Part 1: Implementing CI/CD on Databricks Using Databricks Notebooks and Azure DevOps
by Michael Shtelma and Piotr Majer
Discussed code can be found here.
This is the first part of a two-part series of blog posts that show how to configure and build end-to-end MLOps solutions on Databricks with notebooks and Repos API. This post presents a CI/CD framework on Databricks, which is based on Notebooks. The pipeline integrates with the Microsoft Azure DevOps ecosystem for the Continuous Integration (CI) part and Repos API for the Continuous Delivery (CD).In the second post, we'll show how to leverage the Repos API functionality to implement a full CI/CD lifecycle on Databricks and extend it to the fully-blown MLOps solution.
CI/CD with Databricks Repos
Fortunately, with the new functionality provided by Databricks Repos and Repos API, we are now well equipped to cover all key aspects of version control, testing and pipelines underpinning MLOps approaches. Databricks Repos allow cloning whole git repositories in Databricks and with the help of Repos API, we can automate this process by first cloning a git repository and then check out the branch we are interested in. ML practitioners can now use a repository structure well known from IDEs in structuring their project, relying on notebooks or .py files for implementation of modules (with support for arbitrary file format in Repos planned on the roadmap). Therefore, the entire project is version controlled by a tool of your choice (Github, Gitlab, Azure Repos to name a few) and integrates very well with common CI/CD pipelines. The Databricks Repos API allows us to update a repo (Git project checked out as repo in Databricks) to the latest version of a specific git branch.
The teams can follow the classical Git flow or GitHub flow cycle during development. The whole Git repository can be checked out with Databricks Repos. Users will be able to use and edit the notebooks as well as plain Python files or other text file types with arbitrary file support. This allows us to use classical project structure, importing modules from Python files and combining them with notebooks:
- Develop individual features in a feature branch and test using unit tests (e.g., implemented notebooks).
- Push changes to the feature branch, where the CI/CD pipeline will run the integration test.
- CI/CD pipelines on Azure DevOps can trigger Databricks Repos API to update this test project to the latest version.
- CI/CD pipelines trigger the integration test job via the Jobs API. Integration tests can be implemented as a simple notebook that will at first run the pipelines that we would like to test with test configurations. This can be done by just running an appropriate notebook with executing corresponding modules or by triggering the real job using jobs API.
- Examine the results to mark the whole test run as green or red.
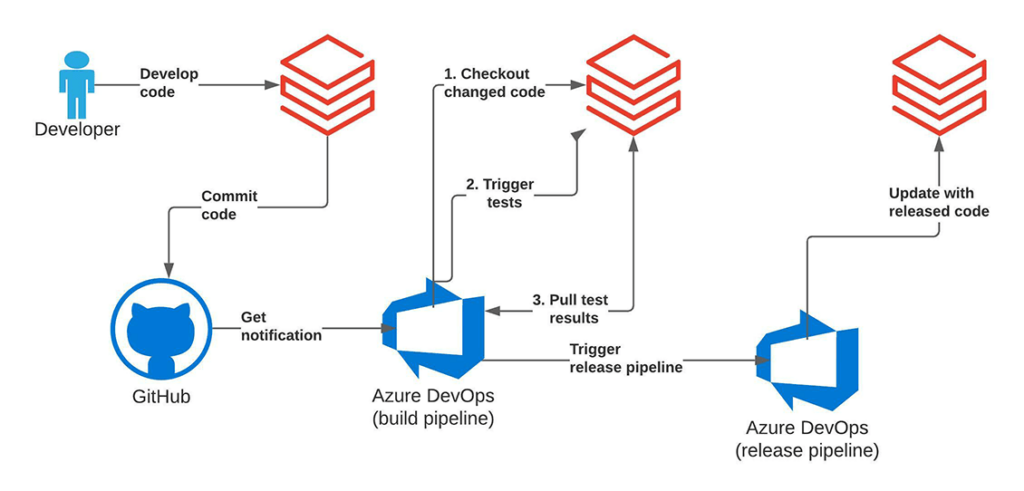
Let's now examine how we can implement the approach described above. As an exemplary workflow, we will focus on data coming from Kaggle Lending Club competition. Similar to many financial institutions, we would like to understand and predict individual income data, for example, to assess the credit score of an application. In order to do so, we analyze various applicant features and attributes, ranging from current occupation, homeownership, education to location data, marital status and age. This is the information a bank has collected, (e.g., in the past credit applications), and it is now used to train a regression model.
Moreover, we know that our business changes dynamically, and there is a high volume of new observations daily. With the regular ingestion of new data, retraining the model is crucial. Therefore, the focus is on full automation of the retraining jobs as well as the entire continuous deployment pipeline. To ensure high-quality outcomes and the high predictive power of a newly trained model, we add an evaluation step after each trained job. Here the ML model is scored on a curated data set and compared to the currently deployed production version. Therefore, the model promotion can happen only if the new iteration has high predictive power.
As a project is actively developed and worked on, the fully-automated testing of new code and promotion to the next stage of the life cycle utilizes the Azure DevOps framework for unit/integration evaluation at push/pull requests. The tests are orchestrated through the Azure DevOps framework and executed on the Databricks platform. This covers the CI part of the process, ensuring high test coverage of our codebase, minimizing human supervision.
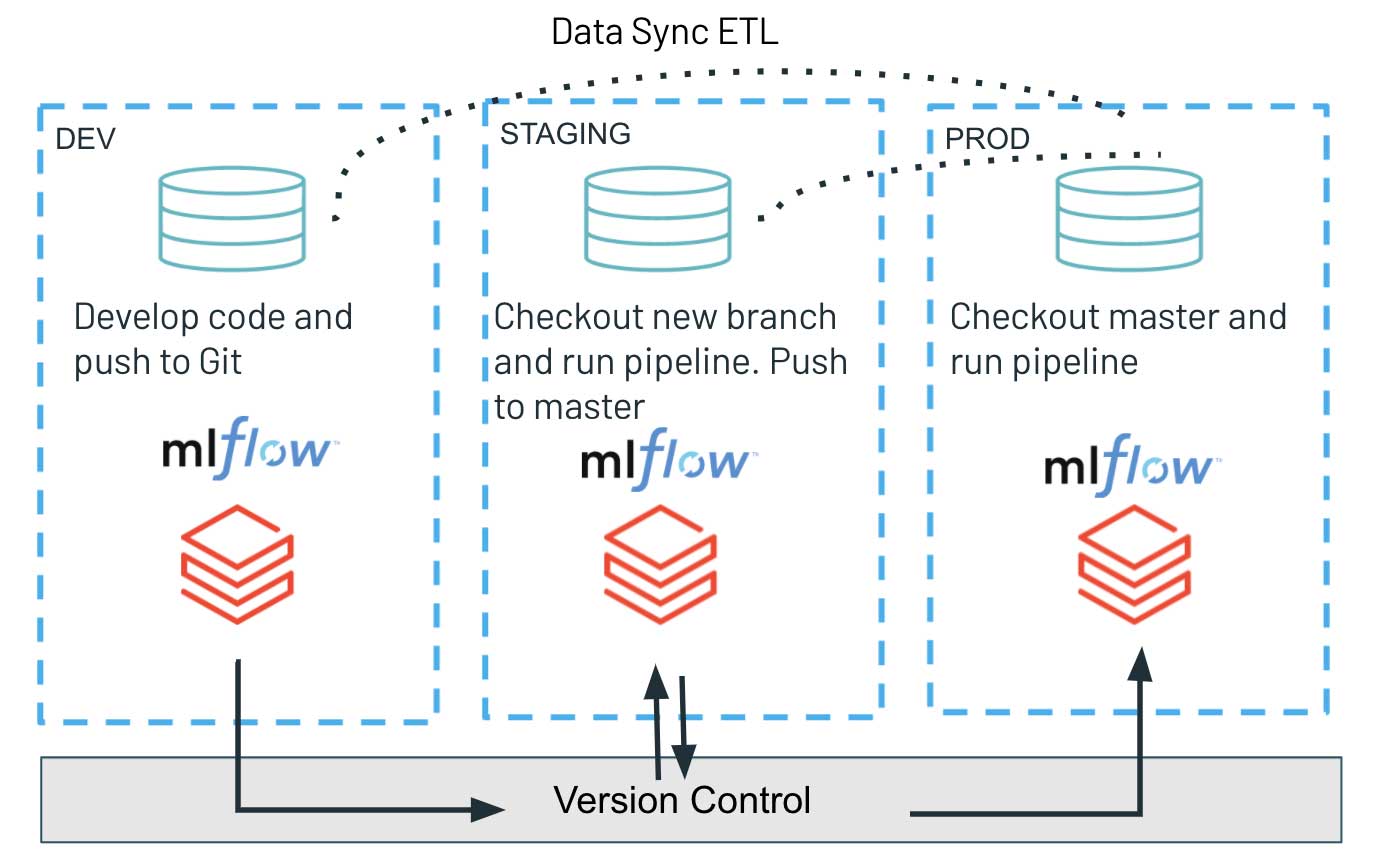
The continuous delivery part relies solely on the Repos API, where we use the programmatic interface to check out the newest version of our code in the Git branch and deploy the newest scripts to run the workload. This allows us to simplify the artifact deployment process and easily promote the tested code version from dev through staging to production environments. Such an architecture guarantees the full isolation of various environments and is typically favored in increased security environments. The different stages: dev, staging, and prod share only the version control system, minimizing potential interference with highly-critical production workloads. At the same time, the exploratory work and innovation are decoupled as the dev environment may have more relaxed access controls.
Implement CI/CD pipeline using Azure DevOps and Databricks
In the following code repository, we implemented the ML project with a CI/CD pipeline powered by Azure DevOps. In this project, we use notebooks for data preparation and model training.
Let's see how we can test these notebooks on Databricks. Azure DevOps is a very popular framework for complete CI/CD workflows available on Azure. For more information, please have a look at the overview of provided functionalitiesand continuous integrations with Databricks.
We are using the Azure DevOps pipeline as a YAML file. The pipeline treats Databricks notebooks like simple Python files, so we can run them inside our CI/CD pipeline. We have placed a YAML file for our Azure CI/CD pipeline inside azure-pipelines.yml. The most interesting part of this file is a call to Databricks Repos API to update the state of the CI/CD project on Databricks and a call to Databricks Jobs API to trigger integration test job execution. We have developed both these items in deploy.py script/notebook. We can call it in the following way inside the Azure DevOps pipeline:
DATABRICKS_HOST and DATABRICKS_TOKEN environment variables are needed by the databricks_cli package to authenticate us against the Databricks workspace we are using. These variables can be managed through Azure DevOps variable groups.
Let's examine the deploy.py script now. Inside the script, we are using databricks_cli API to work with the Databricks Jobs API. First, we have to create an API client:
After that, we can create a new temporary Repo on Databricks for our project and pull the latest revision from our newly created Repo:
Next, we can kick off the execution of the integration test job on Databricks:
Finally, we wait for the job to complete and examine the result:
Working with multiple workspaces
Using the Databricks Repos API for CD may be particularly useful for teams striving for complete isolation between their dev/staging and production environments. The new feature allows data teams, through source code on Databricks, to deploy the updated codebase and artifacts of a workload through a simple command interface across multiple environments. Being able to programmatically check out the latest codebase in the version control system ensures a timely and simple release process.
For the MLOps practices, there are numerous serious considerations on the right architectural setup between various environments. In this study, we focus only on the paradigm of full isolation, which would also cover multiple MLflow instances associated with dev/staging/prod. In that light, the models trained in a dev environment would not be pushed to the next stage as serialized objects are loaded through a single common Model Registry. The only artifact deployed is the new training pipeline codebase that is released and executed in the STAGING environment, resulting in a new model trained and registered with MLflow.
This shared-nothing principle, jointly with strict permission management on prod/staging env, but rather relaxed access patterns on dev, allows for robust and high-quality software development. Simultaneously, it offers a higher degree of freedom in the dev instance, speeding up innovation and experimentation across the data team.
Summary
In this blog post, we presented an end-to-end approach for CI/CD pipelines on Databricks using notebook-based projects. This workflow is based on the Repos API functionality that not only lets the data teams structure and version control their projects in a more practical way but also greatly simplifies the implementation and execution of the CI/CD tools. We showcased an architecture in which all operational environments are fully isolated, ensuring a high degree of security for production workloads powered by ML.
The CI/CD pipelines are powered by a framework of choice and integrate with the Databricks Unified Analytics Platform smoothly, triggering the execution of the code and infrastructure provisioning end-to-end. Repos API radically simplifies not only the version management, code structuring, and development part of a project lifecycle but also the continuous delivery, allowing to deploy the production artifacts and code between environments. It is an important improvement that adds to the overall efficiency and scalability of Databricks and greatly improves software developer experience.
Discussed code can be found here.
References:
- https://www.databricks.com/blog/2021/06/23/need-for-data-centric-ml-platforms.html
- Continuous Delivery for Machine Learning, Martin Fowler, https://martinfowler.com/articles/cd4ml.html,
- Overview of MLOps, https://www.kdnuggets.com/2021/03/overview-mlops.htm Introducing Azure DevOps, https://azure.microsoft.com/en-us/blog/introducing-azure-devops/
- Continuous integration and delivery on Azure Databricks using Azure DevOps, https://docs.microsoft.com/en-us/azure/databricks/dev-tools/ci-cd/ci-cd-azure-devops
- Lending club Kaggle data set https://www.kaggle.com/wordsforthewise/lending-club
- Repos for Git integration https://docs.databricks.com/repos.html
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.