Cross-version Testing in MLflow
by Harutaka Kawamura, Corey Zumar and Ben Wilson
MLflow is an open source platform that was developed to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry. It integrates with many popular ML libraries such as scikit-learn, XGBoost, TensorFlow, and PyTorch to support a broad range of use cases. Databricks offers a diverse computing environment with a wide range of pre-installed libraries, including MLflow, that allow customers to develop models without having to worry about dependency management. For example, the table below shows which XGBoost version is pre-installed in different Databricks Runtime for Machine Learning (MLR) environments:
|
MLR version |
Pre-installed XGBoost version |
|---|---|
|
10.3 |
1.5.1 |
|
10.2 |
1.5.0 |
|
10.1 |
1.4.2 |
As we can see, different MLR environments provide different library versions. Additionally, users often want to upgrade libraries to try new features. This range of versions poses a significant compatibility challenge and requires a comprehensive testing strategy. Testing MLflow only against one specific version (for instance, only the latest version) is insufficient; we need to test MLflow against a range of ML library versions that users commonly leverage. Another challenge is that ML libraries are constantly evolving and releasing new versions which may contain breaking changes that are incompatible with the integrations MLflow provides (for instance, removal of an API that MLflow relies on for model serialization). We want to detect such breaking changes as early as possible, ideally even before they are shipped in a new version release. To address these challenges, we have implemented cross-version testing.
What is cross-version testing?
Cross-version testing is a testing strategy we implemented to ensure that MLflow is compatible with many versions of widely-used ML libraries (e.g. scikit-learn 1.0 and TensorFlow 2.6.3).
Testing structure
We implemented cross-version testing using GitHub Actions that trigger automatically each day, as well as when a relevant pull request is filed. A test workflow automatically identifies a matrix of versions to test for each of MLflow's library integrations, creating a separate job for each one. Each of these jobs runs a collection of tests that are relevant to the ML library.
Configuration File
We configure cross-version testing as code using a YAML file that looks like below.
One of the outcomes of cross-version testing is that MLflow can clearly document which ML library versions it supports and warn users when an installed library version is unsupported. For example, the documentation for the mlflow.sklearn.autolog API provides a range of compatible scikit-learn versions:

Refer to this documentation of the mlflow.sklearn.autolog API for further reading.
Next, let's take a look at how the unsupported version warning feature works. In the Python script below, we patch sklearn.__version__ with 0.20.2, which is older than the minimum supported version 0.20.3 to demonstrate the feature, and then call mlflow.sklearn.autolog
The script above prints out the following message to warn the user that the unsupported version of scikit-learn (0.20.2) is being used and autologging may not work properly:
Running tests
Now that we have a testing structure, let's run the tests. To start, we created a GitHub Actions workflow that constructs a testing matrix from the configuration file and runs each item in the matrix as a separate job in parallel. An example of the GitHub Actions workflow summary for scikit-learn cross-version testing is shown below. Based on the configuration, we have a minimum version "0.20.3", which is shown at the top. We populate all versions that exist between that minimum version and the maximum version "1.0.2". At the bottom, you can see the addition of one final test: the "dev" version, which represents a prerelease version of scikit-learn installed from the main development branch in scikit-learn/scikit-learn via the command specified in the install_dev field. We'll explain the aim of this prerelease version testing in the "Testing the future" section later.
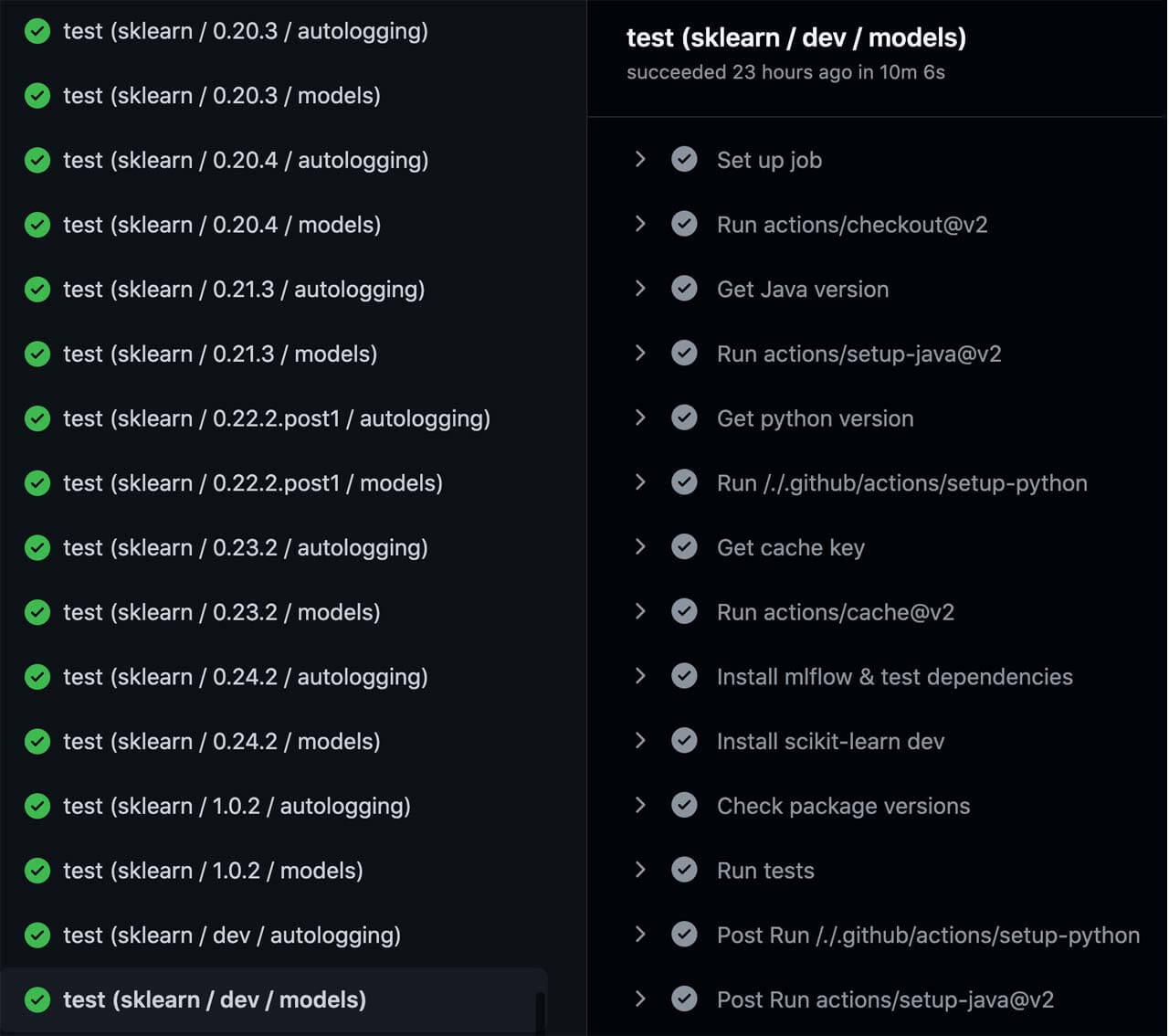
Which versions to test
To limit the number of GitHub Actions runs, we only test the latest micro version in each minor version. For instance, if "1.0.0", "1.0.1", and "1.0.2" are available, we only test "1.0.2". The reasoning behind this approach is that most people don't explicitly install an old minor version of a major release, and the latest minor version of a major version is typically the most bug-free. The table below shows which versions we test for scikit-learn.
|
scikit-learn version |
Tested |
|---|---|
|
0.20.3 |
✅ |
|
0.20.4 |
✅ |
|
0.21.0 |
|
|
0.21.1 |
|
|
0.21.2 |
|
|
0.21.3 |
✅ |
|
0.22 |
|
|
0.22.1 |
|
|
0.22.2 |
|
|
0.22.2.post1 |
✅ |
|
0.23.0 |
|
|
0.23.1 |
|
|
0.23.2 |
✅ |
|
0.24.0 |
|
|
0.24.1 |
|
|
0.24.2 |
✅ |
|
1.0 |
|
|
1.0.1 |
|
|
1.0.2 |
✅ |
|
dev |
✅ |
When to trigger cross-version testing
There are two events that trigger cross-version testing:
- When a relevant pull request is filed. For instance, if we file a PR that updates files under the mlflow/sklearn directory, the cross-version testing workflow triggers jobs for scikit-learn to guarantee that code changes in the PR are compatible with all supported scikit-learn versions.
- A daily cron job where we run all cross-version testing jobs including ones for prerelease versions. We check the status of this cron job every working day to catch issues as early as possible.
Testing the future
In cross-version testing, we run daily tests against both publicly available versions and prerelease versions installed from on the main development branch for all dependent libraries that are used by MLflow. This allows us to predict what will happen to MLflow in the future.
Let's take a look at a real situation that the MLflow maintainers recently handled:
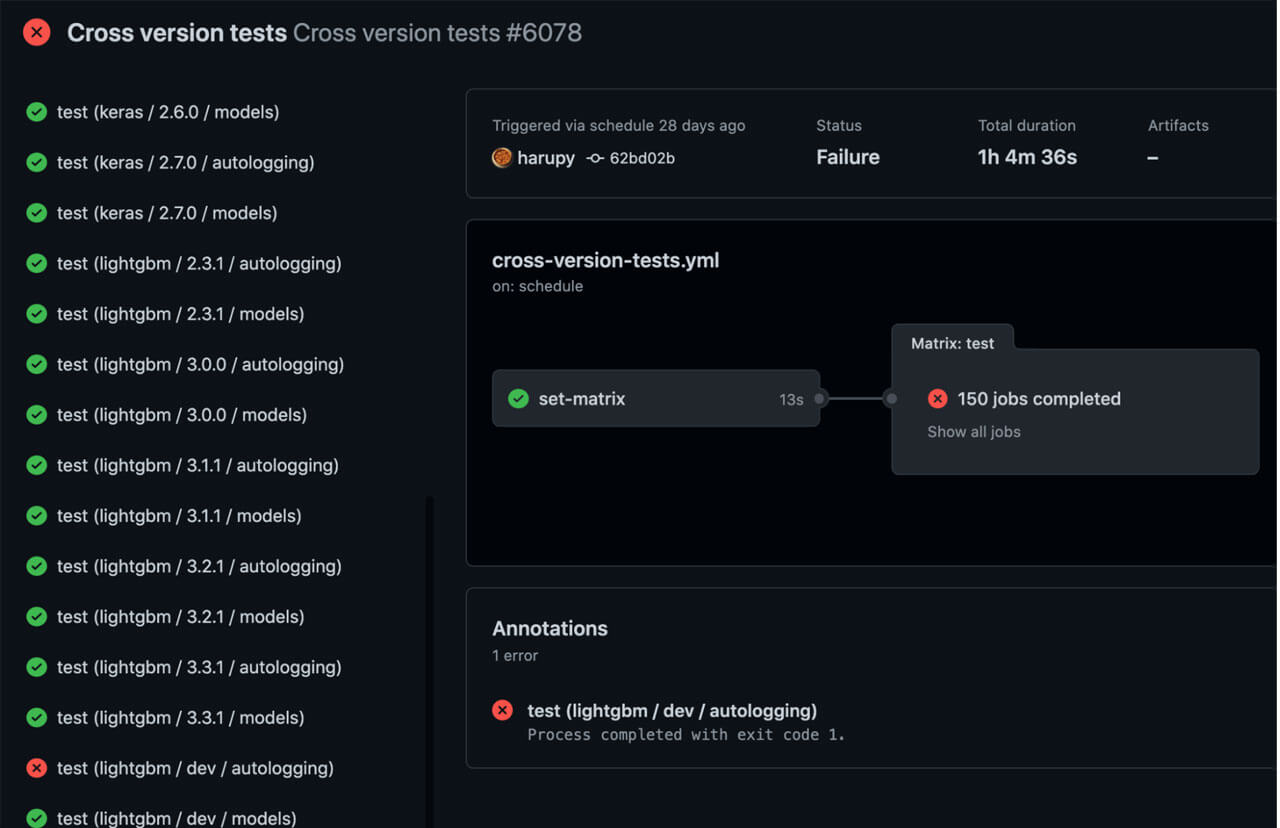
- On 2021/12/26, LightGBM removed several deprecated function arguments in microsoft/LightGBM#4908. This change broke MLflow's autologging integration for LightGBM.
- On 2021/12/27, we found one of cross-version test runs for LightGBM failed and identified microsoft/LightGBM#4908 as the root cause.
- On 2021/12/28, we filed a PR to fix this issue: mlflow/mlflow#5206
- On 2021/12/31, we merged the PR.
- On 2022/01/08, LightGBM 3.3.2 was released, containing the breaking change.
Thanks to prerelease version testing, we were able to discover the breaking change the day after, it was merged and quickly apply a patch for it even before the LightGBM 3.3.2 release. This proactive work, handled ahead of time and on a less-urgent schedule, allowed us to be prepared for their new release and avoid breaking changes or regressions.
If we didn't perform prerelease version testing, we would have only discovered the breaking change after the LightGBM 3.3.2 release, which could have resulted in a broken user experience depending on the LightGBM release date. For example, consider the problematic scenario below where LightGBM was released after MLflow without prerelease version testing. Users running LightGBM 3.3.2 and MLflow 1.23.0 would have encountered bugs.
Conclusion
In this blog post, we covered:
- Why we implemented cross-version testing.
- How we configure and run cross-version testing.
- How we enhance the MLflow user experience and documentation using the cross-version testing outcomes.
Check out this README file for further reading on the implementation of cross-version testing. We hope this blog post will help other open-source projects that provide integrations for many ML libraries.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.