GPU-accelerated Sentiment Analysis Using Pytorch and Huggingface on Databricks
Sentiment analysis is commonly used to analyze the sentiment present within a body of text, which could range from a review, an email or a tweet. Deep learning-based techniques are one of the most popular ways to perform such an analysis. However, these techniques tend to be very computationally intensive and often require the use of GPUs, depending on the architecture and the embeddings used. Huggingface (https://huggingface.co) has put together a framework with the transformers package that makes accessing these embeddings seamless and reproducible. In this work, I illustrate how to perform scalable sentiment analysis by using the Huggingface package within PyTorch and leveraging the ML runtimes and infrastructure on Databricks.
Sentiment analysis
Sentiment analysis is the process of estimating the polarity in a user’s sentiment, (i.e. whether a user feels positively or negatively from a document or piece of text). The sentiment can also have a third category of neutral to account for the possibility that one may not have expressed a strong positive or negative sentiment regarding a topic. Sentiment analysis is a form of opinion mining but differs from stance or aspect detection, where a user’s stance regarding a particular aspect or feature is extracted.
For example, the sentiment in the sentence below is overwhelmingly positive:
“The restaurant was great”
However, consider the sentence below:
“The restaurant was great but the location could be better”
It is harder to estimate the sentiment, but the user’s stance regarding the restaurant can be seen as generally positive in spite of the fact that their stance regarding the location was negative. To summarize, sentiment analysis provides coarse-grained information while stance detection provides more information regarding certain aspects.
Sentiment analysis can be used to ascertain a customer’s sentiment regarding a particular product, the public’s reaction to an event, etc.
Types of sentiment analysis
Sentiment analysis can be performed using lexicon-based techniques or machine learning-based techniques. Lexicon-based techniques use pre-labeled vocabulary to estimate the sentiment from text. A variety of techniques are used to aggregate the sentiment from the individual sentiment assigned to the tokenized words. Some of the popular frameworks in this category are SentiNet and AFINN . VADER, an open-source package with the NLTK, is another example that is used specifically for analyzing social media posts. Machine learning-based sentiment analysis uses pre-trained embeddings along with a deep learning (DL) architecture to infer the sentiment in a body of text. In this blog, we will only cover ML-based techniques through the embeddings available from Huggingface. The sentiment analysis model, composed of the architecture and the embeddings, can then be optionally fine-tuned if domain-specific labels are available for the data. It is often the case that such supervised training can improve the performance even when only a small amount of labeled data is available. Embeddings such as Elmo, BERT and Roberta are some of the popularly available language embeddings for this purpose.
Introduction to transformers
Huggingface has made available a framework that aims to standardize the process of using and sharing models. This makes it easy to experiment with a variety of different models via an easy-to-use API. The transformers package is available for both Pytorch and Tensorflow, however we use the Python library Pytorch in this post. The easiest way to perform inference using the transformers package is shown below.
Looking at the example above, we notice two imports for a tokenizer and a model class. We can instantiate these by specifying a certain pre-trained model such as BERT. You can search for a model here. You then pass a sequence of strings to the tokenizer to tokenize it and specify that the result should be padded and returned as Pytorch tensors. The tokenized results are an object from which we extract the encoded text and pass it to the model. The results of the model are then passed through a softmax layer in the case of sentiment analysis to normalize the results as a sentiment score.
(Multi) GPU-enabled inference
The process of inference consists of the following components:
- Dataloader for serving batches of tokenized data
- Model class that performs the inference
- Parallelization of the model on the GPU devices
- Iterating through the data for inference and extracting the results
Dataloader
Pytorch uses the Dataloader abstraction for extracting batches of data to be used either for training or inference purposes. It takes as input an object of a class that extends the ‘Dataset’ class. Here we call that class ‘TextLoader’. It is necessary to have at least two methods in this class :
(a) __len__() : returns the length of the entire data
(b) __getitem__(): extracts and returns a single element of the data
Now Dataloader accepts the object instance of this class named ‘data’ here, along with the batch size of the data to be loaded in a single iteration. Note that I have set the ‘shuffle’ flag to False here, since we want to preserve the order of the data.
Dataloader automatically handles the division of the data that it receives to be utilized by each of the GPU devices. If the data is not evenly divisible, it offers the option to either drop elements or pad a batch with duplicate data points. This is something you might want to keep in mind, especially during the inference or prediction process.
Model class
The model class is fairly similar to the code that we saw above, with the only difference being that it is now wrapped in a nn.module class. The model definition is initialized within __init__ and the forward method applies the model that is loaded from Huggingface.
Model parallelization and GPU dispatch
In Pytorch, a model or variable that is created needs to be explicitly dispatched to the GPU. This can be done by using the ‘.to(‘cuda’) method. If you have multiple GPUs, you can even specify a device id as ‘.to(cuda:0)’. Additionally, in order to benefit from data parallelism and run the training or inference across all the GPU devices on your cluster, one has to wrap the model within ‘DataParallel’.
While this code assumes that you have more than one GPU on your cluster, if that is not the case, the only change required is ‘device_ids’ to [0] or simply not specifying that parameter (the default gpu device will be automatically selected).
Iteration loop
The following loop iterates over the batches of data, transfers the data to the GPU device before passing the data through the model. The results are then concatenated so that they can be exported to a data store.
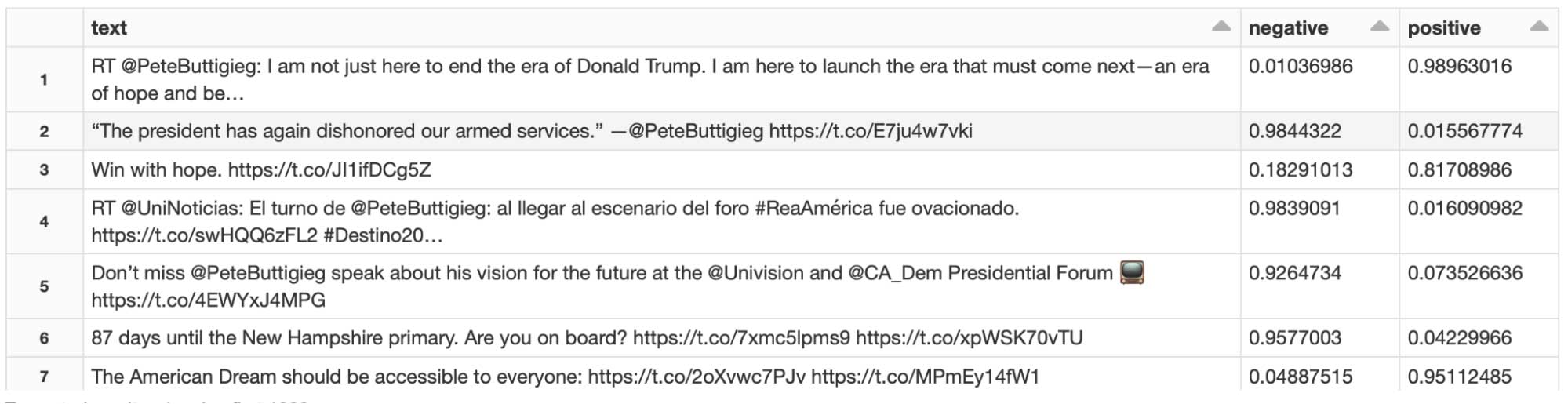
Scalable inference for lots of files
In the example above, the data was read in from a single file, however, when dealing with large amounts of data, it is unlikely that all of this data is available in a single file. The following shows the entire code with the changes highlighted for using the Dataloader with multiple files.
Conclusion
We discussed how the Huggingface framework can be used for performing sentiment analysis using Pytorch. Additionally, it was shown how GPUs could be used to accelerate this inference process. The use of the Databricks platform with the easily available ML runtimes and availability of the state-of-the-art GPUs make it easy to experiment with and deploy these solutions.
For more details, please check out the attached notebook!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.