How Uplift built CDC and Multiplexing data pipelines with Databricks Delta Live Tables
by Cody Austin Davis, Ruchira Ramani and Joydeep Datta Gupta
This blog has been co-developed and co-authored by Ruchira and Joydeep from Uplift, we’d like to thank them for their contributions and thought leadership on adopting the Databricks Lakehouse Platform.
Uplift is the leading Buy Now, Pay Later solution that empowers people to get more out of life, one thoughtful purchase at a time. Uplift's flexible payment option gives shoppers a simple, surprise-free way to buy now, live now, and pay over time.
Uplift’s solution is integrated into the purchase flow of more than 200 merchant partners, with the highest levels of security, privacy and data management. This ensures that customers enjoy frictionless shopping across online, call center and in-person experiences. This massive partner ecosystem creates challenges for their engineering team in both data engineering and analytics. As the company scales exponentially with data being its primary value driver, Uplift requires an extremely scalable solution that minimizes the amount of infrastructure and “janitor code” that it needs to manage.
With hundreds of partners and data sources, Uplift leverages their core data pipeline from its integrations to drive insights and operations such as:
- Funnel metrics - application rates, approval rates, take-up rates, conversion rates, transaction volume.
- User metrics - repeat user rates, total active users, new users, churn rates, cross-channel shopping.
- Partner reporting - funnel and revenue metrics at partner level.
- Funding - eligibility criteria, metrics, and monitoring for financed assets.
- Payments - authorization approval rates, retry success rates.
- Lending - roll rates, delinquency monitoring, recoveries, credit/fraud approval funnels.
- Customer support - call center statistics, queue monitoring, payment portal activity funnel.
To achieve this, Uplift leveraged the Databricks Lakehouse Platform to construct a robust data integration system that easily ingests and orchestrates hundreds of topics from Kafka and S3 object storage. While each data source is stored separately, new sources are discovered and ingested automatically from the application engineering teams (data producers), and data evolves independently for each data source to be made available to the downstream analytics team.
Prior to standardizing on the lakehouse platform, adding new data sources and communicating changes across teams was manual, error-prone, and time-consuming since each new source required a new data pipeline to be written. Using Delta Live Tables, their system has become scalable, automatically reactive to changes, and configurable, thus making time to insight much faster by reducing the number of notebooks (from 100+ to 2 pipelines) to develop, manage and orchestrate.
For this data integration pipeline, Uplift had the following requirements:
- Provide the ability to scalably ingest 100+ topics from Kafka/S3 into the Lakehouse, with Delta Lake being the foundation, and can be utilized by analysts in its raw form in a table format.
- Provide a flexible layer that dynamically creates a table for a new Kafka topic that could arrive at any point. This allows for easy new data discovery and exploration.
- Automatically update schema changes for each topic as data changes from Kafka.
- Provide a downstream layer configurable with explicit table rules such as schema enforcement, data quality expectations, data type mappings, default values, etc. to ensure productized tables are governed properly.
- Ensure that the data pipeline can handle SCD Type 1 updates to all explicitly configured tables.
- Allow for applications downstream to create aggregate summary statistics and trends.
These requirements serve as a fitting use case for a design pattern called “multiplexing”. Multiplexing is used when a set of independent streams all share the same source In this example, we have a Kafka message queue and a series of S3 buckets with 100s of change events with raw data being inserted into a single Delta table that we would like to ingest and parse in parallel.
Note, multiplexing is a complex streaming design pattern that has different trade offs from the typical pattern of creating one-to-one source to target streams. If multiplexing is something you are considering but have not yet implemented, it would be helpful to start here with this getting streaming in production video that covers many best practices around basic streaming, as well as the tradeoffs of implementing this design pattern.
Let’s review two general solutions for this use case that utilize the Medallion Architecture using Delta Lake. This is a foundational framework that underpins both solutions below.
Multiplexing Solutions:
- Spark Structured Streaming on Databricks using one to many streaming using the foreachBatch method. This solution reads the bronze stage table and splits the single stream into multiple tables inside the micro-batch.
- Databricks Delta Live Tables (DLT) is used to create and manage all streams in parallel. This process uses the single input table to dynamically identify all the unique topics in the bronze table and generate independent streams for each without needing to explicitly write code and manage checkpoints for each topic.
*The remainder of this article assumes you have exposure to Spark Structured Streaming and an introduction to Delta Live Tables
In our example here, Delta Live Tables provides a declarative pipeline that allows us to provide a configuration of all table definitions in a highly flexible architecture managed for us. With one data pipeline, DLT can define, stream, and manage 100s of tables in a configurable pipeline without losing table level flexibility. For example, some downstream tables may need to run once per day while others need to be real-time for analytics. All of this can now be managed in one data pipeline.
Before we dive into the Delta Live Tables (DLT) Solution, it is helpful to point out the existing solution design using Spark Structured Streaming on Databricks.
Solution 1: Multiplexing using Delta + Spark Structured Streaming in Databricks
The architecture for this structured streaming design pattern is shown below:
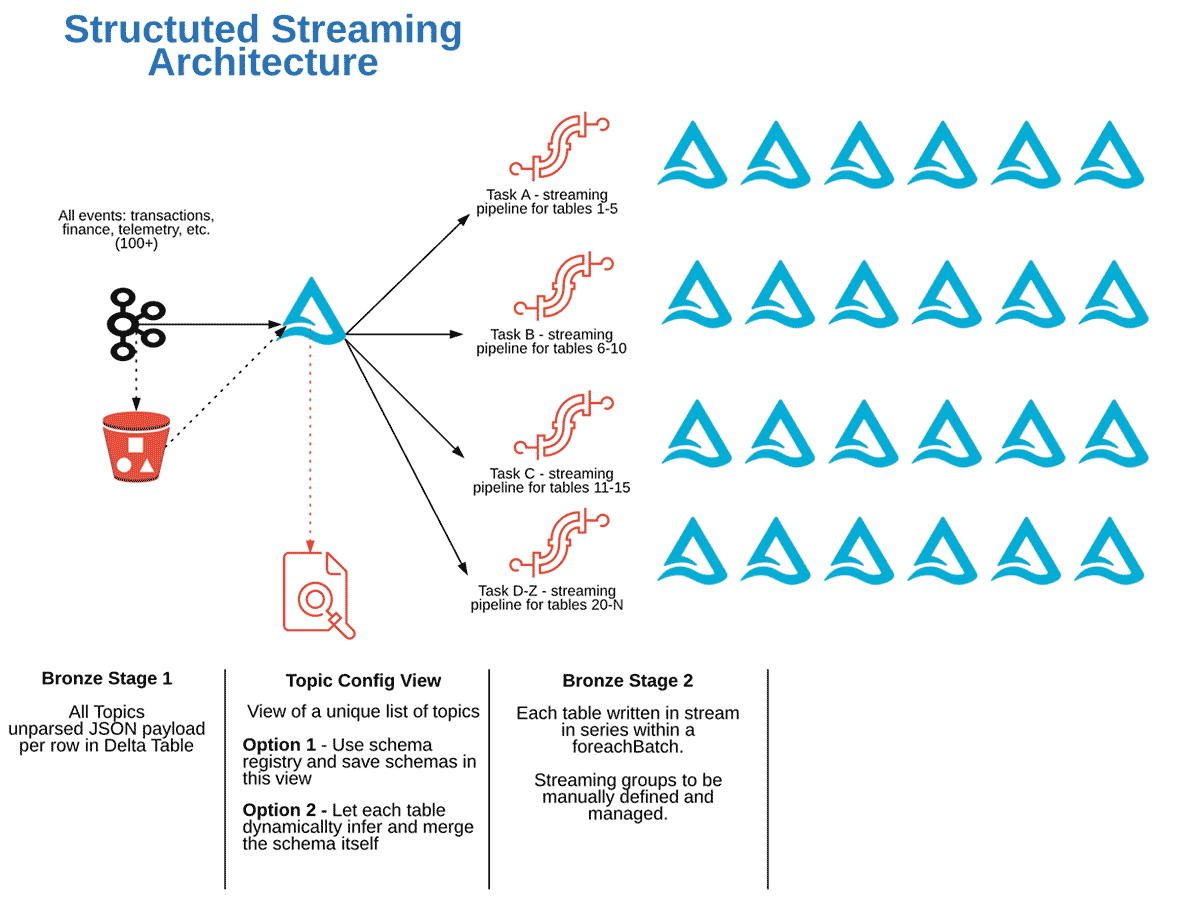
In a Structured Streaming task, a stream will read multiple topics from Kafka, and then parse out tables in one stream to multiple tables within a foreachBatch statement. The code block below serves as an example for writing to multiple tables in a single stream.
There are a few key design consideration notes in the Spark Structured Streaming solution.
To stream one-to-many tables in structured streaming, we need to use a foreachBatch function, and provide the table writes inside that function for each microBatch (see example above). This is a very powerful design, but it has some limitations:
- Scalability: Writing one-to-many tables is easy for a few tables, but not scalable for 100s of tables as this would mean all tables are written in series (since spark code runs in order, each write statement needs to complete before the next starts) by default as shown in the code example above. This will increase the overall job runtime significantly for each table added.
- Complexity: The writes are hardcoded, meaning there is no simple way to automatically discover new topics and create tables moving forward of those new topics. Each time a new data source arrives, a code release is required. This is a significant time sink and makes the pipeline brittle. This is possible, but requires significant development effort.
- Rigidity: Tables may need to be refreshed at different rates, have different quality expectations, and different pre-processing logic such as partitions or data layout needs. This requires the creation of totally separate jobs to refresh different groups of tables.
- Efficiency: These tables can have wildly different data volumes, so if they all use the same streaming cluster, then there will be times where the cluster is not well utilized. Load balancing these streams requires development effort and more creative solutions.
Overall, this solution works well, however, the challenges can be addressed and further the solution further simplified with a single DLT pipeline.
Solution 2: Multiplexing + CDC using Databricks Delta Live Tables in Python
To easily satisfy the requirements above (automatically discovering new tables, parallel stream processing in one job, data quality enforcement, schema evolution by table, and perform CDC upserts at the final stage for all tables), we use the Delta Live Tables meta-programming model in Python to declare and build all tables in parallel for each stage.
The architecture for this solution in Delta Live Tables is as follows:
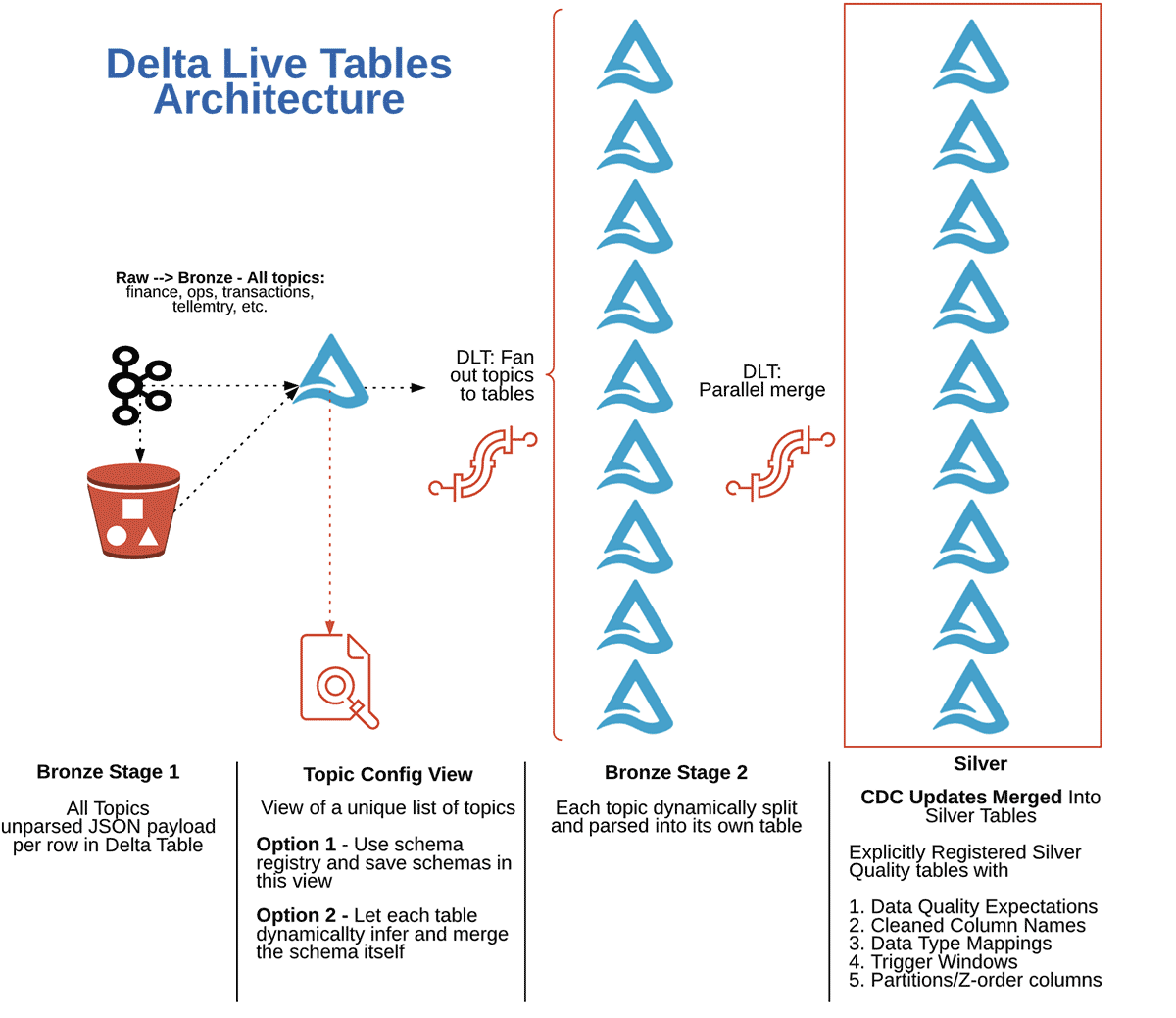
This is accomplished with 1 job made up of 2 tasks:
- Task A: A readStream of raw data from all Kafka topics into Bronze Stage 1 into a single Delta Table. Task A then creates a view of the distinct topics that the stream has seen. (You can optionally use a schema registry to explicitly store and use the schemas of each topic payload to parse in the next task, this view could hold that schema registry or you could use any other schema management system). In this example, we simply dynamically infer all schemas from each JSON payload for each topic, and perform data type conversions downstream at the silver stage.
- Task B: A single Delta Live Tables pipeline that streams from Bronze Stage 1, uses the view generated in the first tasks as a configuration, and then uses the meta programming model to create Bronze Stage 2 tables for every topic currently in the view each time it is triggered.
The same DLT pipeline then reads an explicit configuration (a JSON config in this case) to register “productized” tables with more stringent data quality expectations and data type enforcements. In this stage, the pipeline cleans all Bronze Stage 2 tables, and then implements the APPLY CHANGES INTO method for the productized tables to merge updates into the final Silver Stage.
Finally, Gold Stage aggregates are created from the Silver Stage representing analytics serving tables to be ingested by reports.
Implementation Steps for Multiplexing + CDC in Delta Live Tables
Below are the individual implementation steps for setting up a multiplexing pipeline + CDC in Delta Live Tables:
- Raw to Bronze Stage 1 - Code example reading topics from Kafka and saving to a Bronze Stage 1 Delta Table.
- Create View of Unique Topics/Events - Creation of the View from Bronze Stage 1.
- Fan out Single Bronze Stage 1 to Individual Tables - Bronze Stage 2 code example (meta-programming) from the view.
- Bring Bronze Stage 2 Tables to Silver Stage - Code example demonstrating metaprogramming model from the silver config layer along with silver table management configuration example.
- Create Gold Aggregates - Code example in Delta Live Tables creating complete Gold Summary Tables.
- DLT Pipeline DAG - Test and Run the DLT pipeline from Bronze Stage 1 to Gold.
- DLT Pipeline Configuration - Configure the Delta Live Tables pipeline with any parameters, cluster customization, and other configuration changes needed for implementing in production.
- Multi-task job Creation - Combined step 1 and step 2-7 (all one DLT pipeline) into a Single Databricks Job, where there are 2 tasks that run in series.
Step 1: Raw to Bronze Stage 1 - Code example reading topics from Kafka and saving to a Bronze Stage 1 Delta Table.
Step 2: Create View of Unique Topics/Events
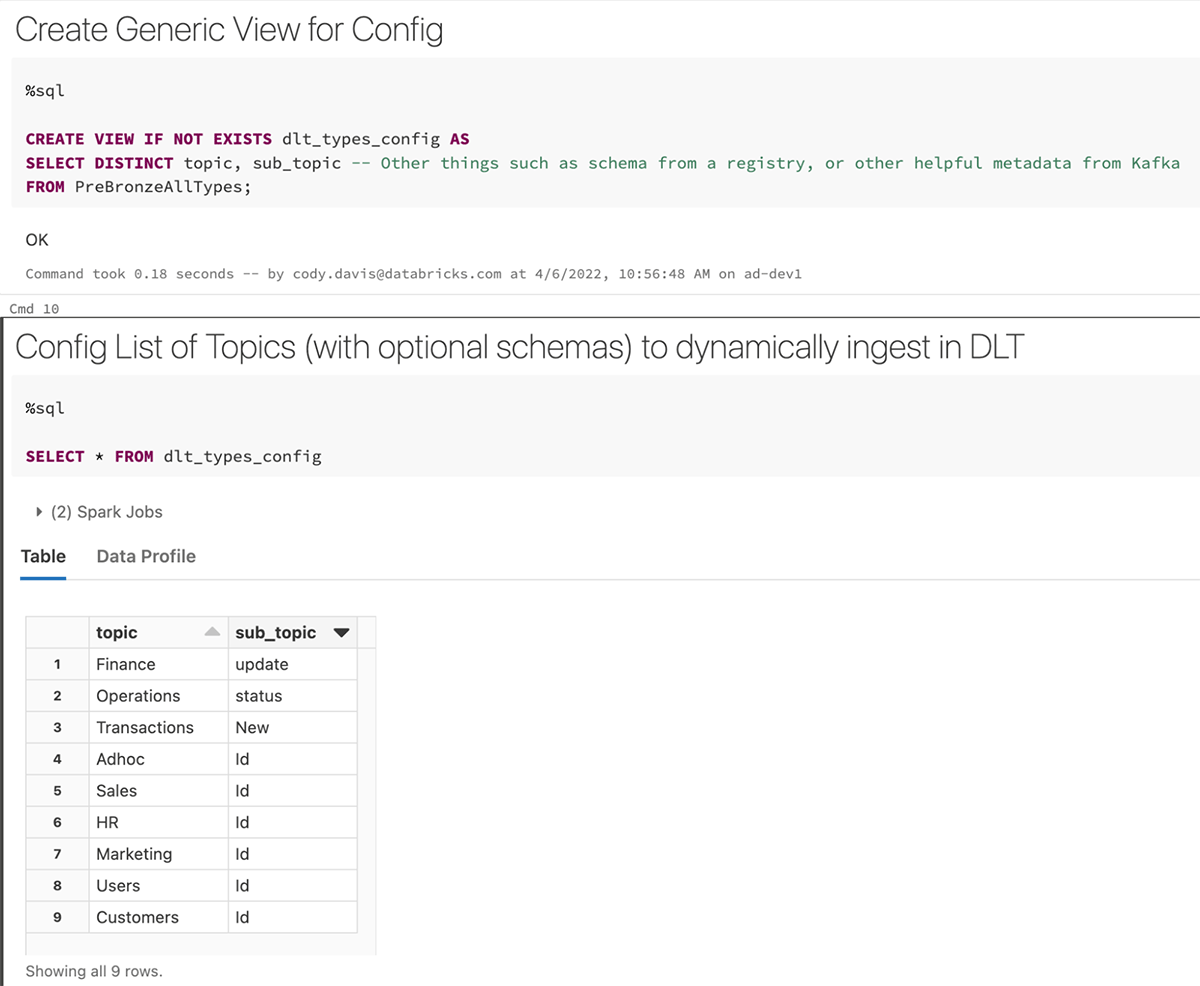
Step 3: Fan out Single Bronze Stage 1 to Individual Tables
Step 4: Bring Bronze Stage 2 Tables to Silver Stage

Define DLT Function to Generate Bronze Stage 2 Transformations and Table Configuration
Define Function to Generate Silver Tables with CDC in Delta Live Tables
Get Silver Table Config and Pass to Merge Function
Step 5: Create Gold Aggregates
Create Gold Aggregation Tables
Step 6: DLT Pipeline DAG - Putting it all together creates the following DLT Pipeline:

Step 7: DLT Pipeline Configuration
In this settings configuration, this is where you can set up pipeline level parameters, cloud configurations like IAM Instance profiles, cluster configurations, and much more. See the following documentation for the full list of DLT configurations available.
Step 8: Multi-task job Creation - Combine DLT Pipeline and Preprocessing Step to 1 Job
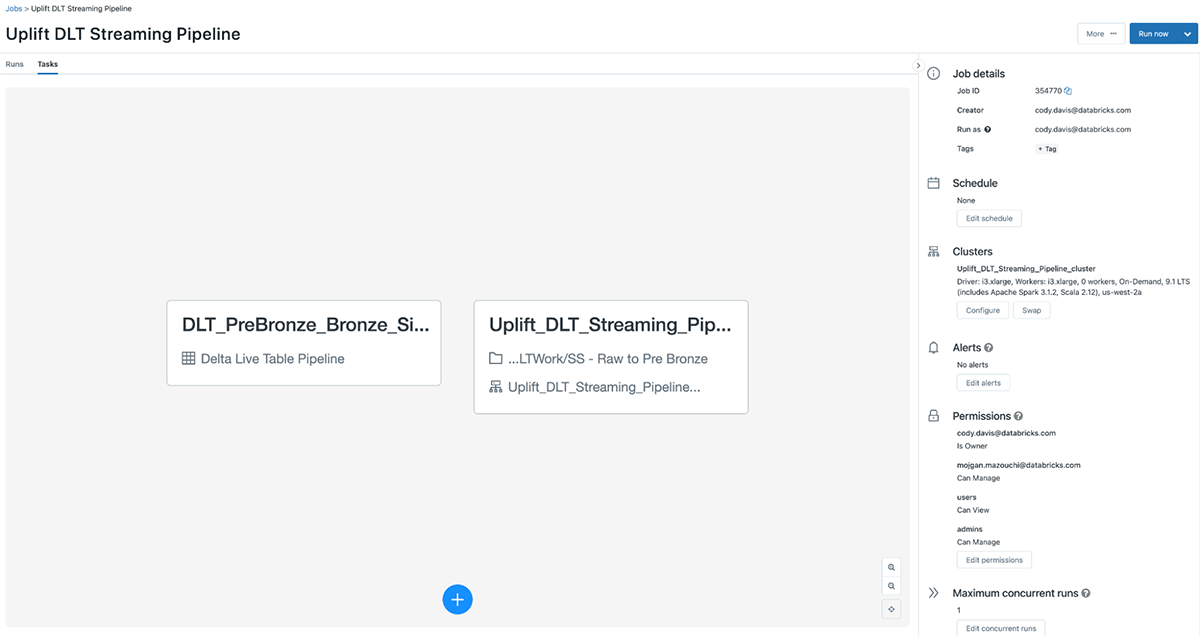
In Delta Live Tables, we can control all aspects of each table independently via the configurations of the tables without changing the pipeline code. This simplifies pipeline changes, vastly increases scalability with advanced auto-scaling, and improves efficiency due to the parallel generation of tables. Lastly, the entire 100+ table pipeline is all supported in one job that abstracts away all streaming infrastructure to a simple configuration, and manages data quality for all supported tables in the pipeline in a simple UI. Before Delta Live Tables, managing the data quality and lineage for a pipeline like this would be manual and extremely time consuming.
This is a great example of how Delta Live Tables simplifies the data engineering experience while allowing data engineers and analysts (You can also create DLT pipelines in all SQL) to build sophisticated pipelines that would have taken hundreds of hours to build and manage in-house.
Ultimately, Delta Live Tables enables Uplift to focus on providing smarter and more effective product offerings for their partners instead of wrangling each data source with thousands of lines of “janitor code”.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.