply too large! As a result, monitoring these ML models is becoming crucial to successfully and accurately applying ML use cases.
In this blog post, we’ll show why monitoring models is critical and the catastrophic errors that can occur if we do not. Our solution leverages a simple, yet effective, tool for monitoring ML models we developed at Stanford University (published in MLSys 2020) called model assertions. We’ll also describe how to use our open-source Python library model_assertions to detect errors in real ML models.
Why we need monitoring
Let’s consider a simple example of estimating housing prices in Boston (dataset included in scikit-learn). This example is representative of standard use cases in the industry on a publicly available dataset. A data scientist might try to fit a linear regression model using features such as the average number of rooms to predict the price – such models are standard in practice. Using aggregate statistics to measure performance, like RMSE, shows that the model is performing reasonably well:
Unfortunately, while this model performs well on average, it makes some critical mistakes:
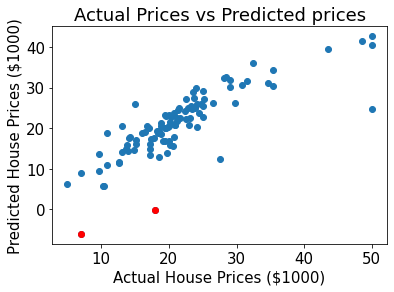
As highlighted above, the model predicts negative housing prices for some of the data. Using this model for setting housing prices would result in giving customers cash to purchase a house! If we only look at the aggregate metrics for our models, we would miss errors like these.
While seemingly simple, these kinds of errors are ubiquitous when using ML models. In our full paper, we also describe how to apply model assertions to autonomous vehicle and vision data (with an example about predicting attributes of TV news anchors here).
Model assertions
In the examples above, we see that ML models widely used in practice can produce inconsistent or nonsensical results. As a first step toward addressing these issues, we’ve developed an API called model assertions.
Model assertions let data scientists, developers and domain experts specify when errors in ML models may be occurring. A model assertion takes the inputs and outputs of a model and returns records containing potential errors.
Tabular data
Let’s look at an example with the housing price prediction model above. As a simple sanity check, a data scientist specifies that housing price predictions must be positive. After specifying and registering the assertion, it will flag potentially erroneous data points:
Autonomous vehicle and vision data
In many cases, models are used to predict over unstructured data to produce structured outputs. For example, autonomous vehicles predict pedestrian and car positions, and researchers studying TV news may be interested in predicting attributes of TV news anchors. Many assertions over this data deal with the predicted attributes or the temporal nature of the data. As a result, we’ve designed a consistency API that allows users to specify that 1) attributes should be consistent with the same identifier (e.g., the person in a scene, bounding box) and 2) that identifiers should not change too rapidly. In the second case, we’re taking advantage of the strong temporal consistency present in many applications (e.g., that a person shouldn’t appear, disappear and reappear within 0.5 seconds). As an example, we’re showing a vision and LIDAR model predicting trucks in the screenshot below. As you can see, the predictions are inconsistent; the prediction in green is from the vision model, and the prediction in purple is the LIDAR model. 

The IdentifierConsistencyAssertion specifies that the attributes (hair_color) of a particular entity (scene_identifier) consistent, e.g., that a specific newscaster should have the same hair color in the same scene. The TimeConsistencyAssertion specifies that an entity (scene_identifier) should not appear and disappear too many times in a time window.
Using model assertions
We’ve implemented model assertions as a Python library. To use it in your own code, simply install the package
Our library currently supports:
- Per-row assertions (e.g., that the output should be positive).
- Identifier consistency assertions that specify attributes of the same identifier should agree.
- Time consistency assertions that specify entities should not appear and disappear too many times in a time window.
And we plan on adding more!
In our full paper, we show other examples of how to use model assertions, including in autonomous vehicles, video analytics and ECG applications. In addition, we describe how to use model assertions for selecting training data. Using model assertions to select training data can be up to 40% cheaper than standard methods of selecting training data. Instead of selecting data at random or via uncertainty, selecting “hard” data points (i.e. data points with errors or ones that trigger model assertions) can be more informative.
Try the notebooks:
Visit the GitHub repository for more details and examples. Please reach out to ddkang@stanford.edu if you have any questions, feedback or would like to contribute!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.