Announcing General Availability of Databricks Feature Store
The first feature store co-designed with data and MLOps platform
by Maxim Lukiyanov, Matei Zaharia, Mani Parkhe and Ari Paul
Today, we are thrilled to announce that Databricks Feature Store is generally available (GA)! In this blog post, we explore how Databricks Feature Store, the first feature store co-designed with an end-to-end data and MLOps platform, provides data teams with the ability to define, explore and reuse machine learning features, build training data sets, retrieve feature values for batch inference, and publish features to low-latency online stores.
Quick recap: What is a feature?
In machine learning, a feature is an attribute - or measurable characteristic - that is relevant to making a prediction. For example, in a machine learning model trying to predict traffic patterns on a highway, the time of day, day of the week, and throughput of cars can all be considered features. However, real-world data requires a significant amount of preprocessing, wrangling, and transformations to become usable for machine learning applications. For example, you may want to remove highly correlated input data or analyze language prior to feeding that data into your model as a feature. The process of making raw data machine learning-ready is called feature engineering.
The challenges of feature engineering
Feature engineering is complex and time-consuming. As organizations build and iterate on more machine learning models, it becomes increasingly important that already-built features can be discovered, shared, and reused. Good feature-reuse practices can save data teams weeks. But once features are being re-used, it is critical that their real-world performance is tracked closely. Quite often, a feature computation used in training may deviate from the one used in production, which leads to a skew in predictions, resulting in degraded model quality. It’s also critical to establish feature lineage - to track which models are using what features and the data going into these features.
Many of our customers have told us that a good feature development platform can significantly accelerate model development time, eliminate duplicate data pipelines, improve data quality, and help with data governance.
The Databricks Feature Store
The first of its kind, Databricks Feature Store is co-designed with popular open source frameworks Delta Lake and MLflow. Delta Lake serves as an open data layer of the feature store, and MLflow format makes it possible to encapsulate interactions with the feature store in the model package, simplifying deployment and versioning of the models. Building upon these unique differentiators Databricks Feature Store delivers following key benefits:
- Discover and reuse features in your tool of choice: The Databricks Feature Store UI helps data science teams across the organization benefit from each other's work and reduce feature duplication. The feature tables on the Databricks Feature Store are implemented as Delta tables. This open data lakehouse architecture enables organizations to deploy the feature store as a central hub for all features, open and securely accessible by Databricks workspaces and third-party tools.
- Eliminate online/offline skew: By packaging feature information within the MLflow model, Databricks Feature Store automates feature lookups across all phases of the model lifecycle: during the model training, batch and online inference. This ensures that features used in model inference and model training have gone through exactly the same transformations, eliminating common failure modes of real-time model serving.
- Automated lineage tracking: As an integrated component of the unified data and AI platform Databricks Feature Store is uniquely positioned to capture complete lineage graph: starting from data sources of the features, to models and inference end-points consuming them. The lineage graph also includes the versions of the code used at each point. This facilitates powerful lineage-based discovery and governance. Data scientists can find the features that are already being computed for the raw data they are interested in. Data engineers can safely determine whether features can be updated or deleted depending on whether any active model consumes the features.
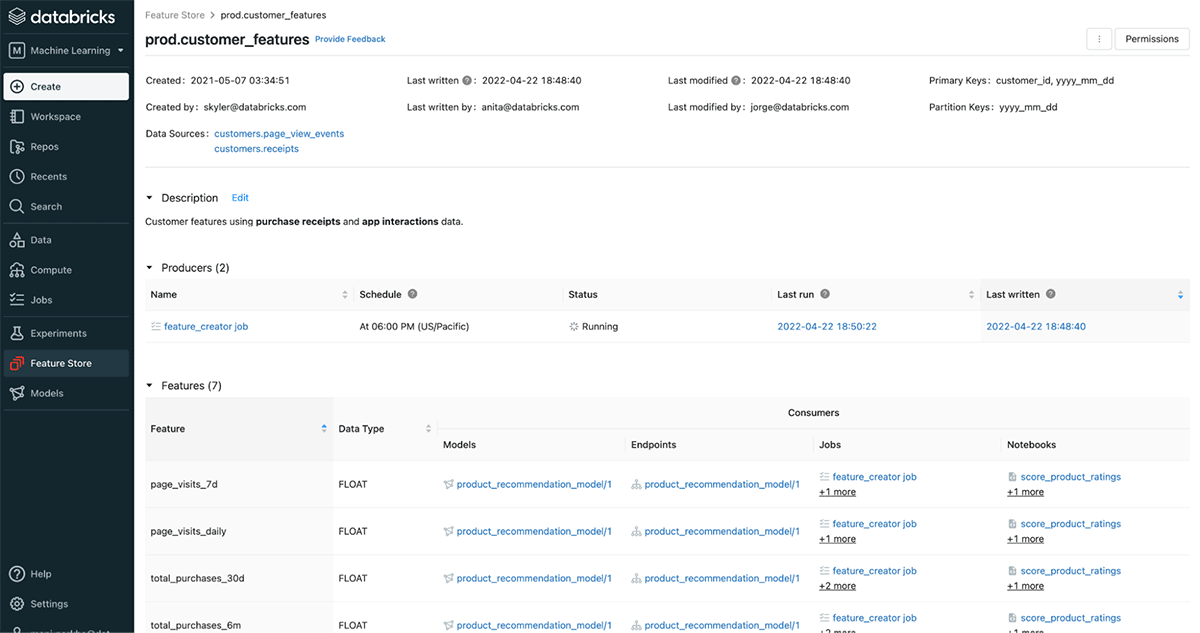
Customers win with feature store on the Lakehouse
Hundreds of customers have already deployed Databricks Feature Store to empower their production Machine Learning processes. For customers such as Via, this resulted in an increase of developer productivity by 30%, and reduction of data processing costs by over 25%.
- Via: “Databricks Feature Store enables us to create a robust and stable environment for creating and reusing features consumed by models. This has enabled our data scientists and analysts to be more productive, as they no longer have to waste time converting data into features from scratch each time.”
— Cezar Steinz, Manager of MLOps at Via - Anheuser-Busch InBev: "The Databricks Feature Store has facilitated our transition from monolithic, opaque machine learning pipelines to nimble, modular pipelines, promoting reusability and transparency of our data assets. It has been instrumental in helping us quickly scale our data science capabilities as well as in uniting data engineers and analysts alike with a common source of feature engineering and data transformations."
— Christopher Stone - Director of Data Engineering at Anheuser-Busch InBev
What’s New?
The GA release also includes a variety of exciting new functionality.
Time-series feature tables and point-in-time joins
One of the most common types of data stored in feature stores is time-series data. It is also the type of data that requires the most careful handling. Slightest misalignment of data points in joins over time dimension results in data leakage from the future of the time-series which erodes model performance in ways that are not always easy to detect. Manually programming joins between features with different sliding time windows requires intense focus and meticulous attention to detail.
Databricks Feature Store removes this burden by providing built-in support for time-series data. Data scientists can simply indicate which column in the feature table is the time dimension and the Feature Store APIs take care of the rest. In model training, the dataset will be constructed using a set of correct AS-OF joins. In batch inference, packaged MLflow models will perform point-in-time lookups. In online serving, the Feature Store will optimize storage by publishing only the most recent values of the time-series and automatically expiring the old values.
Let’s illustrate how easy it is to create a training dataset from time-series feature tables using new Feature Store APIs for a product recommendation model. First, we will create a time-series feature table from PySpark user_features_dataframe with event_time column serving as a time dimension.
Next, we’ll create a training dataset by joining training data from raw_clickstream dataframe with 2 features from the time-series feature table.
The training_dataset contains optimized AS-OF joins that guarantee correct behavior. This is all it takes to create a training dataset with Databricks Feature Store APIs and start training models with any ML framework.
NoSQL online store
(AWS)
In addition to a variety of SQL Databases already supported as online stores for feature serving, Databricks Feature Store now has support for AWS DynamoDB. For publishing time-series feature tables, you can publish to DynamoDB with a time-to-live so that stale features automatically expire from the online store. Support for Azure Cosmos DB is coming soon.
Data pipeline health monitoring
The Feature Store UI monitors the status of the data pipeline that produced the feature table and informs users if it runs stale. This helps prevent outages and provides better insights to data scientists about the quality of the features they find in the feature store.

Learn more about the Databricks Feature Store
Get more familiar with feature stores with this ebook: The Comprehensive Guide to Feature Stores
Take it for a spin! Check out the Databricks Machine Learning free trial on your cloud of choice to get your hands on the Feature Store
Dive deeper into the Databricks Feature Store documentation
Check out this awesome use-case with our customer Via and the tech lead on the Feature Store: All About Feature Stores
Credits
We'd like to acknowledge the contributions of several people that helped in the journey from ideation to GA: Clemens Mewald, Paul Ogilvie, Avesh Singh, Aakrati Talati, Traun Leyden, Zhidong Qu, Nina Hu, Coco Ouyang, Justin Wei, Divya Gupta, Carol Sun, Tyler Townley, Andrea Kress. We would also like to thank Xing Chen and Patrick Wendell for their support in this journey.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.