Functional Workspace Organization on Databricks
Databricks Admin Essentials: Blog 1/5
by Anindita Mahapatra and Greg Wood
Introduction
This blog is part one of our Admin Essentials series, where we’ll focus on topics that are important to those managing and maintaining Databricks environments. Keep an eye out for additional blogs on data governance, ops & automation, user management & accessibility, and cost tracking & management in the near future!
In 2020, Databricks began releasing private previews of several platform features known collectively as Enterprise 2.0 (or E2); these features provided the next iteration of the Lakehouse platform, creating the scalability and security to match the power and speed already available on Databricks. When Enterprise 2.0 was made publicly available, one of the most anticipated additions was the ability to create multiple workspaces from a single account. This feature opened new possibilities for collaboration, organizational alignment, and simplification. As we have found since, however, it has also raised a host of questions. Based on our experience across enterprise customers of every size, shape and vertical, this blog will lay out answers and best practices to the most common questions around workspace management within Databricks; at a fundamental level, this boils down to a simple question: exactly when should a new workspace be created? Specifically, we’ll highlight the key strategies for organizing your workspaces, and best practices of each.
Workspace organization basics
Although each cloud provider (AWS, Azure and GCP) has a different underlying architecture, the organization of Databricks workspaces across clouds is similar. The logical top level construct is an E2 master account (AWS) or a subscription object (Azure Databricks/GCP). In AWS, we provision a single E2 account per organization that provides a unified pane of visibility and control to all workspaces. In this way, your admin activity is centralized, with the ability to enable SSO, Audit Logs, and Unity Catalog. Azure has relatively less restriction on creation of top-level subscription objects; however, we still recommend that the number of top-level subscriptions used to create Databricks workspaces be controlled as much as possible. We will refer to the top-level construct as an account throughout this blog, whether it is an AWS E2 account or GCP/Azure subscription.
Within a top-level account, multiple workspaces can be created. The recommended max workspaces per account is between 20 and 50 on Azure, with a hard limit on AWS. This limit arises from the administrative overhead that stems from a growing number of workspaces: managing collaboration, access, and security across hundreds of workspaces can become an extremely difficult task, even with exceptional automation processes. Below, we present a high-level object model of a Databricks account.
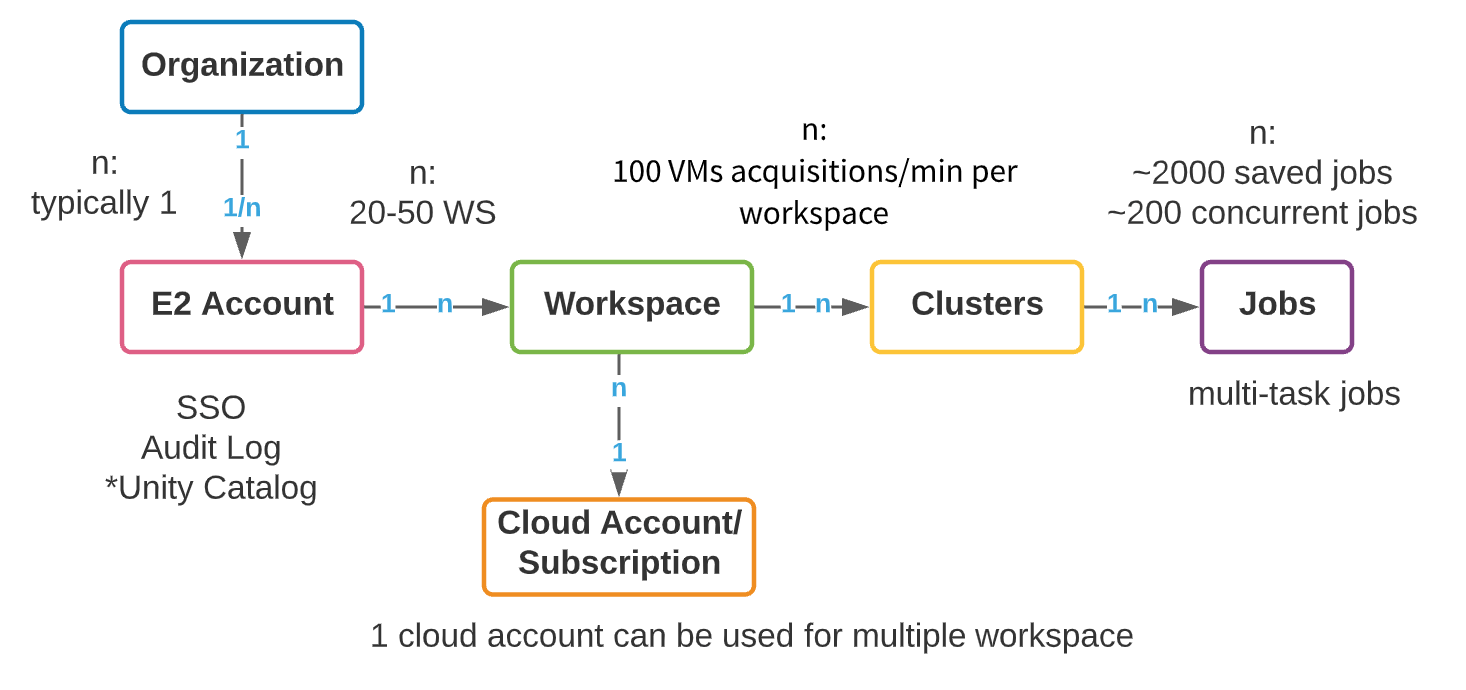
Enterprises need to create resources in their cloud account to support multi-tenancy requirements. The creation of separate cloud accounts and workspaces for each new use case does have some clear advantages: ease of cost tracking, data and user isolation, and a smaller blast radius in case of security incidents. However, account proliferation brings with it a separate set of complexities – governance, metadata management and collaboration overhead grow along with the number of accounts. The key, of course, is balance. Below, we’ll first go through some general considerations for enterprise workspace organization; then, we’ll go through two common workspace isolation strategies that we see among our customers: LOB-based and product-based. Each has strengths, weaknesses and complexities that we will discuss before giving best practices.
General workspace organization considerations
When designing your workspace strategy, the first thing we often see customers jump to is the macro-level organizational choices; however, there are many lower-level decisions that are just as important! We’ve compiled the most pertinent of these below.
A simple three-workspace approach
Although we spend most of this blog talking about how to split your workspaces for maximum effectiveness, there are a whole class of Databricks customers for whom a single, unified workspace per environment is more than enough! In fact, this has become more and more practical with the rise of features like Repos, Unity Catalog, persona-based landing pages, etc. In such cases, we still recommend the separation of Development, Staging and Production workspaces for validation and QA purposes. This creates an environment ideal for small businesses or teams that value agility over complexity.
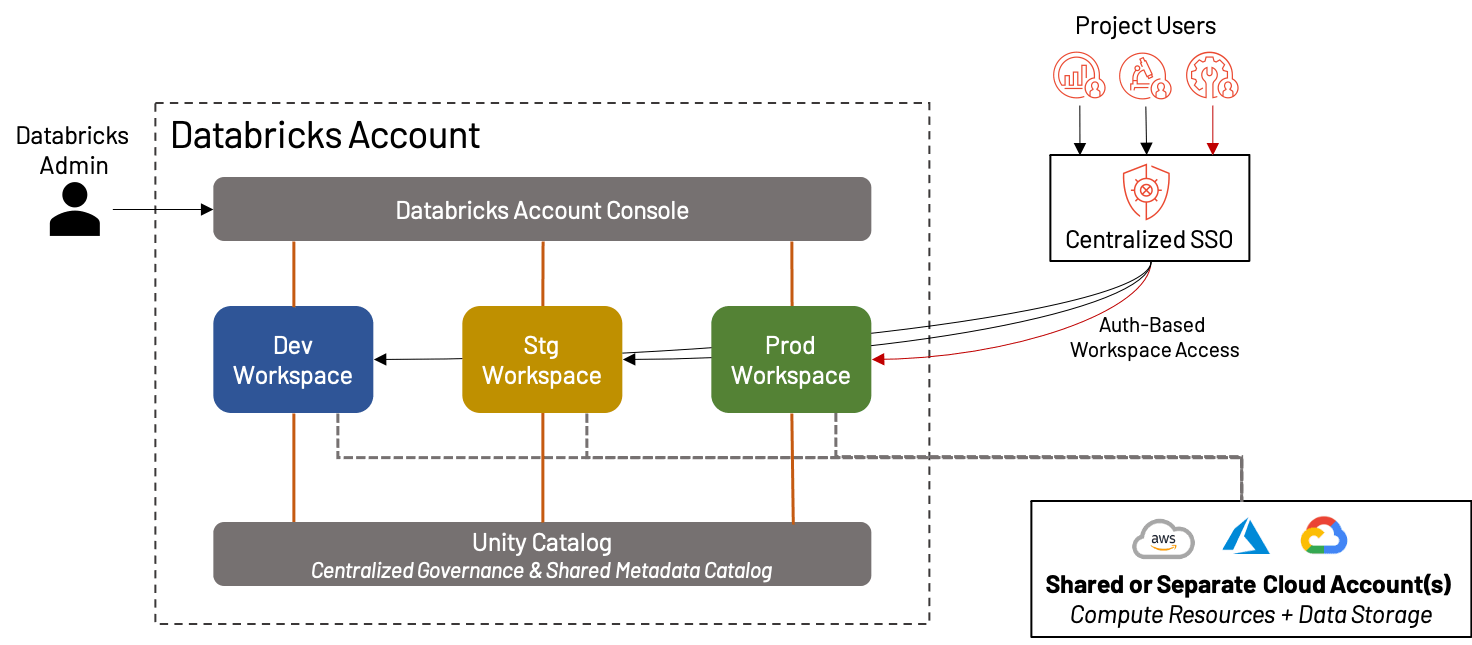
The benefits and drawbacks of creating a single set of workspaces are:
+ There is no concern of cluttering the workspace internally, mixing assets, or diluting the cost/usage across multiple projects/teams; everything is in the same environment
+ Simplicity of organization means reduced administrative overhead
- For larger organizations, a single dev/stg/prd workspace is untenable due to platform limits, clutter, inability to isolate data, and governance concerns
If a single set of workspaces seems like the right approach for you, the following best practices will help keep your Lakehouse operating smoothly:
- Define a standardized process for pushing code between the various environments; because there is only one set of environments, this may be simpler than with other approaches. Leverage features such as Repos and Secrets and external tools that foster good CI/CD processes to make sure your transitions occur automatically and smoothly.
- Establish and regularly review Identity Provider groups that are mapped to Databricks assets; because these groups are the primary driver of user authorization in this strategy, it is crucial that they be accurate, and that they map to the appropriate underlying data and compute resources. For example, most users likely do not need access to the production workspace; only a small handful of engineers or admins may have the permissions.
- Keep an eye on your usage and know the Databricks Resource Limits; if your workspace usage or user count starts to grow, you may need to consider adopting a more involved workspace organization strategy to avoid per-workspace limits. Leverage resource tagging wherever possible in order to track cost and usage metrics.
Leveraging sandbox workspaces
In any of the strategies mentioned throughout this article, a sandbox environment is a good practice to allow users to incubate and develop less formal, but still potentially valuable work. Critically, these sandbox environments need to balance the freedom to explore real data with protection against unintentionally (or intentionally) impacting production workloads. One common best practice for such workspaces is to host them in an entirely separate cloud account; this greatly limits the blast radius of users in the workspace. At the same time, setting up simple guardrails (such as Cluster Policies, limiting the data access to “play” or cleansed datasets, and closing down outbound connectivity where possible) means users can have relative freedom to do (almost) whatever they want to do without needing constant admin supervision. Finally, internal communication is just as important; if users unwittingly build an amazing application in the Sandbox that attracts thousands of users, or expect production-level support for their work in this environment, those administrative savings will evaporate quickly.
Best practices for sandbox workspaces include:
- Use a separate cloud account that does not contain sensitive or production data.
- Set up simple guardrails so that users can have relative freedom over the environment without needing admin oversight.
- Communicate clearly that the sandbox environment is “self-service.”
Data isolation & sensitivity
Sensitive data is growing in prominence among our customers in all verticals; data that was once limited to healthcare providers or credit card processors is now becoming source for understanding patient analysis or customer sentiment, analyzing emerging markets, positioning new products, and almost anything else you can think of. This wealth of data comes with high potential risk, with ever-increasing threats of data breaches; for this reason, keeping sensitive data segregated and protected is important no matter what organizational strategy you choose. Databricks provides several means to protect sensitive data (such as ACLs and secure sharing), and combined with cloud provider tools, can make the Lakehouse you build as low-risk as possible. Some of the best practices around Data Isolation & Sensitivity include:
- Understand your unique data security needs; this is the most important point. Every business has different data, and your data will drive your governance.
- Apply policies and controls at both the storage level and at the metastore. S3 policies and ADLS ACLs should always be applied using the principle of least-access. Leverage Unity Catalog to apply an additional layer of control over data access.
- Separate your sensitive data from non-sensitive data both logically and physically; many customers use entirely separate cloud accounts (and Databricks workspaces) for sensitive and non-sensitive data.
DR and regional backup
Disaster Recovery (DR) is a broad topic that is important whether you use AWS, Azure or GCP; we won’t cover everything in this blog, but will rather focus on how DR and Regional considerations play into workspace design. In this context, DR implies the creation and maintenance of a workspace in a separate region from the standard Production workspace.
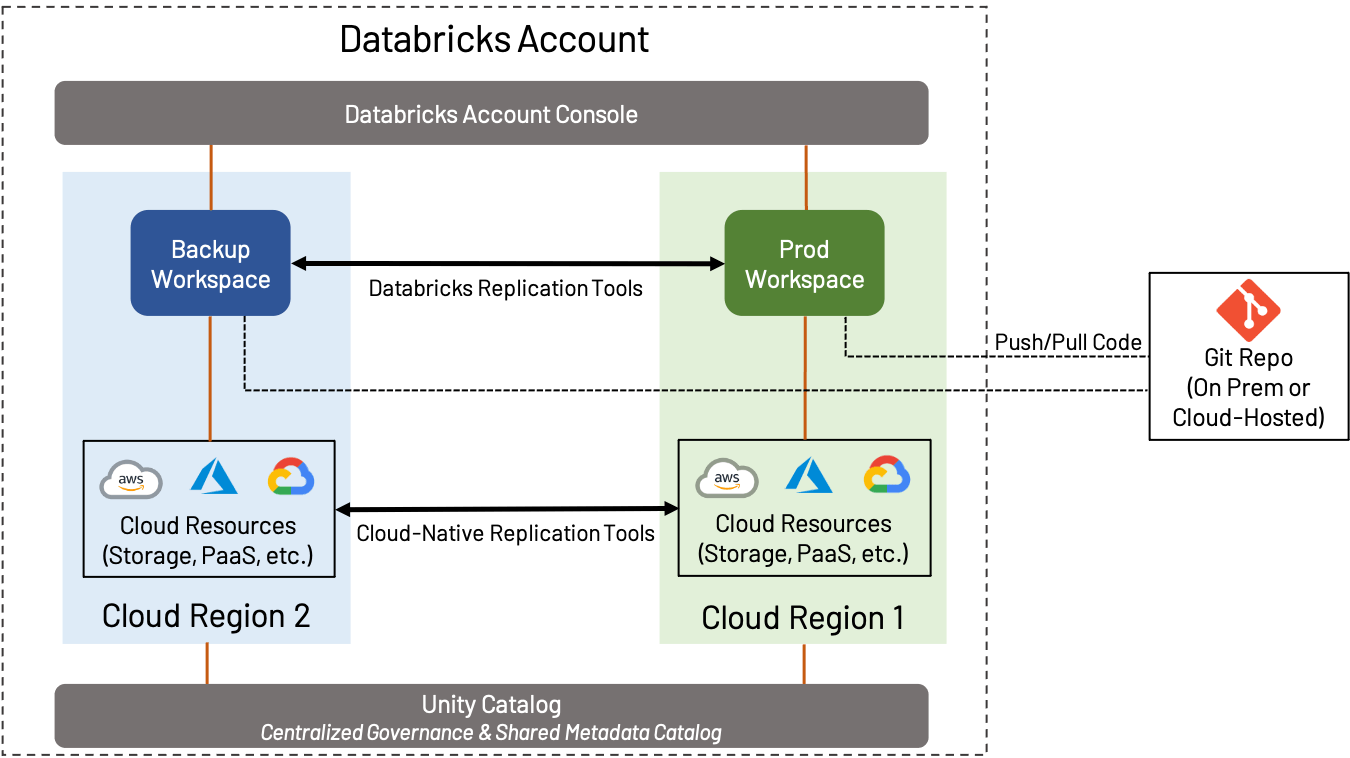
DR strategy can vary widely depending on the needs of the business. For example, some customers prefer to maintain an active-active configuration, where all assets from one workspace are constantly replicated to a secondary workspace; this provides the maximum amount of redundancy, but also implies complexity and cost (constantly transferring data cross-region and performing object replication and deduplication is a complicated process). On the other hand, some customers prefer to do the minimum necessary to ensure business continuity; a secondary workspace may contain very little until failover occurs, or may be backed up only on an occasional basis. Determining the right level of failover is crucial.
Regardless of what level of DR you choose to implement, we recommend the following:
- Store code in a Git repository of your choice, either on-prem or in the cloud, and use features such as Repos to sync it to Databricks wherever possible.
- Whenever possible, use Delta Lake in conjunction with Deep Clone to replicate data; this provides an easy, open-source way to efficiently back up data.
- Use the cloud-native tools provided by your cloud provider to perform backup of things such as data not stored in Delta Lake, external databases, configurations, etc.
- Use tools such as Terraform to back up objects such as notebooks, jobs, secrets, clusters, and other workspace objects.
Remember: Databricks is responsible for maintaining regional workspace infrastructure in the Control Plane, but you are responsible for your workspace-specific assets, as well as the cloud infrastructure your production jobs rely upon.
Isolation by line of business (LOB)
We now dive into the actual organization of workspaces in an enterprise context. LOB-based project isolation grows out of the traditional enterprise-centric way of looking at IT resources – it also carries many traditional strengths (and weaknesses) of LOB-centric alignment. As such, for many large businesses, this approach to workspace management will come naturally.
In an LOB-based workspace strategy, each functional unit of a business will receive a set of workspaces; traditionally, this will include development, staging, and production workspaces, although we have seen customers with up to 10 intermediate stages, each potential with their own workspace (not recommended)! Code is written and tested in DEV, then promoted (via CI/CD automation) to STG, and finally lands in PRD, where it runs as a scheduled job until being deprecated. Environment type and independent LOB are the primary reasons to initiate a new workspace in this model; doing so for every use case or data product may be excessive.
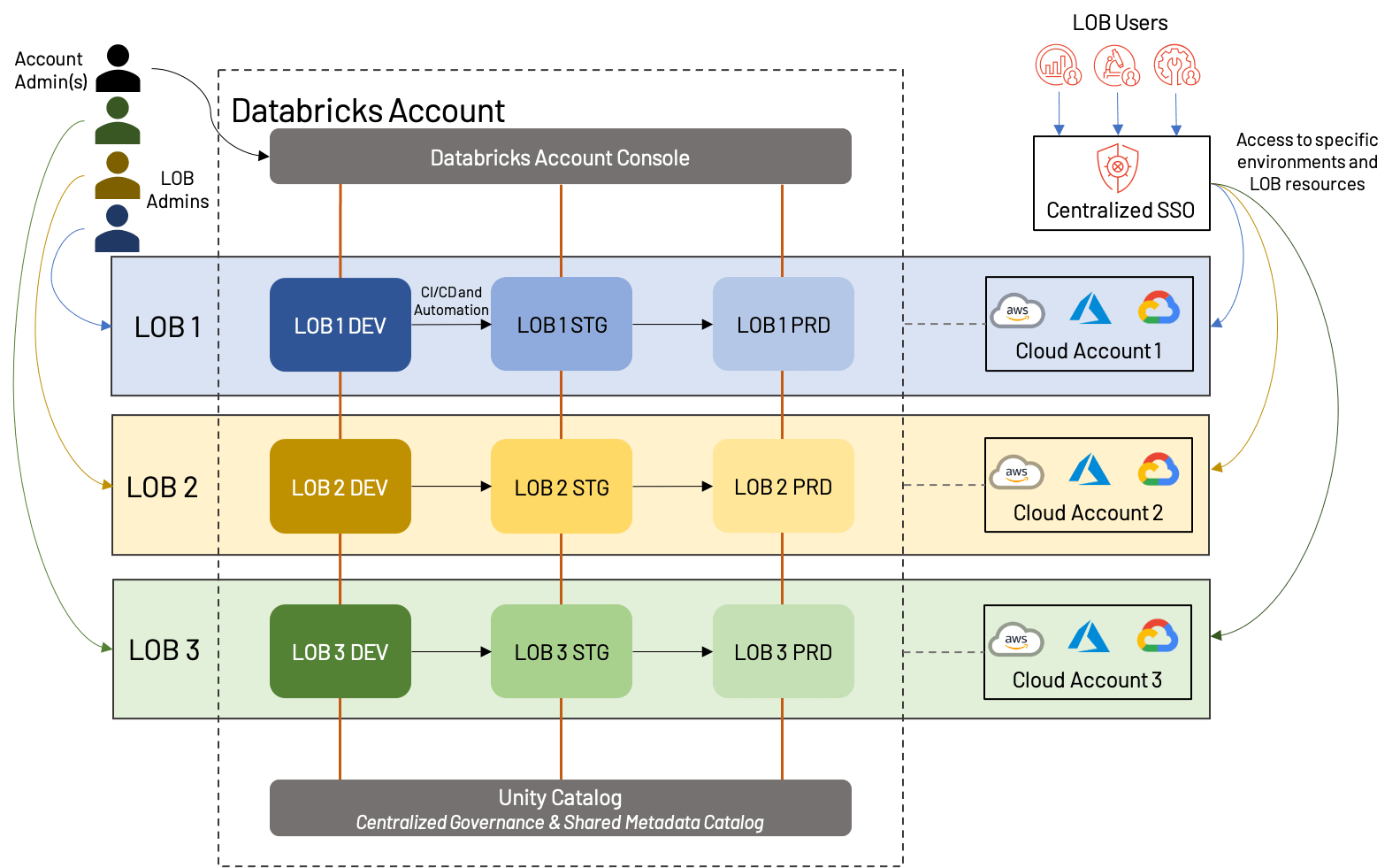
The above diagram shows one potential way that LOB-based workspace can be structured; in this case, each LOB has a separate cloud account with one workspace in each environment (dev/stg/prd) and also has a dedicated admin. Importantly, all of these workspaces fall under the same Databricks account, and leverage the same Unity Catalog. Some variations would include sharing cloud accounts (and potentially underlying resources such as VPCs and cloud services), using a separate dev/stg/prd cloud account, or creating separate external metastores for each LOB. These are all reasonable approaches that depend heavily on business needs.
Overall, there are a number of benefits, as well as a few drawbacks to the LOB approach:
+Assets for each LOB can be isolated, both from a cloud perspective and from a workspace perspective; this makes for simple reporting/cost analysis, as well as a less cluttered workspace.
+Clear division of users and roles improves the overall governance of the Lakehouse, and reduces overall risk.
+Automation of promotion between environments creates an efficient and low-overhead process.
-Up-front planning is required to ensure that cross-LOB processes are standardized, and that the overall Databricks account will not hit platform limits.
-Automation and administrative processes require specialists to set up and maintain.
As best practices, we recommend the following to those building LOB-based Lakehouses:
- Employ a least-privilege access model using fine-grained access control for users and environments; in general, very few users should have production access, and interactions with this environment should be automated and highly controlled. Capture these users and groups in your identity provider and sync them to the Lakehouse.
- Understand and plan for both cloud provider and Databricks platform limits; these include, for example, the number of workspaces, API rate limiting on ADLS, throttling on Kinesis streams, etc.
- Use a standardized metastore/catalog with strong access controls wherever possible; this allows for re-use of assets without compromising isolation. Unity Catalog allows for fine-grained controls over tables and workspace assets, which includes objects such as MLflow experiments.
- Leverage data sharing wherever possible to securely share data between LOBs without needing to duplicate effort.
Data product isolation
What do we do when LOBs need to collaborate cross-functionally, or when a simple dev/stg/prd model does not fit the use cases of our LOB? We can shed some of the formality of a strict LOB-based Lakehouse structure and embrace a slightly more modern approach; we call this workspace isolation by Data Product. The concept is that instead of isolating strictly by LOB, we isolate instead by top-level projects, giving each a production environment. We also mix in shared development environments to avoid workspace proliferation and make reuse of assets simpler.
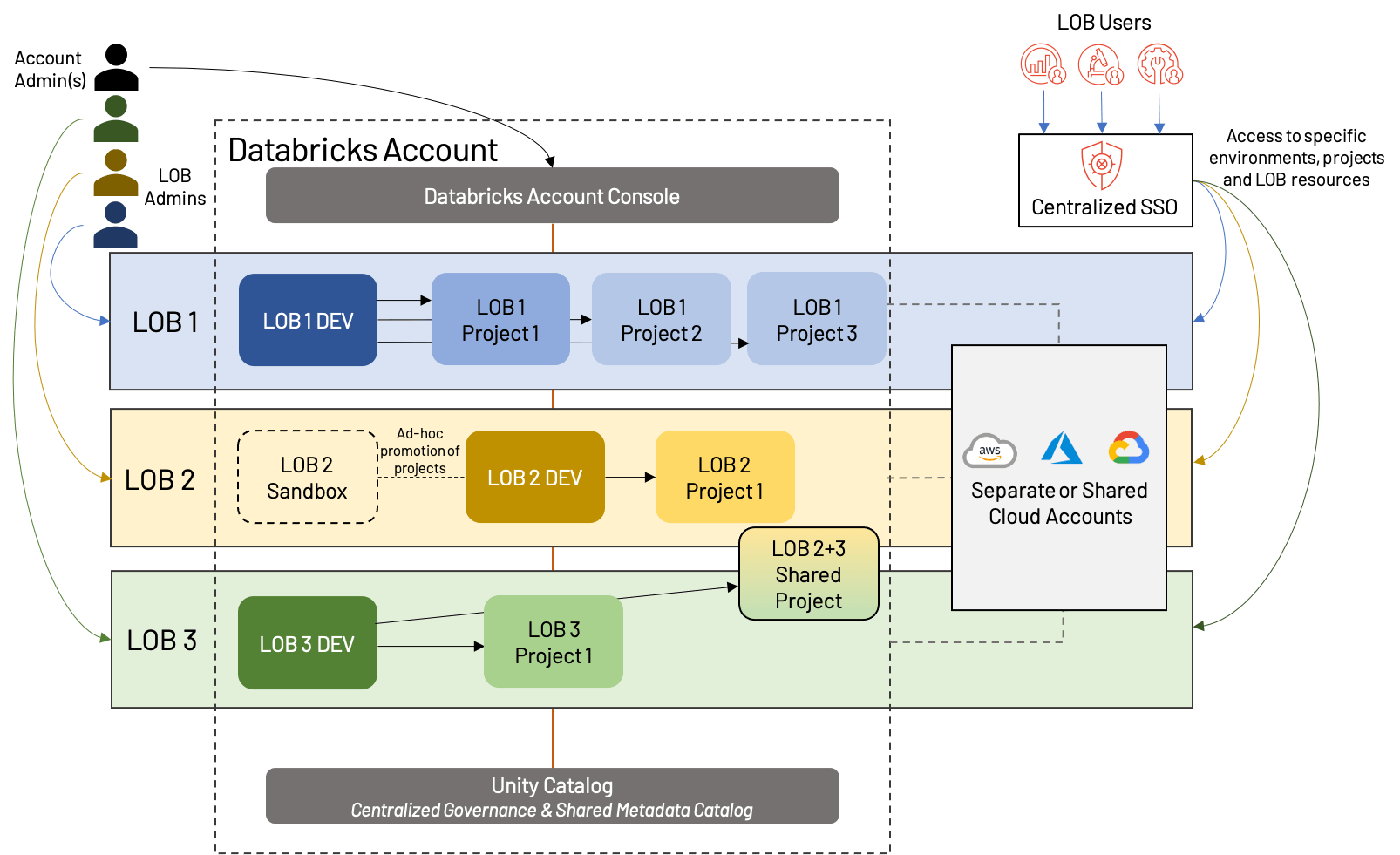
At first glance, this looks similar to the LOB-based isolation from above, but there are a few important distinctions:
- A shared dev workspace, with separate workspaces for each top-level project (which means each LOB may have a different number of workspaces overall)
- The presence of sandbox workspaces, which are specific to an LOB, and offer more freedom and less automation than traditional Dev workspaces
- Sharing of resources and/or workspaces; this is also possible in LOB-based architectures, but is often complicated by more rigid separation
This approach shares many of the same strengths and weaknesses as LOB-based isolation, but offers more flexibility and emphasizes the value of projects in the modern Lakehouse. More and more, we see this becoming the “gold standard” of workspace organization, corresponding with the movement of technology from primarily a cost-driver to a value generator. As always, business needs may drive slight deviations from this sample architecture, such as dedicated dev/stg/prd for particularly large projects, cross-LOB projects, more or less segregation of cloud resources, etc. Regardless of the exact structure, we suggest the following best practices:
- Share data and resources whenever possible; although segregation of infrastructure and workspaces is useful for governance and tracking, proliferation of resources quickly becomes a burden. Careful analysis ahead of time will help to identify areas of re-use.
- Even when not sharing extensively between projects, use a shared metastore such as Unity Catalog, and shared code-bases (via, i.e., Repos) where possible.
- Use Terraform (or similar tools) to automate the process of creating, managing and deleting workspaces and cloud infrastructure.
- Provide flexibility to users via sandbox environments, but ensure that these have appropriate guard rails set up to limit cluster sizes, data access, etc.
Summary
To fully leverage all the benefits of the Lakehouse and support future growth and manageability, care should be taken to plan workspace layout. Other associated artifacts that need to be considered during this design include a centralized model registry, codebase, and catalog to aid collaboration without compromising security. To summarize some of the best practices highlighted throughout this article, our key takeaways are listed below:
Best Practice #1: Minimize the number of top-level accounts (both at the cloud provider and Databricks level) where possible, and create a workspace only when separation is necessary for compliance, isolation, or geographical constraints. When in doubt, keep it simple!
Best Practice #2: Decide on an isolation strategy that will provide you long-term flexibility without undue complexity. Be realistic about your needs and implement strict guidelines before beginning to onramp workloads to your Lakehouse; in other words, measure twice, cut once!
Best Practice #3: Automate your cloud processes. This ranges every aspect of your infrastructure (many of which will be covered in following blogs!), including SSO/SCIM, Infrastructure-as-Code with a tool such as Terraform, CI/CD pipelines and Repos, cloud backup, and monitoring (using both cloud-native and third-party tools).
Best Practice #4: Consider establishing a COE team for central governance of an enterprise-wide strategy, where repeatable aspects of a data and machine learning pipeline is templatized and automated so that different data teams can use self-service capabilities with enough guardrails in place. The COE team is often a lightweight but critical hub for data teams and should view itself as an enabler- maintaining documentation, SOPs, how-tos and FAQs to educate other users.
Best Practice #5: The Lakehouse provides a level of governance that the Data Lake does not; take advantage! Assess your compliance and governance needs as one of the first steps of establishing your Lakehouse, and leverage the features that Databricks provides to make sure risk is minimized. This includes audit log delivery, HIPAA and PCI (where applicable), proper exfiltration controls, use of ACLs and user controls, and regular review of all of the above.
We’ll be providing more Admin best practice blogs in the near future, on topics from Data Governance to User Management. In the meantime, reach out to your Databricks account team with questions on workspace management, or if you’d like to learn more about best practices on the Databricks Lakehouse Platform!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.