How illimity Bank Built a Disaster Recovery Strategy on the Lakehouse
by Andrea Gojakovic, Mattia Zeni and Serge Smertin
This is a guest post from Andrea Gojakovic, Team Leader for Data Science & Modelling at illimity.
The rising complexity of financial activities, the widespread use of information and communications technology, and new risk scenarios all necessitate increased effort by Financial Services Industry (FSI) players to ensure appropriate levels of business continuity.
Organizations in the financial services industry face unique challenges when developing Disaster Recovery (DR) and business continuity plans and strategies. Recovering from a natural disaster or another catastrophic event quickly is crucial for these organizations, as lost uptime could mean loss of profit, reputation, and customer confidence.
illimity Bank is Italy’s first cloud-native bank. Through its neprix platform, illimity provides loans to high-potential enterprises and buys and manages corporate distressed credit. Its direct digital bank, illimitybank.com, provides revolutionary digital direct banking services to individual and corporate customers. With Asset Management Companies (AMC) illimity also creates and administers Alternative Investment Funds.
illimity’s data platform is centered around Azure Databricks, and its functionalities. This blog describes the way we developed our data platform DR scenario, guaranteeing RTOs and RPOs required by the regulatory body at illimity and Banca d’Italia (Italy’s central bank).
The design and implementation of the solution were supported by Data Reply IT, Databricks Premier Partner, which put in place a fast and effective implementation of the Disaster Recovery requirements in the illimity Databricks Lakehouse Platform.
Regulatory requirements on Disaster Recovery
Developing a data platform DR strategy, which is a subset of Business Continuity (BC) planning, is complex, as numerous factors must be considered. The planning begins with a Business Impact Analysis (BIA), which defines two key metrics for each process, application, or data product:
- Recovery Time Objective (RTO) defines the maximum acceptable time that the application can be offline. Banca d’Italia further defines it as the interval between the operator’s declaration of the state of crisis and the recovery of the process to a predetermined level of service. It also considers the time needed to analyze the events that occurred and decide on the actions that need to be taken.
- Recovery Point Objective (RPO) defines the maximum acceptable length of time during which data might be lost due to a disaster.
These metrics vary and change depending on how critical the process is to the business and definitions provided by regulatory bodies.
In this blog post we will cover the business processes deemed as “business critical” (i.e., having an RTO and RPO of 4 hours1).
Architecture
illimity started its journey on Databricks from scratch in 2018 with a single Workspace. Since then, Databricks has become the central data platform that houses all types of data workloads: batch, streaming, BI, user exploration and analysis.
Instead of opting for a traditional data warehousing solution like many traditional banks, we decided to fully adopt the Lakehouse by leveraging Delta Lake as the main format for our data (99% of all data in illimity are Delta Tables) and serve it with Databricks SQL. Data ingestion and transformation jobs are scheduled and orchestrated through Azure Data Factory (ADF) and Databricks Jobs. Our NoSQL data is hosted on MongoDB, while we’ve chosen Azure’s native business intelligence solution, PowerBI, for our dashboarding and reporting needs. In order to correctly track, label and guarantee correct data access, we integrated Azure Purview and Immuta into our architecture.
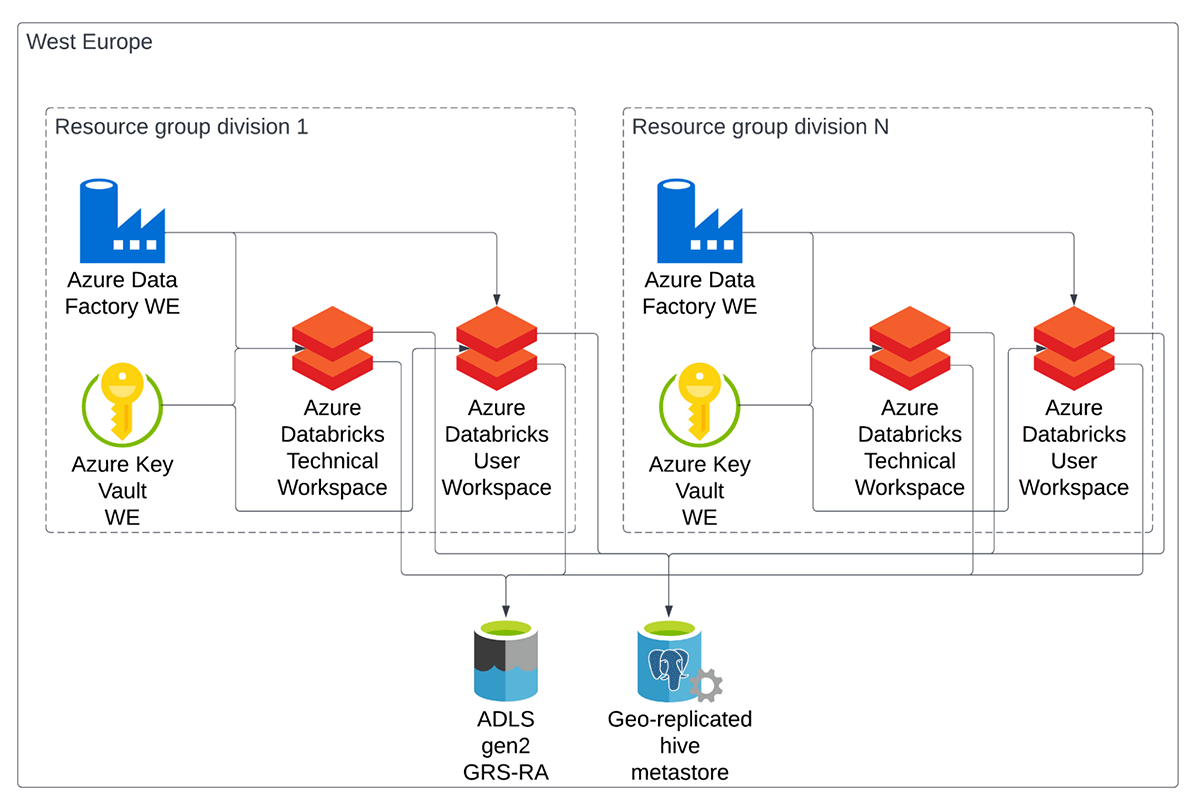
Figure below shows how the Databricks part of our architecture is organized. We set up two types of workspaces, technical and user workspaces, grouped inside an Azure resource group.
Each of the nine divisions of the bank has a dedicated technical workspace in a non-production and production environment where the division’s developers are both owners and administrators. All automated jobs will be executed in the technical workspaces, and business users don’t normally operate in them. A user workspace allows access to the business users of the division. This is where exploration and analysis activities happen.
Both types of workspaces are connected to the same, shared, Azure Data Lake Gen 2 (ADLS) and Azure Database for PostgreSQL, for data and metadata, respectively. These two are a single instance shared across all the divisions of the bank.
Databricks deployment automation with Terraform
Before deciding to manage all Databricks resources as Infrastructure as Code (IaC) through Terraform, all the changes to these objects were done manually. This resulted in error-prone manual changes to both the non-production and production environment. Prior to decentralizing the architecture and moving towards a data mesh operative model, the entire data infrastructure of the bank was managed by a single team, causing bottlenecks and long resolution times for internal tickets. We have since created Terraform and Azure Pipeline templates for each team to use, allowing for independence while still guaranteeing compliance.
Here are some of the practical changes that have occurred since adopting Terraform as our de-facto data resource management tool:
- Clusters and libraries installed on them were created and maintained manually, resulting in runtime mismatches between environments, non-optimized cluster sizes and outdated library versions. Terraform allows teams to manage their Databricks Runtimes as needed in different environments, while all libraries are now stored as Azure Artifacts, avoiding stale package versions. When creating clusters with Terraform, a double approval is needed on the Azure Pipeline that creates these resources in order to avoid human error, oversizing and unnecessary costs. Obligatory tagging on all clusters lets us allocate single project costs correctly and lets us calculate the return on equity (ROE) for each cluster.
- Users and permissions on databases and clusters were added to Databricks manually. The created groups did not match those present in Azure Active Directory and defining the data the users could access for auditing purposes was almost impossible. User provisioning is now managed through SCIM and all ACLs are managed through Terraform, saving our team hours of time every week on granting these permissions.
In the beginning of the project, we used Experimental Resource Exporter and generated code for almost everything we had manually configured in the workspace: cluster and job configurations, mounts, groups, permissions. We had to manually rewrite some of that code, though it tremendously saved us the initial effort.
Although Terraform has a steep learning curve and a notable investment had to be made to refactor existing processes, we started reaping the benefits in very little time. Apart from managing our DR strategy, an IaC approach saves data teams at illimity numerous hours of admin work, leaving more time for impactful projects that create value.
Adopting a disaster recovery strategy
When deciding how to approach DR, there are different strategies to choose from. Due to the strong RPO and RTO requirements of financial institutions, at illimity, we decided to adopt an Active/Passive Warm Standby approach, that maintains live data stores and databases, in addition to a minimum live deployment. The DR site must be scaled up to handle all production workloads in case of a disaster. This allows us to react faster to a disaster while keeping costs under control.
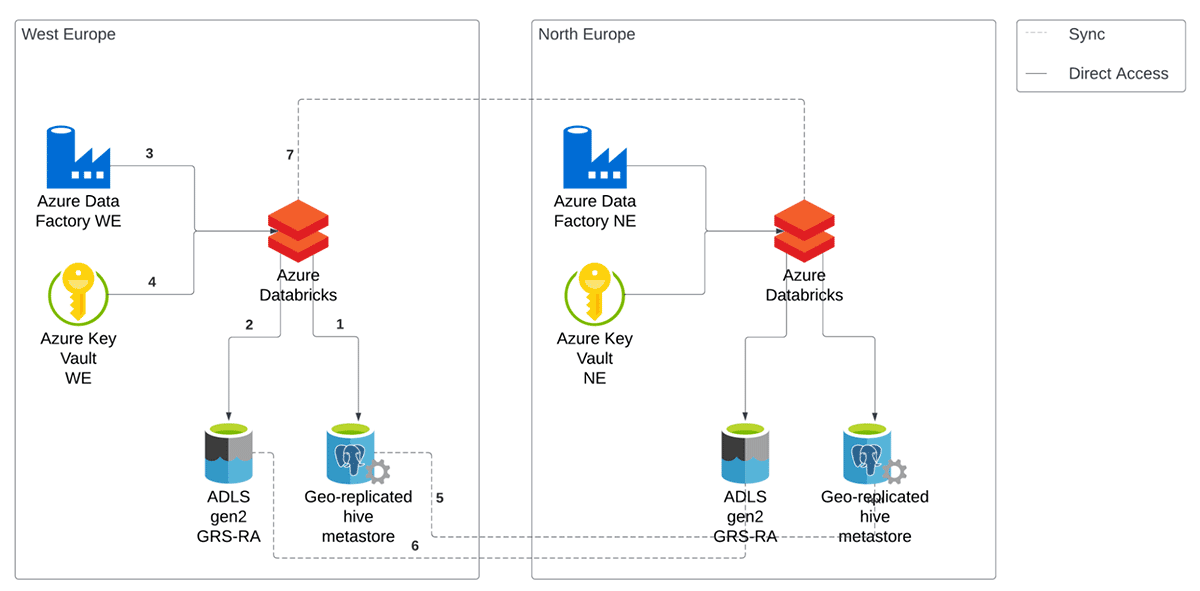
Our current setup for DR can be seen in Figure below. This is a simplified view considering only one workspace in one division, but the following considerations can be easily generalized. We replicate our entire cloud computing infrastructure in two Azure regions. Each component is deployed in both regions at all times, but the compute resources of the secondary region are turned off until a disaster event occurs. This allows us to react within minutes.
In this blog post, we will focus only on the Databricks part of the DR strategy. This includes the workspace, Azure Database for PostgreSQL and Azure Data Lake Storage Gen2.
Databricks objects
Inside a Databricks workspace, there are multiple objects that need to be restored in the new region in the event of a disaster. At illimity, we achieve this by leveraging Terraform to deploy our environments. The objects in a workspace, (i.e., clusters, users and groups, jobs, mount points, permissions and secrets) are managed via Terraform scripts. When we deploy a new workspace or update an existing one, we make sure to deploy in both regions. In this way, the secondary region is always up to date and ready to start processing requests in case of a disaster event. For automated jobs, nothing needs to be done since the triggering of a job operation automatically starts a Jobs cluster. For users workspaces, one of the available clusters is started whenever a user needs to execute an operation on the data.
Tables replication
When it comes to tables, in Databricks there are two main objects that need to be backed up: data in the storage account and metadata in the metastore. There are multiple options when choosing a DR strategy. In illimity, we decided to opt for a passive backup solution instead of setting up manual processes to keep them in sync, that is, leverage on the low-level replication capabilities made available by the cloud provider, Azure.
Data replication
Delta Lake provides ACID transactions, which adds reliability to every operation, and Time Travel. The latter is specifically important. Time Travel allows us to easily recover from errors and is fundamental for our disaster recovery.
As the main storage for Delta files, we opted for a GRS-RA Azure Data Lake Storage Gen2. This choice allows us to approach DR in a passive manner, in the sense that the replication to a secondary region is delegated to Azure. In fact, a Geo-redundant Read Access storage (GRS-RA) copies the data synchronously three times within a physical location in the primary region using LRS (Locally-redundant storage). Additionally, it copies the data asynchronously to a physical location in the secondary region. GRS offers durability for storage resources of at least sixteen 9's over a given year. In terms of RPO, Azure Storage has an RPO of less than 15 minutes, although there's currently no SLA on how long it takes to replicate data to the secondary region.
Due to this delay in the replication across regions, we need to make sure that all the files belonging to a specific version of the Delta table are present to not end up with a corrupted table. To address this, we created a script that is executed in the secondary region when a disaster event and outage occurs, that checks if the state of all the tables is consistent, the fact that all files of a specific version are present. If the consistency requirement is not met, the script restores the previous version of the table using Delta-native Time Travel, which is guaranteed to be within the specified RPO.
Metastore replication
The second component needed when working with Delta tables is a metastore. It allows users to register tables and manage Table ACL. At illimity, we opted for an external Hive Metastore over the managed internal Hive Metastore, mainly for its ability to replicate itself in a different region, without implementing a manual strategy. This is in line with opting for a passive DR solution. The metastore consists of a fully managed Geo-replicated Azure Database for PostgreSQL. When we modify the metadata from any workspace in the Primary region, it gets automatically propagated to the Secondary region. In case of an outage, the workspaces in our Secondary region always have the latest metadata that allows for a consistent view on tables, permissions, etc. Unity Catalog will soon be the standard internal metastore for Databricks and will provide additional functionalities, such as cross-workspace access, centralized governance, lineage, etc., that will simplify replicating the metastore for DR.
Modifying a Databricks Workspace at illimity
At illimity, we decided to have a strict policy in terms of Databricks workspaces creation and modification. Each workspace can be edited exclusively via Terraform and changes via the web UI are completely forbidden. This is achieved natively, since the UI does not allow modifying clusters created via Terraform. Moreover, only a few selected users are allowed to be admins within a workspace. This allows us to have compliant templates across our organization, and accountable division admins who carry out the changes.
Each division of illimity defines a process of applying changes to the state of the Databricks workspace through the use of Azure DevOps (ADO) pipelines. The ADO pipelines take care of doing the Terraform plan and apply steps, which are equivalent to the actual operations of creating, updating or removing resources, as defined within the versioned configuration code in the Git repositories.
Each ADO pipeline is responsible for carrying out the Terraform apply step against both the Primary and Secondary regions. In this way, the definition of workspace declared by the division will be replicated in a perfectly equivalent way in the different regions, ensuring total alignment and disaster recovery readiness.
The development process for the maintenance and update of the various Databricks workspaces, using Azure DevOps, is governed by the following guidelines
- The master branch of each repository will maintain the Terraform configurations of both environments (UAT and PROD), which will define the current (and officially approved) state of the different resources. The possibility to make direct commits is disabled on that branch. An approval process via pull request is always required.
- Any change to the resources in the various environments must go through a change to their Terraform code. Any new feature (e.g. library to be installed on the cluster, new Databricks cluster, etc.), which changes the state of the UAT or PROD environment, must be developed on a child branch of the master branch.
- Only for changes to the production environment, the user will also have to open a Change Request (CHR) that will require Change-advisory board (CAB) approval, without which it will not be possible to make changes to production resources. The pull request will require confirmation from designated approvers within their division.
- Granted approval, the code will be merged within the master branch and at that point, it will be possible to start the Azure DevOps pipeline, responsible for executing the Terraform apply to propagate the changes both in the Primary region and in the Secondary region.
- For production environment changes only, the actual Azure DevOps Terraform apply step will be tied to the check of the presence of an approved change request.
This approach greatly facilitates our DR strategy, because we are always sure that both environments are exactly the same, in terms of Databricks Workspaces and the objects inside them.
How to test your DR Strategy on Azure
In illimity, we have created a step-by-step runbook for each team, which describes in detail all the necessary actions to guarantee the defined RTO and RPO times in case of a disaster. These runbooks are executed by the person on call when the disaster happens.
To validate the infrastructure, procedure and runbooks, we needed a way to simulate a disaster in one of Azure’s regions. Azure allows its clients to trigger a customer-initiated failover. Customers have to submit a request which effectively makes the primary region unavailable, thus failing over to the secondary region automatically.
Get started
Guaranteeing business continuity must be a priority for every company, not only for those in the Financial Services Industry. Having a proper disaster recovery strategy and being able to recover from a disaster event quickly is not only mandatory in many jurisdictions and industries, but it is also is business critical since downtime can lead to loss of profit, reputation and customer confidence.
illimity Bank fully adopted the Databricks Lakehouse Platform as the central data platform of the company, leveraging all the advantages with respect to traditional data warehouses or data lakes, and was able to implement an effective and automated DR solution as presented in this blog post. The assessment presented here should be considered as a starting point to implement an appropriate DR strategy in your company on the Lakehouse.
1Guidelines on business continuity for market infrastructures: Section 3, article 2.5
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.