The Foundation of Your Lakehouse Starts With Delta Lake
Simplify data reliability and data engineering with Delta Lake integrations
by Denny Lee and Vini Jaiswal
It’s been an exciting last few years with the Delta Lake project. The release of Delta Lake 1.0 as announced by Michael Armbrust in the Data+AI Summit in May 2021 represents a great milestone for the open source community and we’re just getting started! To better streamline community involvement and ask, we recently published Delta Lake 2021 H2 Roadmap and associated Delta Lake User Survey (2021 H2) - the result of which we will discuss in a future blog. In this blog, we review the major features released so far and provide an overview of the upcoming roadmap.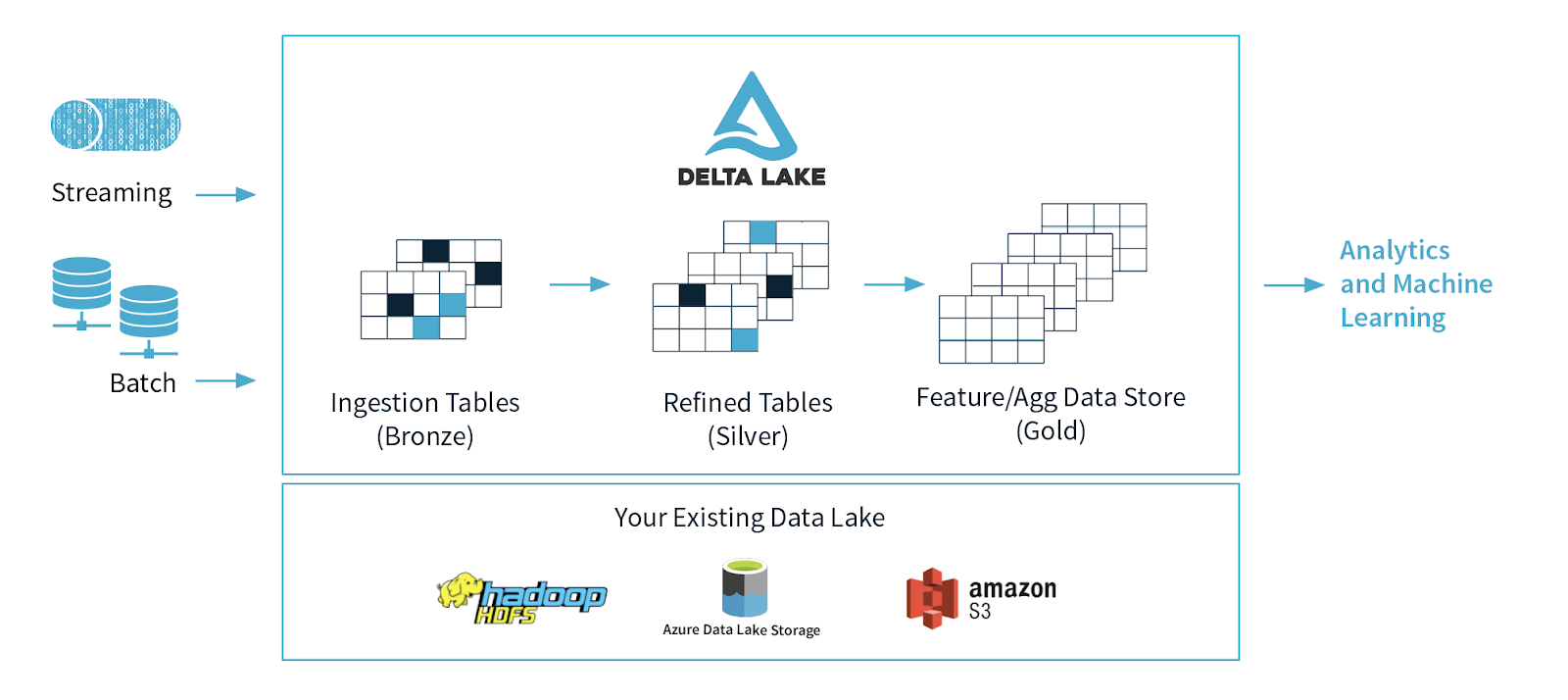
Let’s first start with what Delta Lake is. Delta Lake is an open-source project that enables building a Lakehouse architecture on top of your existing storage systems such as S3, ADLS, GCS, and HDFS. The features of Delta Lake improve both the manageability and performance of working with data in cloud storage objects and enable the lakehouse paradigm that combines the key features of data warehouses and data lakes: standard DBMS management functions usable against low-cost object stores. Together with the multi-hop Delta medallion architecture data quality framework, Delta Lake ensures the reliability of your batch and streaming data with ACID transactions.
Delta Lake adoption
Today, Delta Lake is used all over the world. Exabytes of data get processed daily on Delta Lake, which accounts for 75% of the data that is scanned on the Databricks Platform alone. Moreover, Delta Lake has been deployed to more than 3000 customers in their production lakehouse architectures on Databricks alone!
Delta Lake pace of innovation highlights
The journey to Delta Lake 1.0 has been full of innovation highlights - so how did we get here?

As Michael highlighted in his keynote at the Data + AI Summit 2021, the Delta Lake project was initially created at Databricks based on customer feedback back in 2017. Through continuous collaboration efforts with early adopters, Delta Lake was open-sourced in 2019 and was announced at the Spark+AI Summit keynote by Ali Ghodsi. The first release Delta Lake 0.1 included ACID transactions, schema management, and unified streaming and batch source and sink. Version 0.4 included the support for DML commands and vacuuming for both Scala and Python APIs were added. In version 0.5, Delta Lake saw improvements around compaction and concurrency. It was possible to convert Parquet into Delta Lake tables using SQL only. Other things added in the next version, 0.6, were improvements around merge operations and describe history, which allows you to understand how your table has been evolving over time. In 0.7, the support for different engines like Presto and Athena via manifest generation was added. And finally, a lot of work went into adding merge and other features in the 0.8 release.
To dive deeper into each of these innovations, please check out the blogs below for each of these releases.
- Open Sourcing Delta Lake
- Announcing the Delta Lake 0.3.0 Release
- Simple, Reliable Upserts and Deletes on Delta Lake Tables using Python APIs
- What’s New in Delta Lake 0.5.0 Release -- Presto/Athena Support and More
- Use Delta Lake 0.6.0 to Automatically Evolve Table Schema and Improve Operational Metrics
- Delta Lake Year in Review and Overview
- How to Automatically Evolve Your Nested Column Schema & Stream From a Delta Table & Check Your Constraints
Delta Lake 1.0
The Delta Lake 1.0 release was certified by the community in May 2021 and was announced at the Data and AI summit with a suite of new features that make Delta Lake available everywhere.
Let’s go through each of the features that made it into the 1.0 release.

The key themes of the release covered as part of the ’Announcing Delta Lake 1.0’ keynote can be broken down into the following:
- Generated Columns
- Multi-cluster writes
- Cloud Independence
- Apache Spark™ 3.1 support
- PyPI Installation
- Delta Everywhere
- Connectors
Generated columns
A common problem when working with distributed systems is how you partition your data to better organize your data for ingestion and querying. A common approach is to partition your data by date, as this allows your ingestion to naturally organize the data as new data arrives, as well as query the data by date range.
The problem with this approach is that most of the time, your data column is in the form of a timestamp; if you were to partition by a timestamp, this would result in too many partitions. To partition by date (instead of by milliseconds), you can manually create a date column that is calculated by the insert. The creation of this derived column would require you to manually create columns and manually add predicates; this process is error-prone and can be easily forgotten.
A better solution is to create generated columns, which are a special type of columns whose values are automatically generated based on a user-specified function over other columns that already exist in your Delta table. When you write to a table with generated columns, and you do not explicitly provide values for them, Delta Lake automatically computes the values. For example, you can automatically generate a date column (for partitioning the table by date) from the timestamp column; any writes into the table need only specify the data for the timestamp column.
This can be done using standard SQL syntax to easily support your lakehouse.
Cloud independence
Out of the box, Delta Lake has always worked with a variety of storage systems - Hadoop HDFS, Amazon S3, Azure Data Lake Storage (ADLS) Gen2 - though the cluster would previously be specific for one storage system.
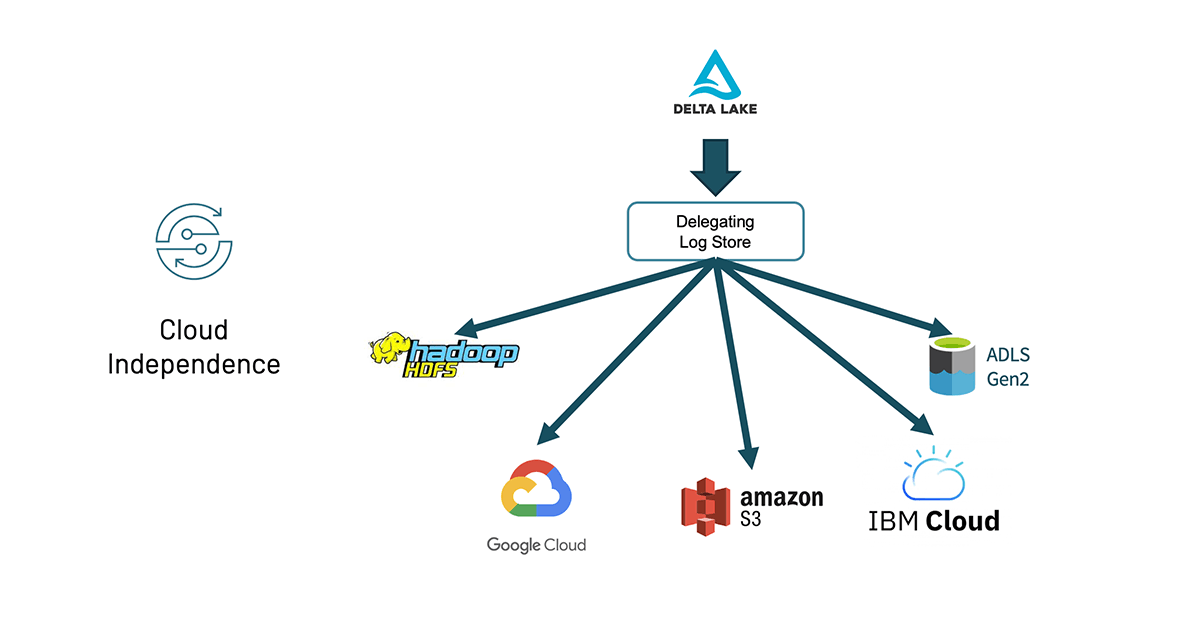
Now, with Delta Lake 1.0 and the DelegatingLogStore, you can have a single cluster that reads and writes from different storage systems. This means you can do federated querying across data stored in multiple clouds or use this for cross-region consolidation. At the same time, the Delta community has been extending support for additional filesystems, including IBM Cloud and Google Cloud Storage (GCS) and Oracle Cloud Infrastructure. For more information, please refer to Storage configuration — Delta Lake Documentation.
Multi-cluster transactions
Delta Lake has always had support for multiple clusters writing to a single table - mediating the updates with an ACID transaction protocol, preventing conflicts. This has worked on Hadoop HDFS, ADLS Gen2, and now Google Cloud Storage. AWS S3 is missing the transactional primitives needed to build this functionality without depending on external systems.
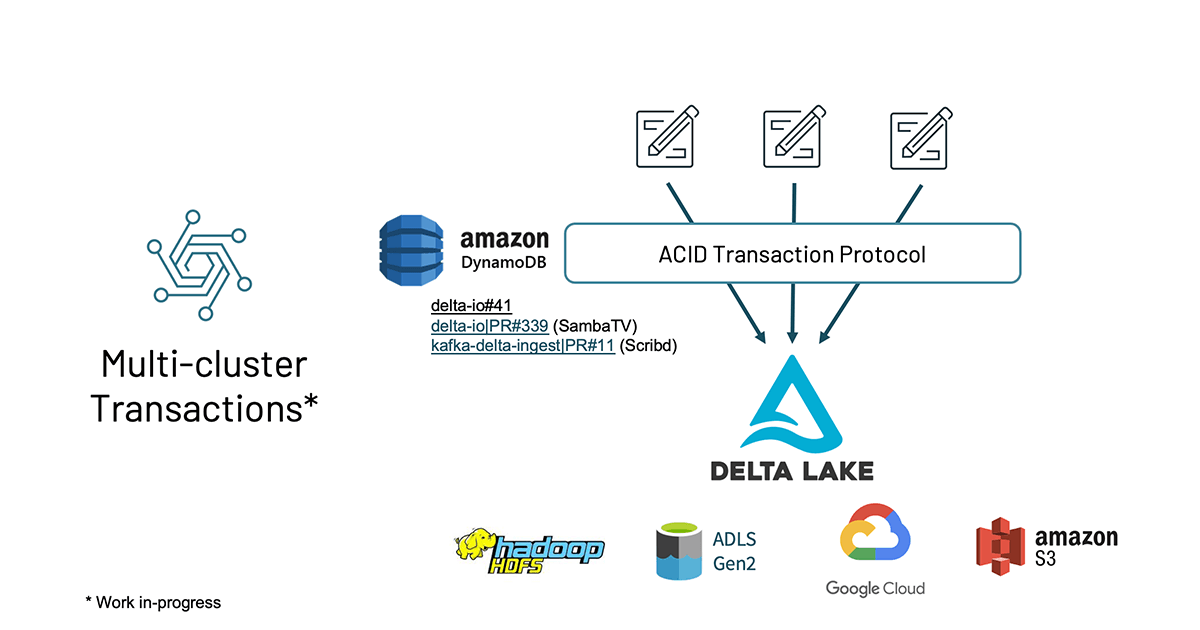
Now, in Delta Lake 1.0, open-source contributors from Scribd and Samba TV are adding support in the Delta transaction protocol to use Amazon DynamoDB to mediate between multiple writers of Amazon S3 endpoints. Now, multiple Delta Lake clusters can read and write from the same table.
Delta Standalone reader
Previously Delta Lake was pretty much an Apache Spark project -- great integration with streaming and batch APIs to read and write from Delta tables. While Apache Spark is integrated seamlessly with Delta, there are a bunch of different engines out there and a variety of reasons you might want to use them.
With the Delta Standalone reader, we’ve created an implementation for the JVM that understands the Delta transaction protocol but doesn’t rely on an Apache Spark cluster. This makes it significantly easier to build support for other engines. We already use the Delta Standalone reader on the Hive connector, and there’s work underway for a Presto connector as well.
Delta Lake Rust implementation
The Delta Rust implementation supports write transactions (though that has not yet been implemented in the other languages).

Now that we've got great Python support it's important to make it easier for Python users to get started. There are two different packages depending on how you're going to be using Delta Lake from Python:
- If you want to use it along with Apache Spark, you can pip install delta-spark, and it'll set up everything you need to run Apache Spark jobs against your Delta Lake
- If you're going to be working with smaller data, use pandas, or use some other library; you no longer need to use Apache Spark to access Delta tables from Python. Users can use pip install deltalake command to install the Delta Rust API with Python bindings.
Delta Lake 1.0 supports Apache Spark 3.1
The Apache Spark community has made a large number of improvements around performance and compatibility. And it is super important that Delta Lake keeps up to date with that innovation.
This means that you can take advantage of increased performance in predicate pushdowns and pruning that are available in Apache Spark 3.1. Furthermore, Delta Lake integration with Apache Spark streaming catalog APIs ensures Delta tables available for streaming are present in the catalog without manually handling the path metadata.

Delta Lake everywhere
With the introduction of all the features that we walked through above, Delta is now available everywhere you could want to use it. This project has come a really long way, and this is what the ecosystem of Delta looks like now.

- Languages: Native code for working with a Delta Lake makes it easy to use your data from a variety of languages. Delta Lake now has the Python, Kafka, and Ruby support using Rust bindings.
- Services: Delta Lake is available from a variety of services, including Databricks, Azure Synapse Analytics, Google DataProc, Confluent Cloud, and Oracle.
- Connectors: There are connectors for all of the popular tools for data engineers, thanks to native support for Delta Lake (standalone reader), through which data can be easily queried from many different databases without the need for any manifest files.
- Databases: Delta Lake is also queryable from many different databases. You can access Delta tables from Apache Spark and other database systems.
Delta Lake OSS:2021 H2 Roadmap
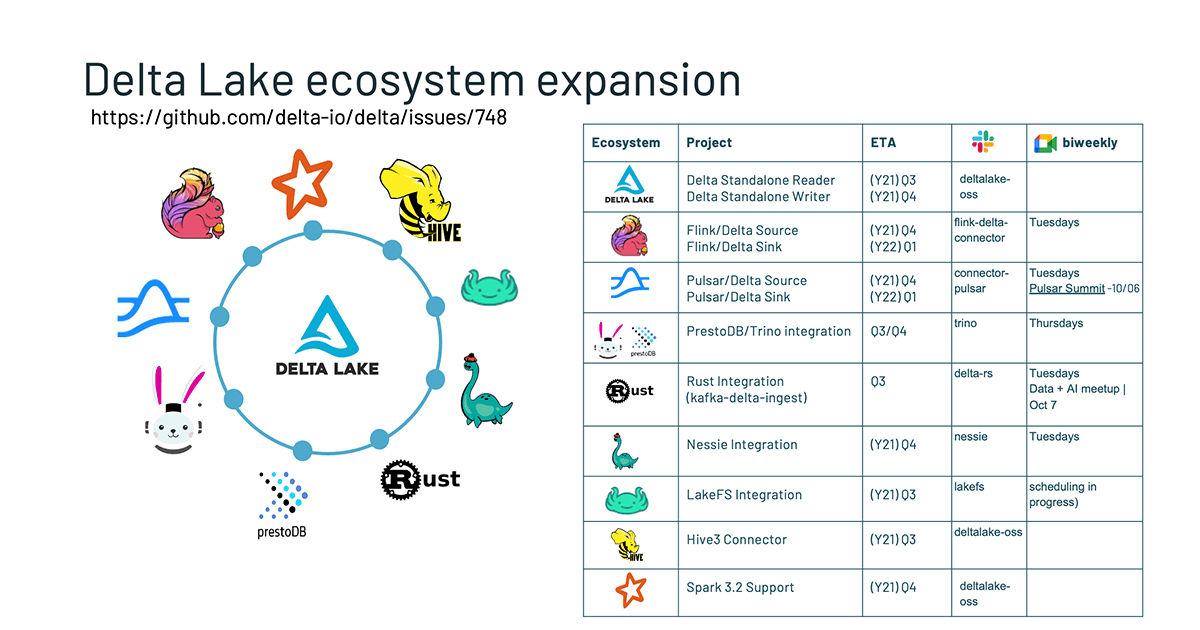
The following are some of the highlights from the ever-expanding Delta Lake ecosystem. For more information, refer to Delta Lake Roadmap 2021 H2: Features Overview by Vini and Denny
The following are some key highlights of the current Delta Lake ecosystem roadmap.
Delta Standalone
The first thing in the roadmap that we want to highlight is the Delta Standalone.
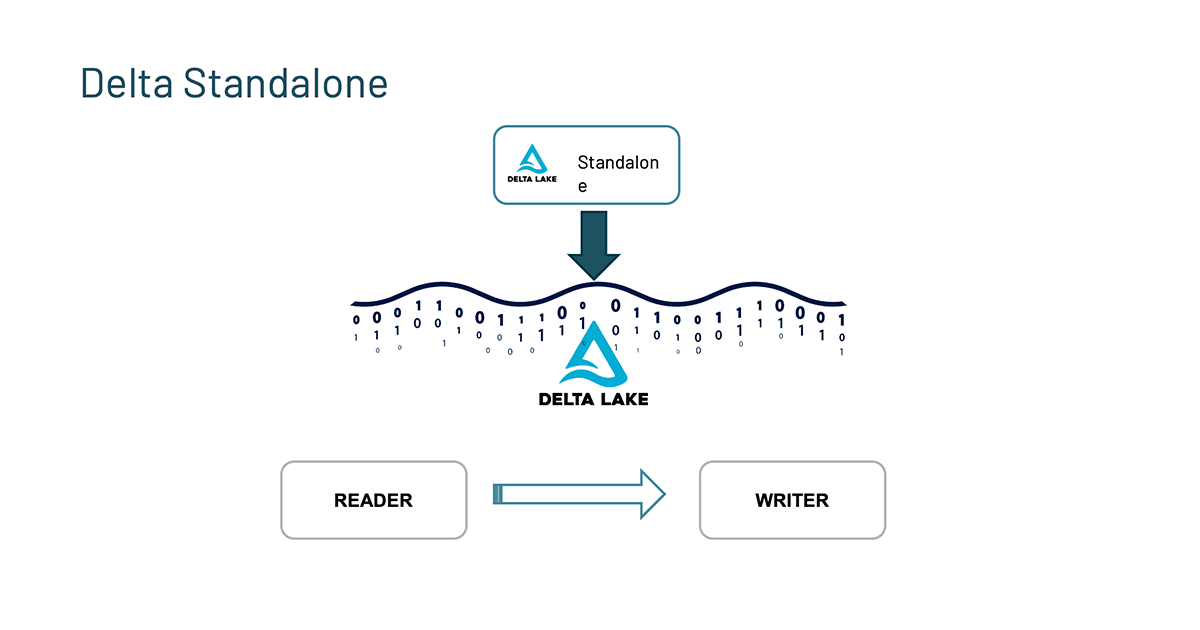
In the Delta Lake 1.0 overview, we covered the Delta Standalone Reader which allows other engines to read from Delta Lake directly without relying on an Apache Spark cluster. Given the demand for write capabilities, the Delta Standalone Writer was the natural next step. Thus, work is underway to build Delta Standalone Writer (DSW #85) that allows developers to write to Delta tables without Apache Spark. It enables developers to build connectors so other streaming engines like Flink, Kafka, and Pulsar can write to Delta tables. For more information, refer to the [2021-09-13] Delta Standalone Writer Design Document.
Flink/Delta sink
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. The most common types of applications that are powered by Flink are event-driven, data analytics, and data pipeline applications. Currently, the community is working on a Flink/Delta Sink (#111) using the upcoming Delta Standalone Writer to allow Flink to write to Delta tables.
If you are interested, you can participate in active discussions on slack #flink-delta-connector or through bi-weekly meetings on Tuesdays.
Pulsar/Delta connector
Pulsar is an open-source streaming project that was originally built at Yahoo! as a streaming platform. The Delta community is bringing streaming enhancements to the Delta Standalone Reader to support Pulsar. There are two connectors that are being worked on - one for reading from the Delta table as a source and another writing to the Delta table as a sink (#112). This is a community effort, and there’s an active slack group that you can join via the Delta Users Slack #connector-pulsar channel or participate in biweekly Tuesdays. For more information, check out the recent Pulsar EU summit where Ryan Zhu and Addison Higham were keynote speakers.

Trino/Delta connector
Trino is an ANSI SQL compliant query engine that works with BI tools such as R, Tableau, Power BI, Superset, etc. The community is working on a Trino/Delta reader leveraging the Delta Standalone Reader. This is a community effort, and all are welcome. Join us via the Delta User Slack channel #trino channel, and we will have bi-weekly meetings on Thursdays.
PrestoDB/Delta connector
Presto is an open-source distributed SQL query engine for running interactive analytic queries
Presto Delta reader will allow Presto to read from Delta tables. It’s a community effort, and you can join the slack #connector-presto. We also have bi-weekly meetings on Thursdays.
Kafka-delta-ingest
delta-rs is a library that provides low-level access to Delta tables in Rust which currently support Python, Kafka, and Ruby bindings. The Rust implementation supports write transactions, and the kafka-delta-ingest project recently went into production as noted in the following tech talk: Tech Talk | Diving into Delta-rs: kafka-delta-ingest.
You can also participate in the discussions by joining slack #kafka-delta-ingest or biweekly Tuesday meetings.
Hive 3 connector
Hive to delta connector is a library to make Hive read Delta Lake tables. We are updating the existing Hive 2 connector just like Delta Standalone Reader to support Hive 3. To participate, you can join the Delta Slack channel or attend our monthly core Delta office hours.
Spark enhancements
We have seen a great pace of innovation in Apache Spark, and with that, we have two main things coming up in the roadmap.
- Support for Apache Spark’s column drop and rename commands
- Support Apache Spark 3.2
Delta Sharing
Another powerful feature of Delta Lake is Delta Sharing. There is a growing demand to share data beyond the walls of the organization with external entities. Users are frustrated by the constraints to how they can share their data and once that data is shared, version control and data freshness are tricky to maintain. For example, take a group of data scientists who are collaborating. They’re in the flow and on the verge of insight but need to analyze another data set. So they submit a ticket and wait. In the two or more weeks it takes them to get that missing data set, time is lost, conditions change, and momentum stalls. Data sharing shouldn’t be a barrier to innovation. This is why we are excited about Delta Sharing, which is the industry’s first open protocol for secure data sharing, making it simple to share data with other organizations regardless of which computing platforms they use.
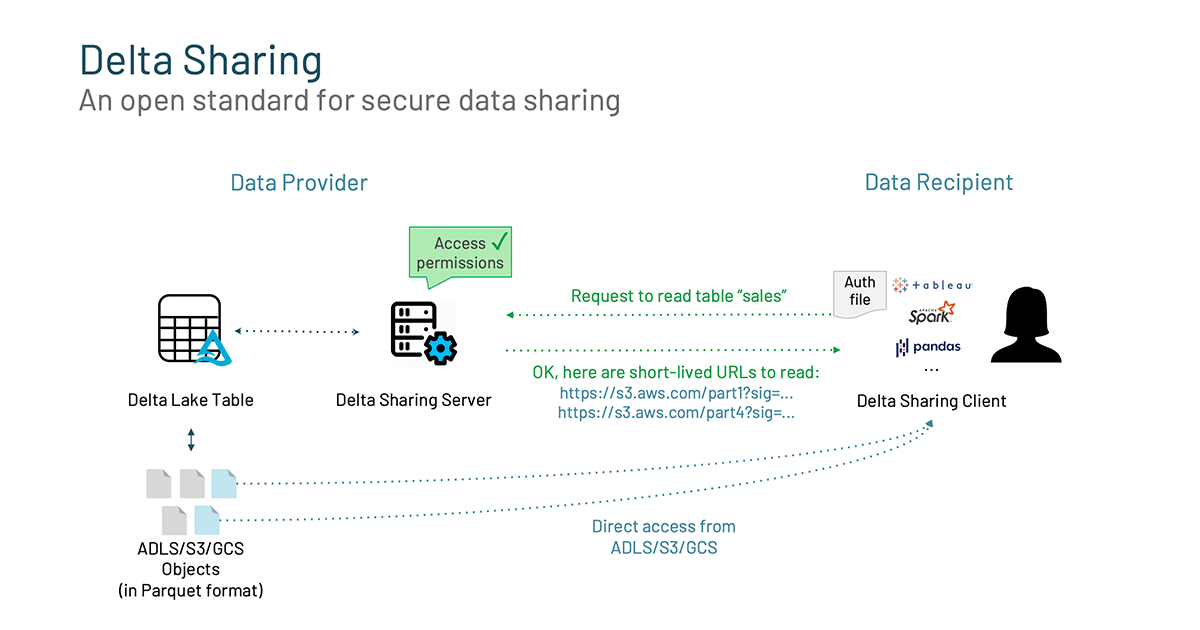
Delta Sharing allows you to:
- Share live data directly: Easily share existing, live data in your Delta Lake without copying it to another system.
- Support diverse clients: Data recipients can directly connect to Delta Shares from Pandas, Apache Spark™, Rust, and other systems without having to first deploy a specific compute platform. Reduce the friction to get your data to your users.
- Security and governance: Delta Sharing allows you to easily govern, track, and audit access to your shared data sets.
- Scalability: Share terabyte-scale datasets reliably and efficiently by leveraging cloud storage systems like S3, ADLS, and GCS.
Delta Lake committers
Since the Delta Lake project is community-driven and with that, we want to highlight a bunch of new Delta Lake committers from many different companies. In particular, we want to highlight the contributions of QP Hou , R. Tyler Croy, Christian Williams, and Mykhailo Osypov from Scribd and Florian Valeye from Back Marketto delta.rs, kafka-delta-ingest, sql-delta-import, and the Delta community.

Delta Lake roadmap in a nutshell
Putting it all together — we reviewed how the Delta Lake community is rapidly expanding from connectors to committers. To learn more about Delta Lake, check out the Delta Lake Definitive Guide, a new O’Reilly book available in Early Release for free.
How to engage in the Delta Lake project
We encourage you to get involved in the Delta community through Slack, Google Groups, GitHub, and more.

Our recently closed Delta Lake survey received over 600 responses. We will be analyzing and publishing the survey results to help guide the Delta Lake community. For those of you who would like to provide your feedback, please join one of the many Delta community forums.
For those that completed the survey, you will receive Delta swag and get a chance to win a hard copy of the upcoming Delta Lake Definitive Guide authored by TD, Denny, and Vini (you can download the raw, unedited early preview now)!

With that, we want to conclude the blog with a quote from R. Tyler Croy, Director of Platform Engineering, Scribd:
“With Delta Lake 1.0, Delta Lake is now ready for every workload!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.