Taming JavaScript Exceptions With Databricks
This post is a part of our blog series on our frontend work. You can see the previous one on “Simplifying Data + AI, One Line of TypeScript at a Time.” and “Building the Next Generation Visualization Tools at Databricks.”
At Databricks, we take the quality of our customer experience very seriously. As such, we track many metrics for product reliability. One metric we focus on is the percentage of sessions that see no JavaScript (JS) exceptions. Our goal is to keep this happy case above 99.9%, but historically, these issues have been tracked manually, which for many reasons wasn't sufficient for keeping errors at bay.
In the past, we used Sentry to aggregate and categorize a variety of exceptions, including those from JS. Sentry both ingests the errors and, on the front end, aggregates sourcemaps to decode minified stack traces.
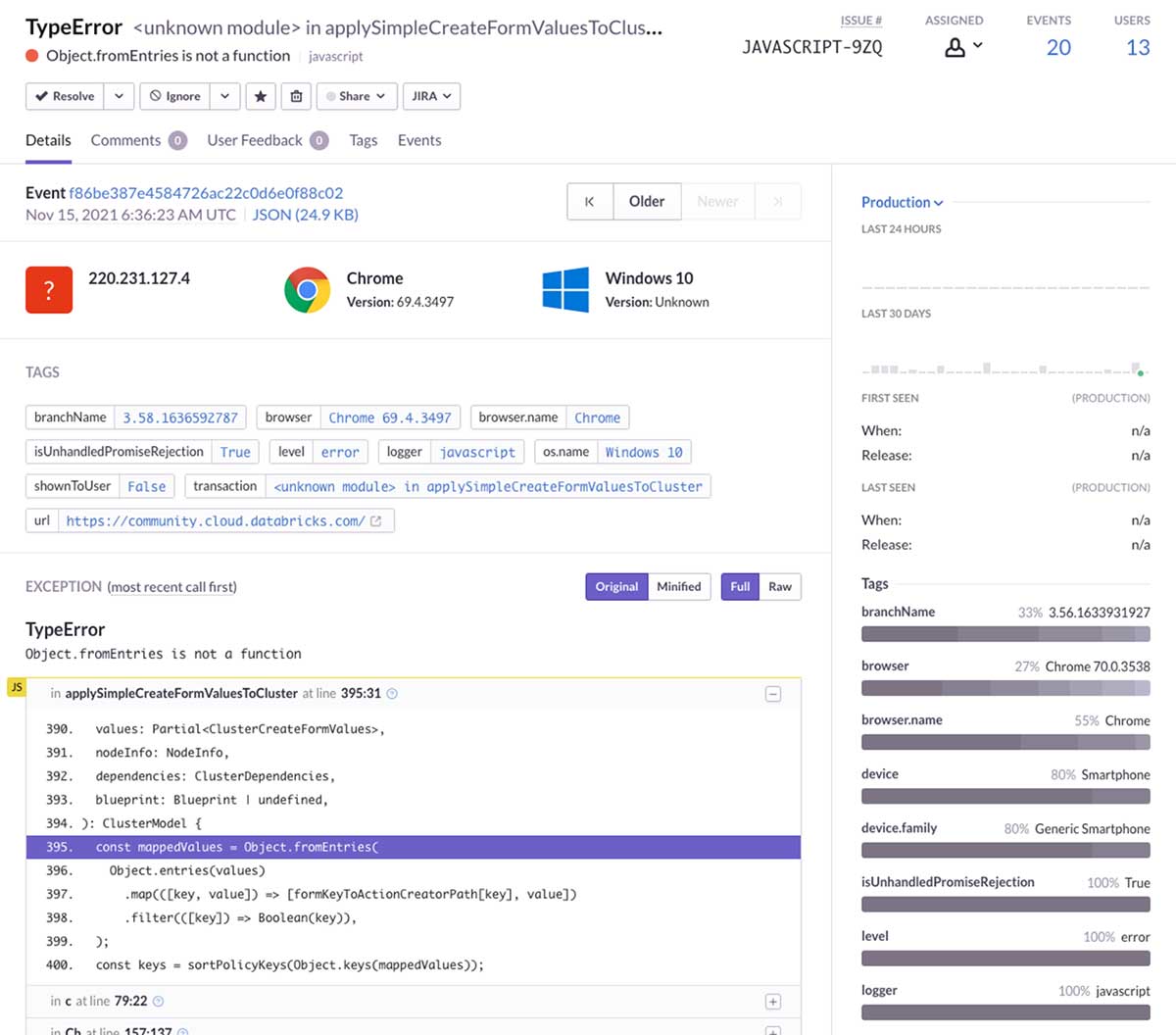
Using Databricks to track JS exceptions
While considering how we could better automate our exception tracking and, thus, decrease the number of issues being shipped out, we looked into extending Sentry. Unfortunately, we found that the effort required was high. As we looked into what Sentry was solving for our use case, we realized that Databricks' products could largely accomplish the same tasks, with an easier path for extensibility.
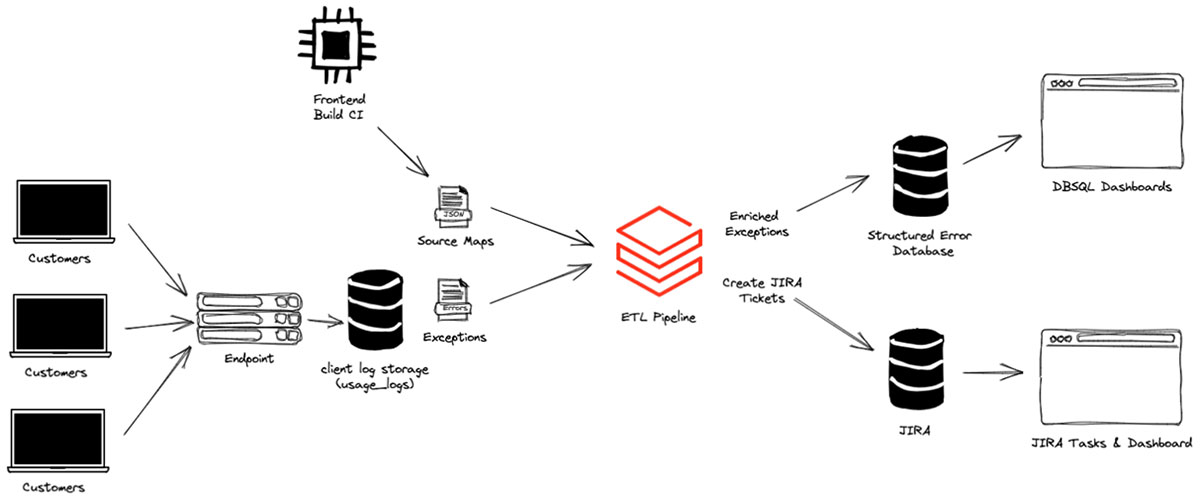
First, Databricks is more than a data platform; it's essentially a general-purpose computing and app infrastructure that sits on top of your data. This lets you create an ETL where you ingest all kinds of information and apply programmatic transformations, all from within the web product.
And once you’ve constructed that ETL, you can use the results to build dynamic dashboards, connect to third-party APIs or anything else. Databricks even has GUIs to orchestrate pipelines of tasks and handles alerting when anything fails.
With that in mind, our challenge was to build an internal, maintainable pipeline for our JS exceptions, with the goal of automatically creating tickets whenever we detected issues in staging or production.
Moving from Sentry to Databricks
Aggregating into Delta
The first step in constructing our ETL was to find our source of truth. This was our usage_logs table, which contains a wide variety of different logs and metrics for customer interactions with the product. Every JS exception was stored here with the minified stack traces.
We started by building a Databricks Notebook to process our usage_logs. This table is gigantic and difficult to optimize, so querying it for exceptions can take thirty minutes or more. So, we aggregated the data we wanted into a standalone Delta Table, which enabled us to query and slice the data (approximately a year's worth of exceptions) in seconds.
Data enrichment: stack trace decoding
Critically, we needed to find a way to decode the minified stack traces in our usage_logs as a part of the ETL. This would let us know what file and line caused a given issue and take further steps to enrich the exception based on that knowledge.
The first step here was to store our sourcemaps in an AWS S3 bucket as a part of our build. Databricks helpfully gives you the ability to mount S3 buckets into your workspace's file system, which makes those sourcemaps easily-accessible to our code.
Once we had the sourcemaps in S3, we had the ability to decode the stack traces on Databricks. This was done entirely in Databricks Notebooks, which have the ability to install Python libraries via pip. We installed the sourcemap package to handle the decode, then built a small Python script to evaluate a given stacktrace and fetch the relevant sourcemaps from the file system.
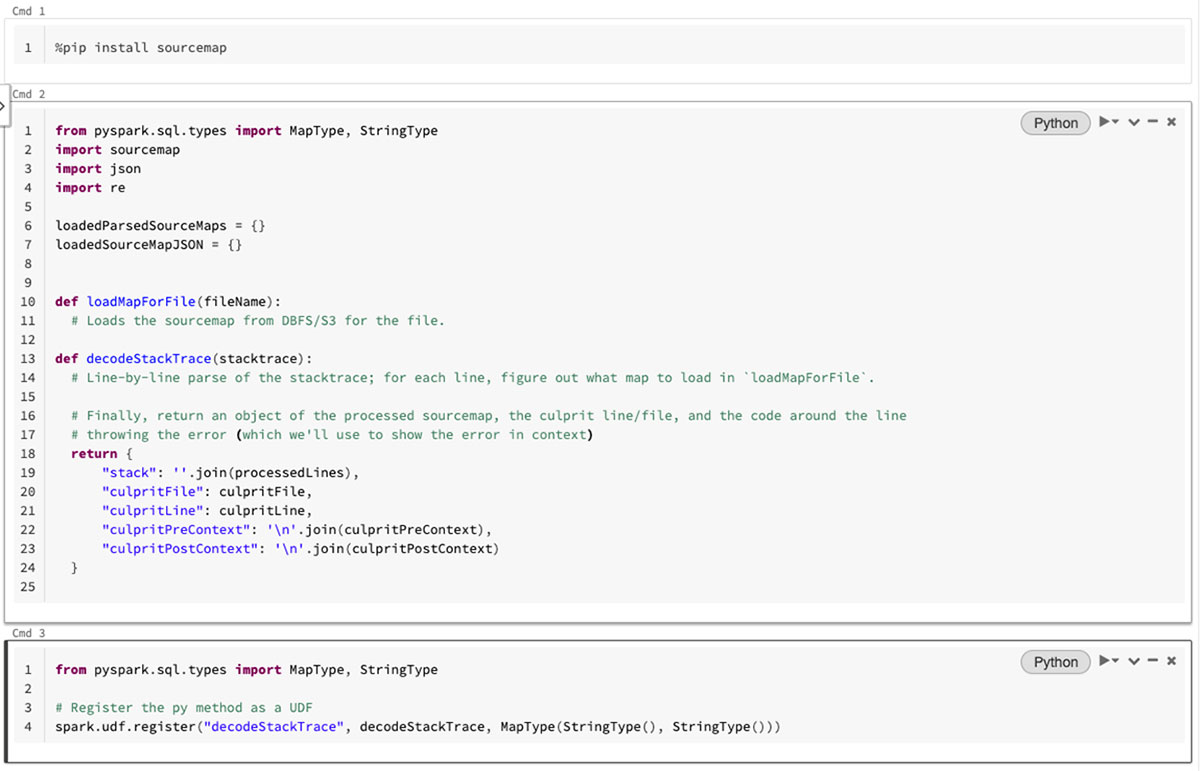
Once we had that, we wrapped the script in a UDF so that we could run it directly from SQL queries in our notebooks! This gave us the ability to decode the stack trace and return the file that caused the error, the line and context of source code, and the decoded stack itself, all of which were saved in separate columns.
Code ownership
Once we decoded the stack traces, we had high confidence on which file was responsible for each error and could use that to determine which team owned the issue. To do this, we used Github's API to crawl the repository, find the nearest OWNERS file and map the owning team to a JIRA component.
We built this into another UDF and added it to our aggregator, so when an exception came in, it was pre-triaged to the correct team!
Databricks SQL dashboards
To gain visibility into what was going on in the product, we used Databricks SQL to build dashboards for high-level metrics. This helped us visualize trends and captured the fine-grain issues happening in the current release.
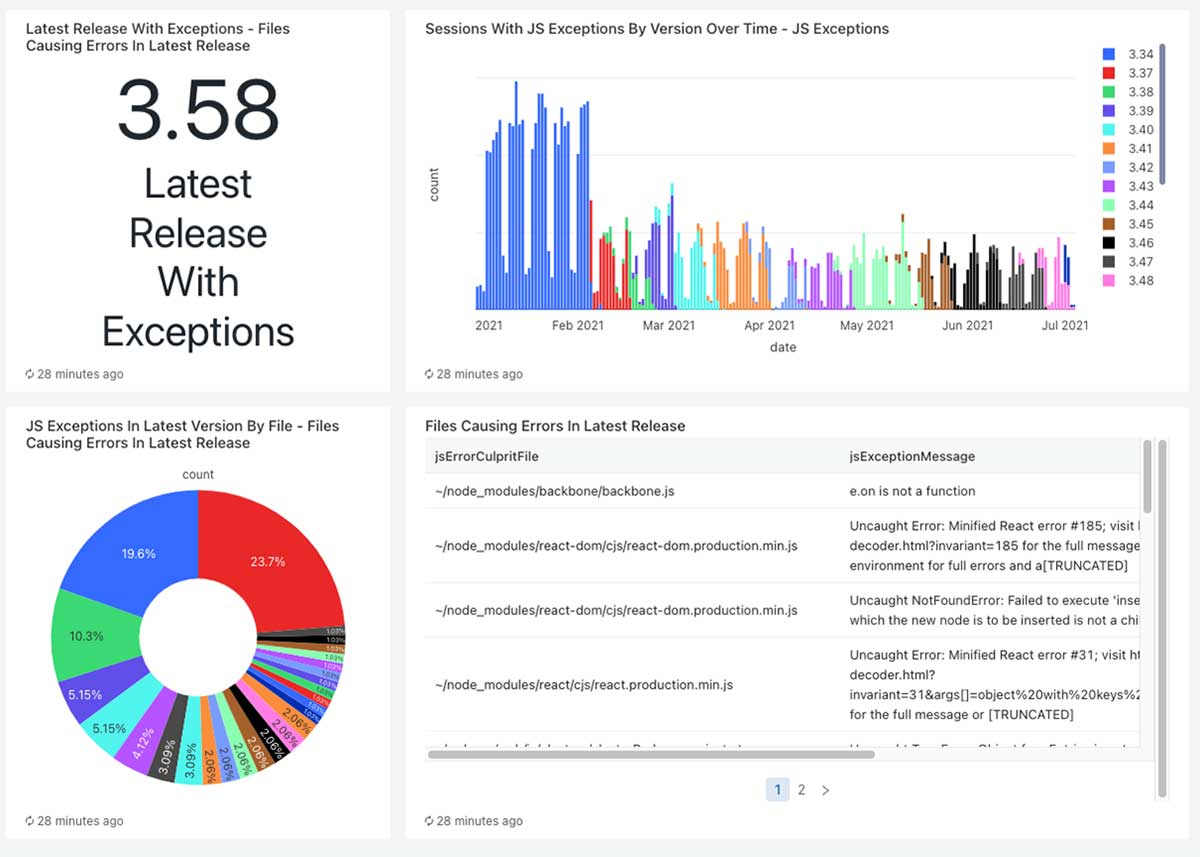
We also built dashboards for analyzing particular issues, which show error frequency, variations of the error and more. This, in effect, replaces Sentry’s UI, and we can augment it to provide whichever data is the most relevant to our company.
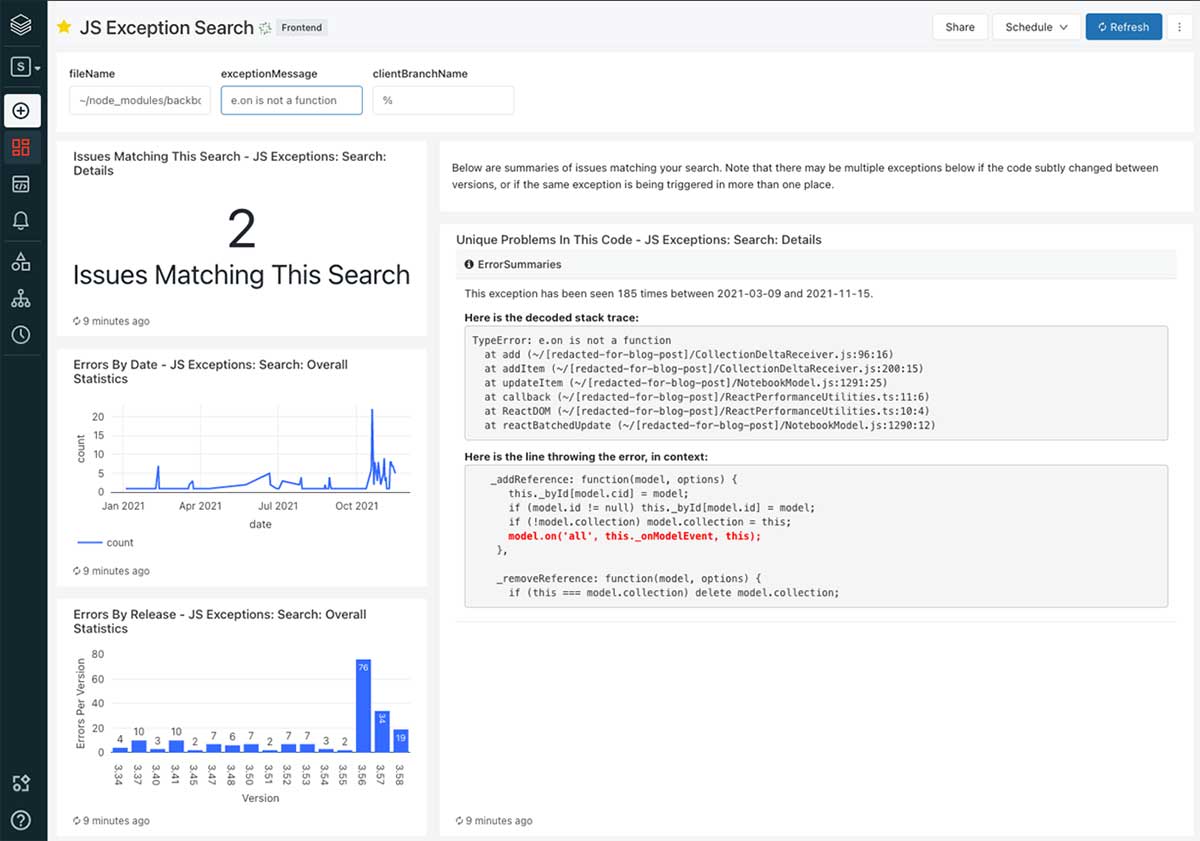
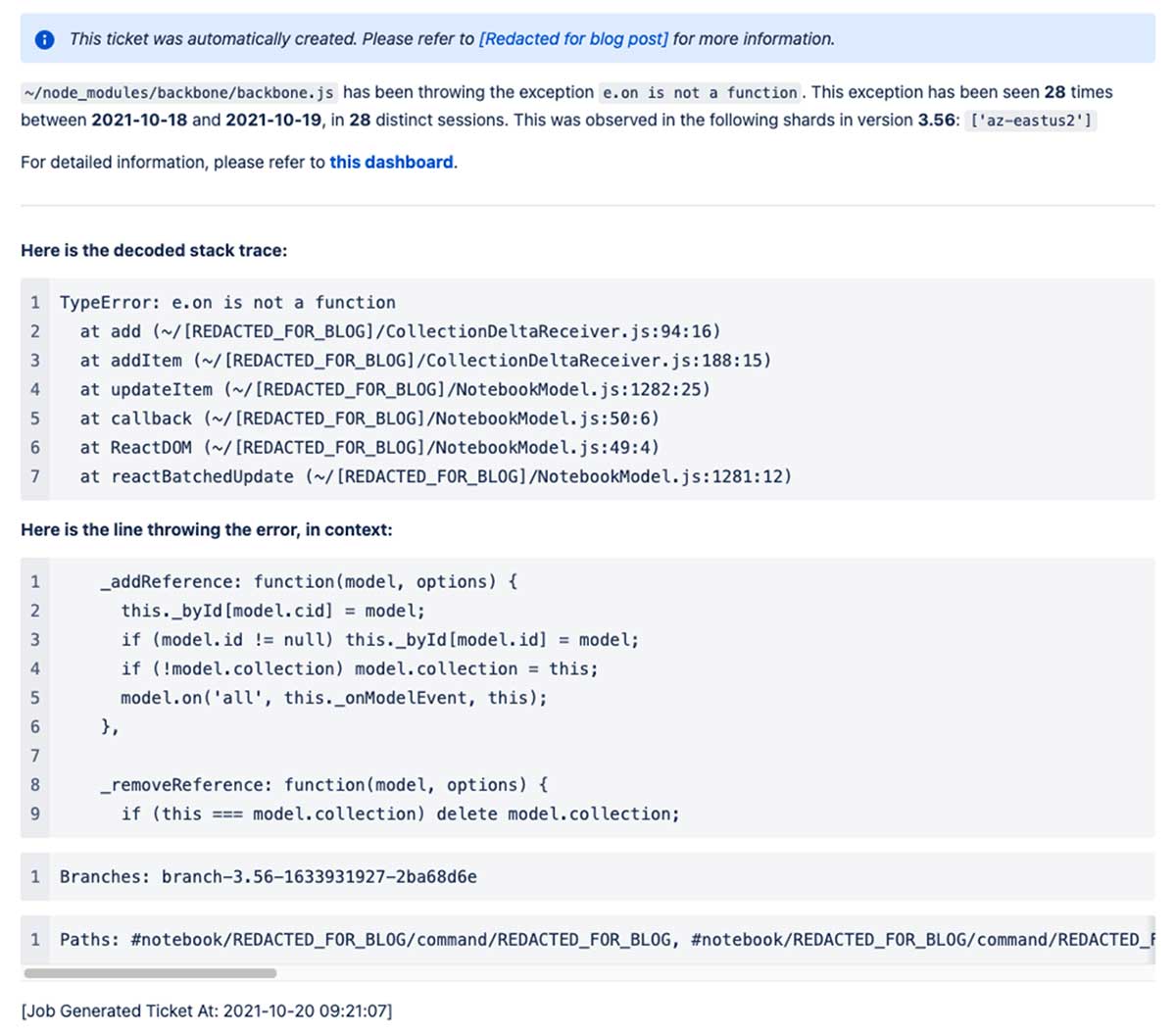
Ticketing
Once we had our ETL built and populated, we looked at the incident frequency in staging and production relative to the number of Databricks users in those environments. We decided that it made sense to automatically raise a JIRA ticket anytime an exception occurred in staging, while in production, we set the threshold at ten distinct sessions during a release.
This immediately raised dozens of tickets. The majority were in some way or another known but were all low enough impact that the team hadn't tackled them. In aggregate, however, dozens of small tickets were greatly regressing our experience. Around this time, we calculated that 20% of sessions saw at least one error!
With all the data we could pull and enrich, our engineers were able to effectively jump right into a fix rather than wading through different services and logs to get the information they needed to act. As a result, we quickly burned down a large portion of our issues and got back above our 99.9% error-free goal.
Task orchestration with Jobs
When executing our pipeline, we have one notebook that handles the ETL and another that compares the state of the delta table to JIRA and opens any necessary issues. Running these requires some orchestration, but luckily, Databricks Jobs makes it easy to handle this.
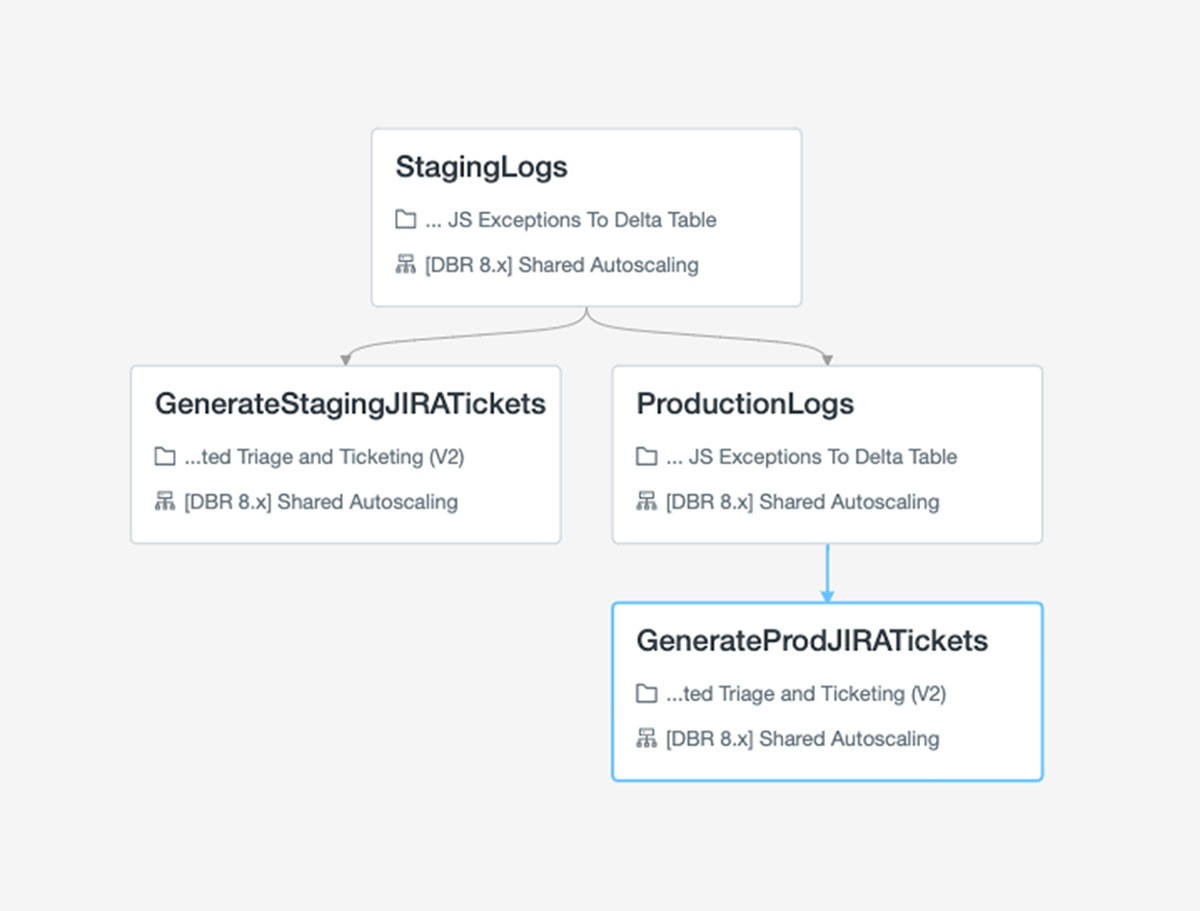
With Jobs, we can run those notebooks for staging and production in sequence. This is very easy to set up in the web GUI to handle routing of failures to our team's alert inbox.
Final thoughts
Overall, the products we’ve been building at Databricks are incredibly powerful and give us the capability to build bespoke tracking and analytics for anything we’re working on. We're using processes like these to monitor frontend performance, keep track of React component usage, manage dashboards for code migrations and much more.
Projects like this one present us with an opportunity to use our products as a customer would, to feel their pain and joy and to give other teams the feedback they need to make Databricks even better.
If working on a platform like this sounds interesting, we're hiring! There's an incredible variety of frontend work being done and being planned, and we could use your help. Come and join us!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.