New Performance Improvements in Databricks SQL
by Reynold Xin, Can Efeoglu and Cyrielle Simeone
Databricks SQL is now generally available on AWS and Azure.
Originally announced at Data + AI Summit 2020 Europe, Databricks SQL lets you operate a multi-cloud lakehouse architecture that provides data warehousing performance at data lake economics. Our vision is to give data analysts a simple yet delightful tool for obtaining and sharing insights from their lakehouse using a purpose-built SQL UI and world-class support for popular BI tools.
This blog is the first of a series on Databricks SQL that aims at covering the innovations we constantly bring to achieve this vision: performance, ease of use and governance. This blog will cover recent performance optimizations as part of Databricks SQL for:
- Highly concurrent analytics workloads
- Intelligent workload management
- Highly parallel reads
- Improving business intelligence (BI) results retrieval with Cloud Fetch
Explore why lakehouses are the data architecture of the future with the father of the data warehouse, Bill Inmon.
Real-life performance beyond large queries
The initial release of Databricks SQL started off with significant performance benefits -- up to 6x price/performance -- compared to traditional cloud data warehouses as per the TPC-DS 30 TB scale benchmark below. Considering that the TPC-DS is an industry standard benchmark defined by data warehousing vendors, we are really proud of these results.
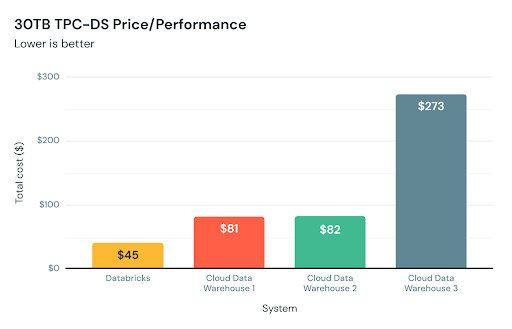
While this benchmark simulates large queries such as ETL workloads or deep analytical workloads well, it does not cover everything our customers run. That's why we've worked closely with hundreds of customers in recent months to provide fast and predictable performance for real-life data analysis workloads and SQL data queries.
As we officially ungate the preview today, we are very excited to share some of the results and performance gains we've achieved to date.
Scenario 1: Highly concurrent analytics workloads
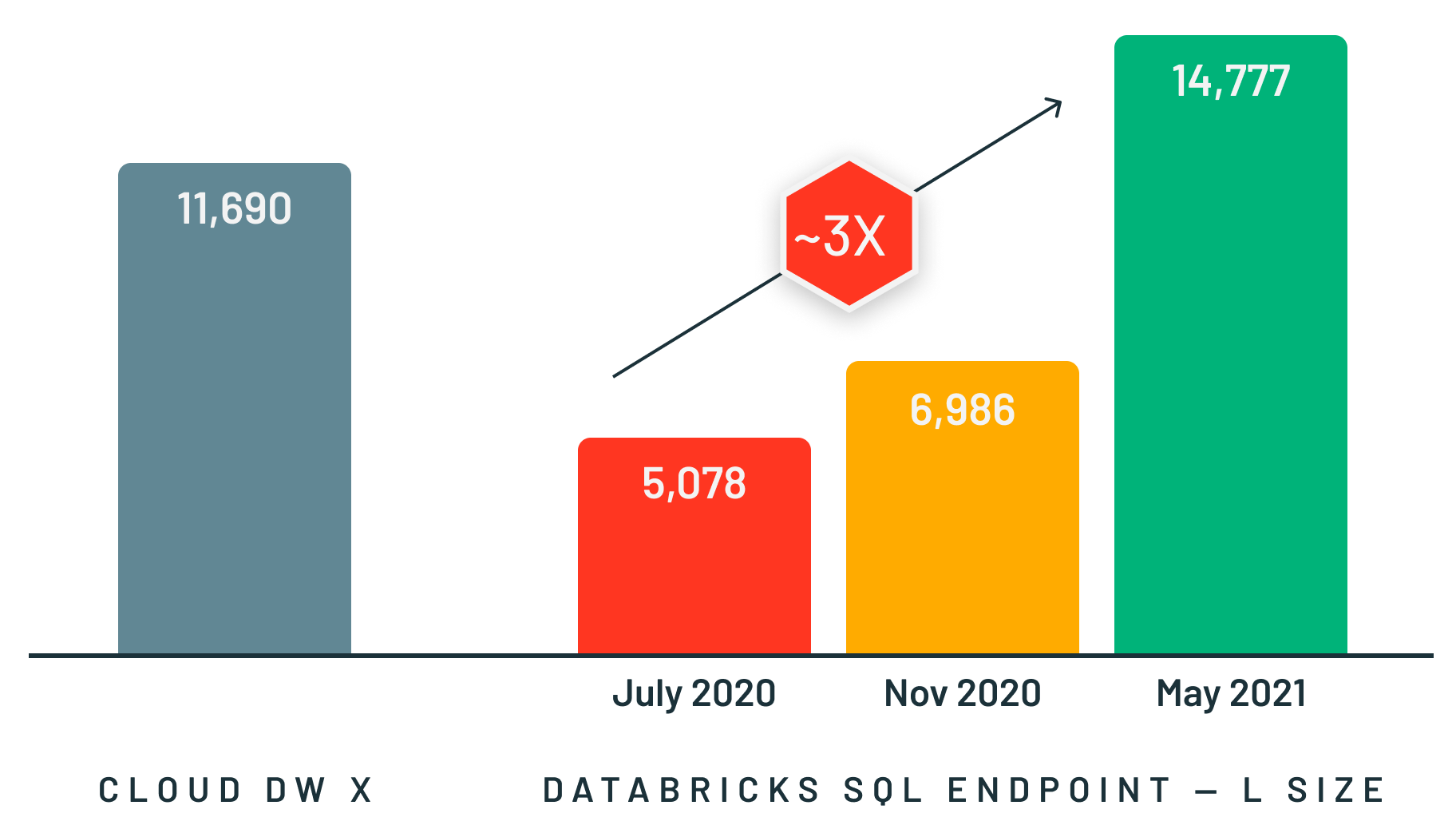
In working with customers, we noticed that it is common for highly concurrent analytics workloads to execute over small datasets. Intuitively, this makes sense - analysts usually apply filters and tend to work with recent data more than historical data. We decided to make this common use-case faster. To optimize concurrency, we used the same TPC-DS benchmark with a much smaller scale factor (10GB) and 32 concurrent streams. So, we have 32 bots submitting queries continuously to the system, which actually simulates a much larger number of real users because bots don’t rest between running queries.
We analyzed the results to identify and remove bottlenecks, and repeated this process multiple times. Hundreds of optimizations later, we improved concurrency by 3X! Databricks SQL now outperforms some of the best cloud data warehouses for both large queries and small queries with lots of users.
Scenario 2: Intelligent workload management
Real-world workloads, however, are not just about either large or small queries. They typically include a mix of small and large queries. Therefore the queuing and load balancing capabilities of Databricks SQL need to account for that too. That's why Databricks SQL uses a dual queuing system that prioritizes small queries over large, as analysts typically care more about the latency of short queries versus large.
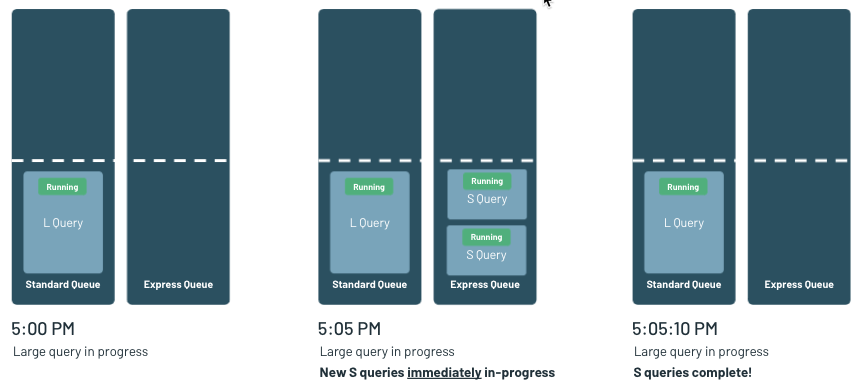
Scenario 3: Highly parallel reads
It is common for some tables in a lakehouse to be composed of many files e.g. in streaming scenarios such as IoT ingest when data arrives continuously. In legacy systems, the execution engine can spend far more time listing these files than actually executing the query! Our customers also told us they do not want to sacrifice performance for data freshness.
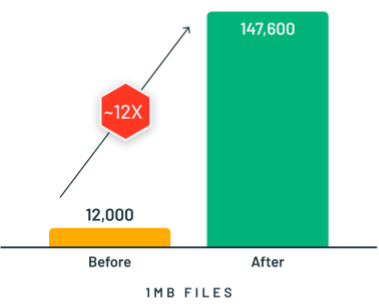
We are proud to announce the inclusion of async and highly parallel IO in Databricks SQL. When you execute a query, Databricks automatically reads the next blocks of data from cloud storage while the current block is being processed. This considerably increases overall query performance on small files (by 12x for 1MB files) and "cold data" (data that is not cached) use cases as well.
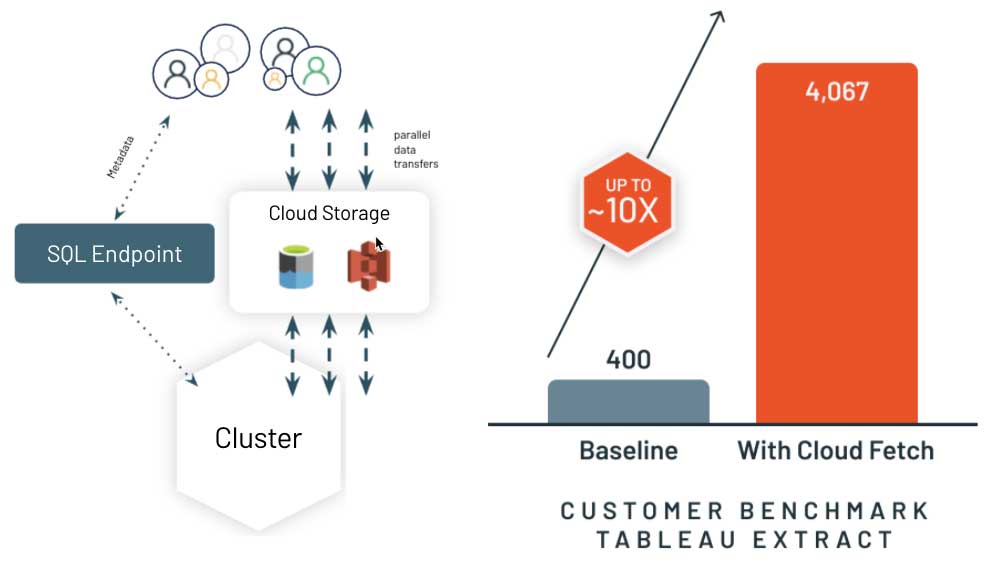
Scenario 4: Improving BI results retrieval with Cloud Fetch
Once query results are computed, the last mile is to speed up how the system delivers results to the client - typically a BI tool like PowerBI or Tableau. Legacy cloud data warehouses often collect the results on a leader (aka driver) node, and stream it back to the client. This greatly slows down the experience in your BI tool if you are fetching anything more than a few megabytes of results.
That's why we've reimagined this approach with a new architecture called Cloud Fetch. For large results, Databricks SQL writes results in parallel across all of the compute nodes to cloud storage, and then sends the list of files using pre-signed URLs back to the client. The client then can download in parallel all the data from cloud storage. We are delighted to report up to 10x performance improvement in real-world customer scenarios! We are working with the most popular BI tools to enable this capability automatically.
Unpacking Databricks SQL
These are just a few examples of performance optimizations and innovations brought to Databricks SQL to provide you with best-in-class SQL performance on your data lake, while retaining the benefits of an open approach. So how does this work?
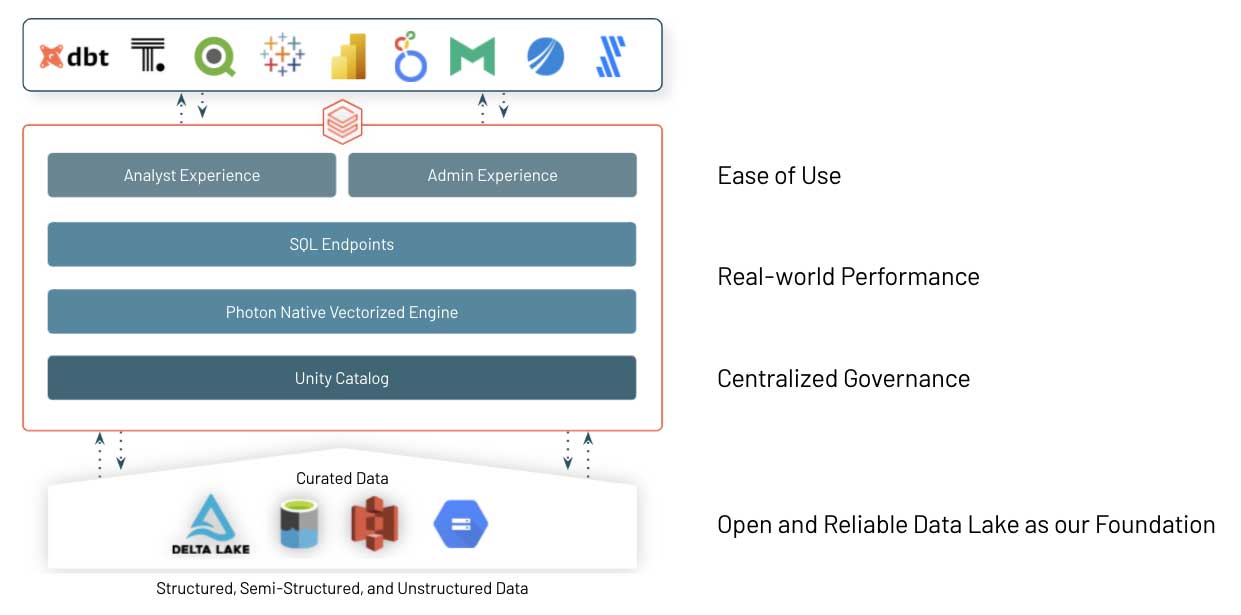
Open source Delta Lake is the foundation for Databricks SQL. It is the open data storage format that brings the best of data warehouse systems to data lakes, with ACID transactions, data lineage, versioning, data sharing and so on, to structured, unstructured and semi-structured data alike.
At the core of Databricks SQL is Photon, a new native vectorized engine on Databricks written to run SQL workloads faster. Read our blog and watch Radical Speed for SQL Queries on Databricks: Photon Under the Hood to learn more.
And last but not least, we have worked very closely with a large number of software vendors to make sure that data teams -- analysts, data scientists and SQL developers-- can easily use their tools of choice on Databricks SQL. We made it easy to connect, get data in and authenticate using single-sign-on while boosting speed thanks to the concurrency and short query performance improvements we covered before.
Next steps
This is just the start, as we plan to continuously listen and add more innovations to the service. Databricks SQL is already bringing a tremendous amount of value to many organizations like Atlassian or Comcast, and we can't wait to hear your feedback as well!
If you’re an existing Databricks user, you can start using Databricks SQL today using our Get Started guide for Azure Databricks or AWS. If you’re not yet a Databricks user, visit databricks.com/try-databricks to start a free trial.
Finally, if you’d like to learn more about Databricks Lakehouse platform, watch our webinar – Data Management, the good, the bad, the ugly. In addition, we are offering Databricks SQL online training for hands-on experience, and personalized workshops. Contact your sales representative to learn more. We’d love to hear how you use Databricks SQL and how we can make BI and data analytics on your data lake even simpler.
Watch DAIS Keynote and Demo Below
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.