Databricks Repos Is Now Generally Available - New ‘Files’ Feature in Public Preview
Development for data teams just Git a lot better :) All-new ‘Files’ feature makes development, code reuse, and environment management easier for data teams.
by Ka-Hing Cheung and Vaibhav Sethi
Thousands of Databricks customers have adopted Databricks Repos since its public preview and have standardized on it for their development and production workflows. Today, we are happy to announce that Databricks Repos is now generally available.
Databricks Repos was created to solve a persistent problem for data teams: most tools used by data engineering/machine learning practitioners offer poor or no integration with Git version control systems, forcing them to navigate through multiple files, steps and UIs to simply review and commit code. Not only is this time-consuming, but it's also error-prone.
Repos solves this problem by providing repository-level integration with all popular Git providers directly within Databricks, enabling data practitioners to easily create new or clone existing Git repositories, perform Git operations and follow development best practices.
With Databricks Repos, you get access to familiar Git functionality, including the ability to manage branches, pull remote changes and visually inspect outstanding changes before committing them so that you can easily follow Git-based development workflows. Furthermore, Repos supports a wide range of Git providers, including Github, Bitbucket, Gitlab and Microsoft Azure DevOps, as well as provides a set of APIs for integration with CI/CD systems.
New: Files in Repos
We are also excited to announce new functionality in Repos that allows you to work with non-notebook files, such as Python source files, library files, config files, environment specification files and small data files in Databricks. This feature, called Files in Repos, helps with easy code reuse and automation of environment management and deployments. Users can import (or clone), read, and edit these files within a Databricks Repo just like in any local filesystem. It is now available in a public preview.
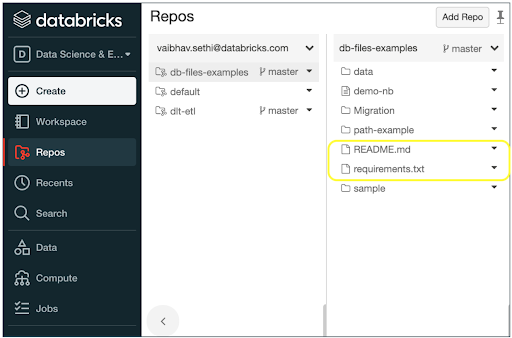
Files in Repos provides you a simplified and standards-compliant development experience. Let's take a look at how this helps with some of the common development workflows:
Benefits of Files in Repos include:
Easier code reuse
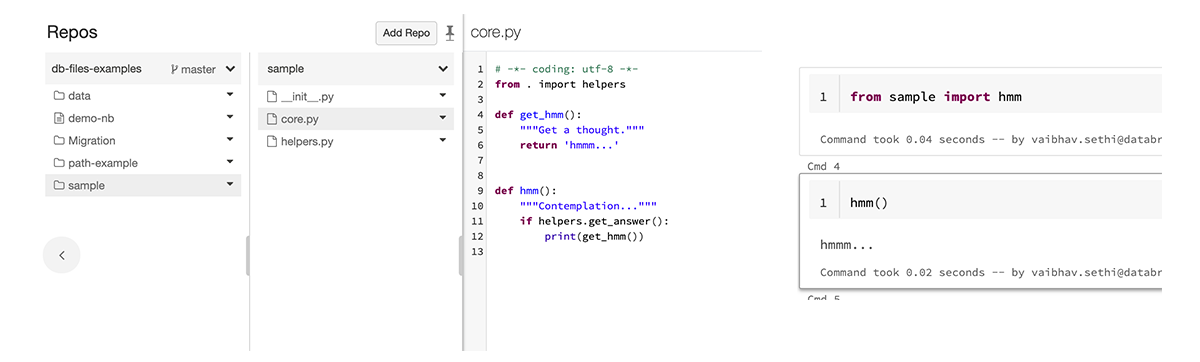
Python and R modules can be placed in Repos and notebooks in that Repo can reference their functions with the 'import' statement. You no longer have to create new notebooks for each Python function you reference, or package your module (as a whl for python) and install it as a cluster library. Files in Repos helps you replace all of these steps (and more) with a single line of code.
Automate environment management and production deployments
- Store your environment configuration with your code: You can store environment configuration files such as requirements.txt in a Repo and then run the command %pip install -r requirements.txt to install the required library dependencies. This reduces the burden of managing the environment manually and eliminates errors and divergence.
- Automate deployments: You can store the configuration of Databricks resources such as job, cluster, etc. in a Repo and then automate the deployment of these resources, allowing you to tightly control your production environment.
- Version any config file: In addition to the environment specifications and resource configs, your config files could contain algorithm parameters, data inputs for business logic, etc. With Repos, you can be sure to always use the correct version of the file, say from the 'main' branch or a particular tag to eliminate errors.
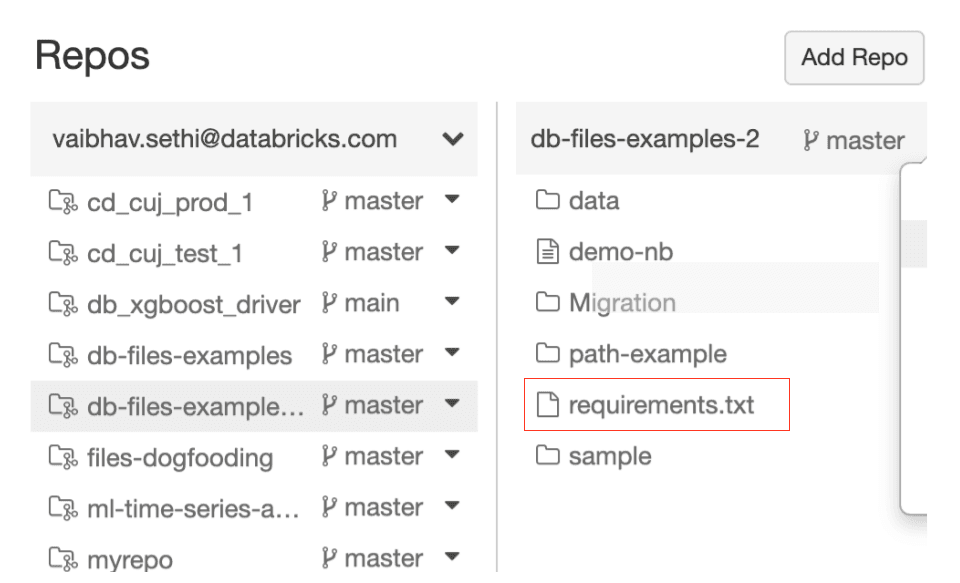
Fig 3: Repos gives you the ability to version any kind of file
In summary, with Databricks, data teams no longer need to build ad-hoc processes for version control and productionize their code. Databricks Repos enables data teams to automate Git operations, allowing tighter integration with established CI/CD pipelines of the company. The new Files feature in Repos enables importing libraries for code portability, versioning environment specification files and working with small data files.
Get started
Repos is now generally available. To get started, click on the 'Repos' button in your sidebar or use the Repos API.

Files in Repos feature is in Public Preview and can be enabled for Databricks Workspaces! To enable it, go to Admin Panel -> Advanced and click the "Enable" button next to "Files in Repos." Learn more in our developer documentation.
To discover how Databricks simplifies development for data teams by enabling automation at each step of the ML lifecycle check out this on-demand webinar with Databricks architect Rafi Kuralisnik.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.