Getting Started with Personalization through Propensity Scoring
by Tian Tan, Sam Steiny and Bryan Smith

Consumers increasingly expect to be engaged in a personalized manner. Whether it's an email message promoting products to complement a recent purchase, an online banner announcing a sale on products in a frequently browsed category, or content aligned with expressed interests, consumers have an increasing number of choices for where they spend their money and prefer to do so with outlets that recognize their personal needs and preferences.
A recent survey by McKinsey highlights that nearly three-quarters of consumers now expect personalized interactions as part of their shopping experience. The research included with this survey highlights that companies that get this right stand to generate 40% more revenue through personalized engagements, making personalization a key differentiator for top retail performers.
Still, many retailers struggle with personalization. A recent survey by Forrester finds only 30% of US and 26% of UK consumers believe retailers do a good job of creating relevant experiences for them. In a separate survey by 3radical, only 18% of respondents felt strongly that they received customized recommendations, while 52% expressed frustration from receiving irrelevant communications and offers. With consumers increasingly empowered to switch brands and outlets, getting personalization right has become a priority for an increasing number of businesses.
Personalization is a journey
To an organization new to personalization, the idea of delivering one-to-one engagements seems daunting. How do we overcome siloed processes, poor data stewardship and concerns over data privacy to assemble the data needed for this approach? How do we craft content and messaging that feels truly personalized with only limited marketing resources? How do we ensure the content we create is effectively targeted to individuals with evolving needs and preferences?
While much of the literature on personalization highlights cutting edge approaches that stand out for their novelty (but not always their effectiveness), the reality is that personalization is a journey. In the early phases, emphasis is placed on leveraging first-party data where privacy and customer trust are more easily maintained. Fairly standard predictive techniques are applied to bring proven capabilities forward. As value is demonstrated and the organization develops not only comfort with these new techniques but also the various ways they can be integrated into their practices, more sophisticated approaches are then employed.
Propensity scoring Is often a first step towards personalization
One of the first steps in the personalization journey is often the examination of sales data for insights into individual customer preferences. In a process referred to as propensity scoring, companies can estimate customers' potential receptiveness to an offer or to content related to a subset of products. Using these scores, marketers can determine which of the many messages at their disposal should be presented to a specific customer. Similarly, these scores can be used to identify segments of customers that are more or less receptive to a particular form of engagement.
The starting point for most propensity scoring exercises is the calculation of numerical attributes (features) from past interactions. These features may include things such as a customer's frequency of purchases, percentage of spend associated with a particular product category, days since last purchase, and many other metrics derived from the historical data. The historical period immediately following the period from which these features were calculated are then examined for behaviors of interest such as the purchasing of a product within a particular category or the redemption of a coupon. If the behavior is observed, a label of 1 is associated with the features. If it is not, a label of 0 is assigned.
Using the features as predictors of the labels, data scientists can train a model to estimate the probability the behavior of interest will occur. Applying this trained model to features calculated for the most recent period, marketers can estimate the probability a customer will engage in this behavior in the foreseeable future.
With numerous offers, promotions, messages and other content at our disposal, numerous models, each predicting a different behavior, are trained and applied to this same feature set. A per-customer profile consisting of scores for each of the behaviors of interest is compiled and then published to downstream systems for use by marketing in the orchestration of various campaigns.
Databricks provides critical capabilities for propensity scoring
As straightforward as propensity scoring sounds, it's not without its challenges. In our conversations with retailers implementing propensity scoring, we often encounter the same three questions:
- How do we maintain the 100s and sometimes 1,000s of features that we use to train our propensity models?
- How do we rapidly train models aligned with new campaigns that the marketing team wishes to pursue?
- How do we rapidly re-deploy models, retrained as customer patterns drift, into the scoring pipeline?
At Databricks, our focus is on enabling our customers through an analytics platform built with the end-to-end needs of the enterprise in mind. To that end, we've incorporated into our platform features such as the Feature Store, AutoML and MLFlow, all of which can be employed to address these challenges as part of a robust propensity scoring process.
Feature Store
The Databricks Feature Store is a centralized repository that enables the persistence, discovery and sharing of features across various model training exercises. As features are captured, lineage and other metadata are captured so that data scientists wishing to reuse features created by others may do so with confidence and ease. Standard security models ensure that only permitted users and processes may employ these features, so that data science processes are managed in accordance with organizational policies for data access.
AutoML
Databricks AutoML allows you to quickly generate models by leveraging industry best practices. As a glass box solution, AutoML first generates a collection of notebooks representing different model variations aligned with your scenario. While it iteratively trains the different models to determine which works best with your dataset, it allows you to access the notebooks associated with each of these. For many data science teams, these notebooks become an editable starting point for the further exploration of model variations, which ultimately allow them to arrive at a trained model they feel confident can meet their objectives.
MLFlow
MLFlow is an open source machine learning model repository, managed within the Databricks platform. This repository allows the Data Science team to track and analyze the various model iterations generated by both AutoML and custom training cycles alike. Its workflow management capabilities allow organizations to rapidly move trained models from development into production so that trained models can more immediately have an impact on operations.
When used in combination with the Databricks Feature Store, models persisted with MLFlow retain knowledge of the features used during training. As models are retrieved for inference, this same information allows the model to retrieve relevant features from the Feature Store, greatly simplifying the scoring workflow and enabling rapid deployment.
Building a propensity scoring workflow
Using these features in combination, we see many organizations implementing propensity scoring as part of a three-part workflow. In the first part, data engineers work with data scientists to define features relevant to the propensity scoring exercise and persist these to the Feature Store. Daily or even real-time feature engineering processes are then defined to calculate up-to-date feature values as new data inputs arrive.
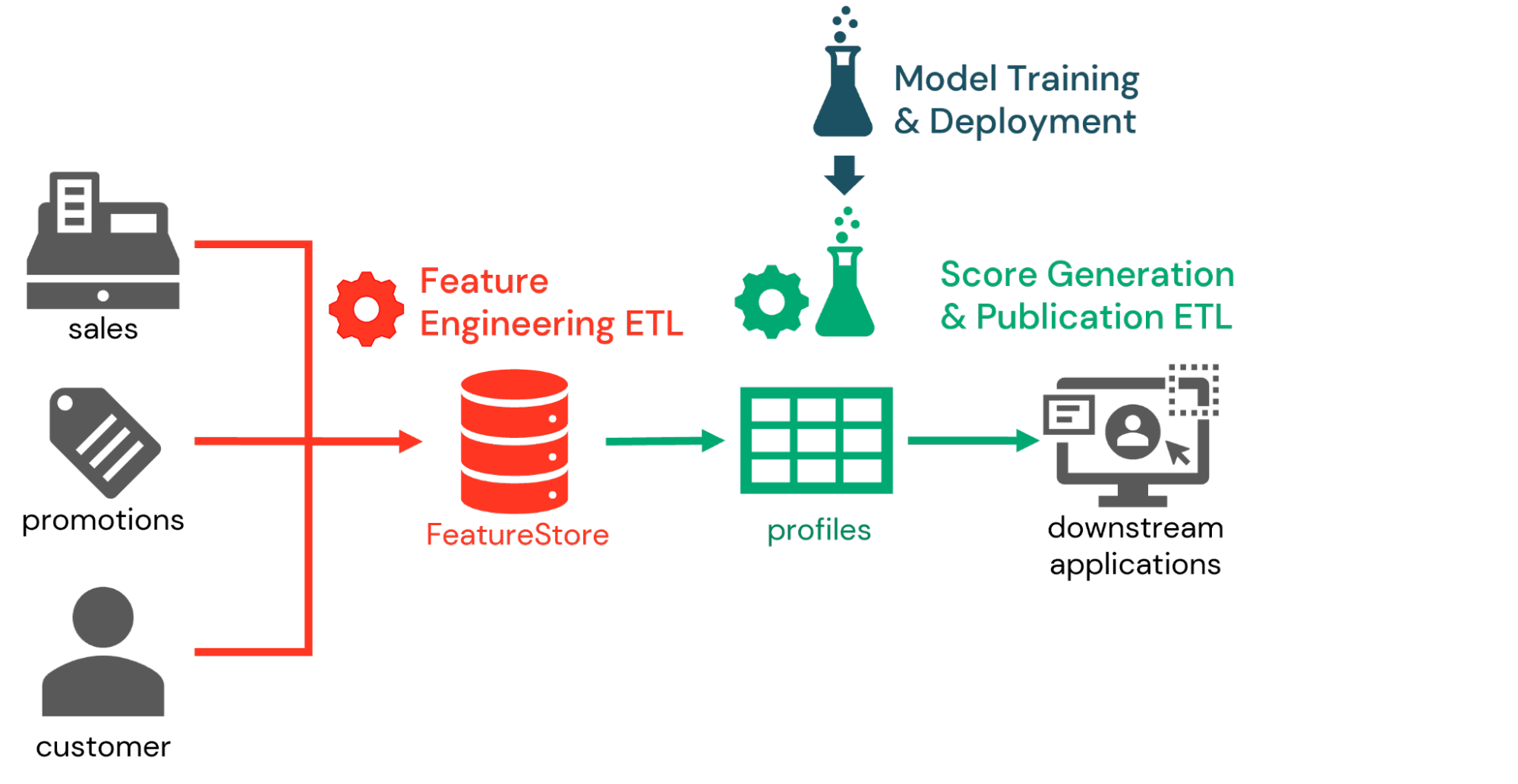
Next, as part of the inference workflow, customer identifiers are presented to previously trained models in order to generate propensity scores based on the latest features available. Feature Store information captured with the model allows data engineers to retrieve these features and generate the desired scores with relative ease. These scores may be persisted for analysis within the Databricks platform, but more typically are published to downstream marketing systems.
Finally, in the model-training workflow, data scientists periodically retrain the propensity score models to capture shifts in customer behaviors. As these models are persisted to MLFLow, change management processes are employed to evaluate the models and elevate those models that meet organizational criteria to production status. In the next iteration of the inference workflow, the latest production version of each model is retrieved to generate customer scores.
To demonstrate how these capabilities work together, we've constructed an end-to-end workflow for propensity scoring based on a publicly available dataset. This workflow demonstrates the three legs of the workflow described above, and shows how to employ key Databricks features to build an effective propensity scoring pipeline.
Download the assets here, and use this as a starting point for building your own foundation for personalization using the Databricks platform.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.