Project Lightspeed: Faster and Simpler Stream Processing With Apache Spark
by Karthik Ramasamy, Matei Zaharia, Reynold Xin, Michael Armbrust, Awez Syed, Ray Zhu, Alexander Balikov, Jerry Peng, Shrikanth Shankar and Sameer Paranjpye
Streaming data is a critical area of computing today. It is the basis for making quick decisions on the enormous amounts of incoming data that systems generate, whether web postings, sales feeds, or sensor data, etc. Processing streaming data is also technically challenging, and it has needs far different from and more complicated to meet than those of event-driven applications and batch processing.
To meet the stream processing needs, Structured Streaming was introduced in Apache Spark™ 2.0. Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. The user can express the logic using SQL or Dataset/DataFrame API. The engine will take care of running the pipeline incrementally and continuously and update the final result as streaming data continues to arrive. Structured Streaming has been the mainstay for several years and is widely adopted across 1000s of organizations, processing more than 1 PB of data (compressed) per day on the Databricks platform alone.
As the adoption accelerated and the diversity of applications moving into streaming increased, new requirements emerged. We are starting a new initiative codenamed Project Lightspeed to meet these requirements, which will take Spark Structured Streaming to the next generation. The requirements addressed by Lightspeed are bucketed into four distinct categories:
- Improving the latency and ensuring it is predictable
- Enhancing functionality for processing data with new operators and APIs
- Improving ecosystem support for connectors
- Simplifying deployment, operations, monitoring and troubleshooting
In this blog, we will discuss the growth of Spark Structured Streaming and its key benefits. Then we will outline an overview of the proposed new features and functionality in Project Lightspeed.
Growth of Spark Structured Streaming
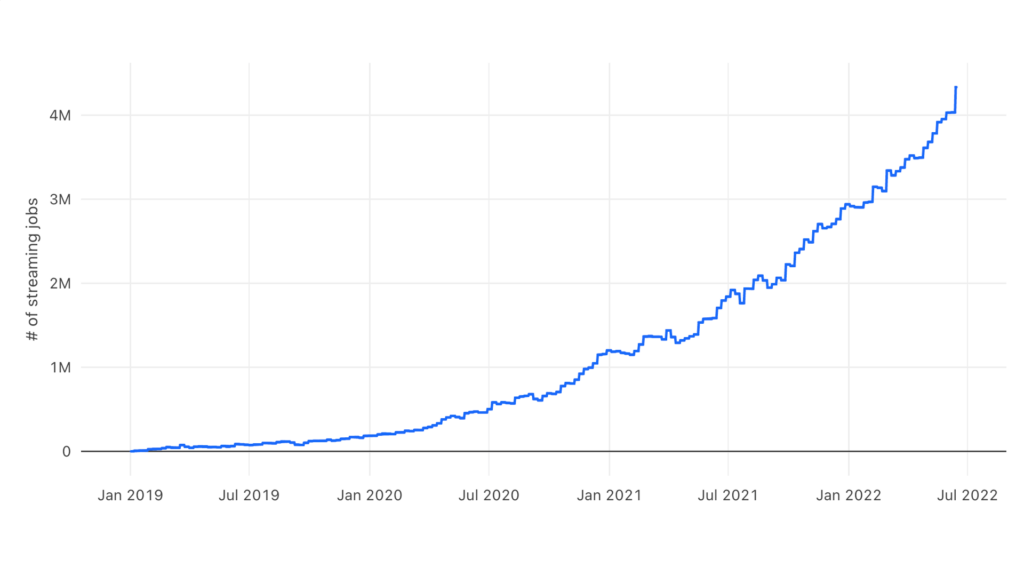
Spark Structured Streaming has been widely adopted since the early days of streaming because of its ease of use, performance, large ecosystem, and developer communities. The majority of streaming workloads we saw were customers migrating their batch workloads to take advantage of the lower latency, fault tolerance, and support for incremental processing that streaming offers. We have seen tremendous adoption from streaming customers for both open source Spark and Databricks. The graph below shows the weekly number of streaming jobs on Databricks over the past three years, which has grown from thousands to 4+ millions and is still accelerating.
Advantages of Spark Structured Streaming
Several properties of Structured Streaming have made it popular for thousands of streaming applications today.
- Unification - The foremost advantage of Structured Streaming is that it uses the same API as batch processing in Spark DataFrames, making the transition to real-time processing from batch much simpler. Users can simply write a DataFrame computation using Python, SQL, or Spark’s other supported languages and ask the engine to run it as an incremental streaming application. The computation will then run incrementally as new data arrives, and recover automatically from failures with exactly-once semantics, while running through the same engine implementation as a batch computation and thus giving consistent results. Such sharing reduces complexity, eliminates the possibility of divergence between batch and streaming workloads, and lowers the cost of operations (consolidation of infrastructure is a key benefit of Lakehouse). Additionally, many of Spark’s other built-in libraries can be called in a streaming context, including ML libraries.
- Fault Tolerance & Recovery - Structured Streaming checkpoints state automatically during processing. When a failure occurs, it automatically recovers from the previous state. The failure recovery is very fast since it is restricted to failed tasks as opposed to restarting the entire streaming pipeline in other systems. Furthermore, fault tolerance using replayable sources and idempotent sinks enables end-to-end exactly-once semantics.
- Performance - Structured Streaming provides very high throughput with seconds of latency at a lower cost, taking full advantage of the performance optimizations in the Spark SQL engine. The system can also adjust itself based on the resources provided thereby trading off cost, throughput and latency and supporting dynamic scaling of a running cluster. This is in contrast to systems that require upfront commitment of resources.
- Flexible Operations - The ability to apply arbitrary logic and operations on the output of a streaming query using foreachBatch, enabling the ability to perform operations like upserts, writes to multiple sinks, and interact with external data sources. Over 40% of our users on Databricks take advantage of this feature.
- Stateful Processing - Support for stateful aggregations and joins along with watermarks for bounded state and late order processing. In addition, arbitrary stateful operations with [flat]mapGroupsWithState backed by a RocksDB state store are provided for efficient and fault-tolerant state management (as of Spark 3.2).
Project Lightspeed
With the significant growing interest in streaming in enterprises and making Spark Structured Streaming the de facto standard across a wide variety of applications, Project Lightspeed will be heavily investing in improving the following areas:
Predictable Low Latency
Apache Spark Structured Streaming provides a balanced performance across multiple dimensions - throughput, latency and cost. As Structured Streaming grew and is used in new applications, we are profiling our customer workloads to guide improvements in tail latency by up to 2x. Towards meeting this goal, some of the initiatives we will be undertaking are as follows:
- Offset Management - Our customer workload profiling and performance experiments indicate that offset management operations consume upto 30-50% of the time for pipelines. This can be improved by making these operations asynchronous and configurable cadence, thereby reducing the latency.
- Asynchronous Checkpointing - Current checkpointing mechanism synchronously writes into object storage after processing a group of records. This contributes substantially to latency. This could be improved by as much as 25% by overlapping the execution of the next group of records with writing of the checkpointing for the previous group of records.
- State Checkpointing Frequency - Spark Structured Streaming checkpoints the state after a group of records have been processed that adds to end-to-end latency. Instead, if we make it tunable to checkpoint every Nth group, the latency can be further reduced depending on the choice for N.
Enhanced Functionality for Processing Data / Events
Spark Structured Streaming already has rich functionality for expressing predominant sets of use cases. As enterprises extend streaming into new use cases, additional functionality is needed to express them concisely. Project Lightspeed is advancing the functionality in the following areas:
- Multiple Stateful Operators - Currently, Structured Streaming supports only one stateful operator per streaming job. However, some use cases require multiple state operators in a job such as:
- Chained time window aggregation (e.g. 5 mins tumble window aggregation followed by 1 hour tumble window aggregation)
- Chained stream-stream outer equality join (e.g. A left outer join B left outer join C)
- Stream-stream time interval join followed by time window aggregation
- Project Lightspeed will add support for this capability with consistent semantics.
- Advanced Windowing - Spark Structured Streaming provides basic windowing that addresses most use cases. Advanced windowing will augment this functionality with simple, easy to use, and intuitive API to support arbitrary groups of window elements, define generic processing logic over the window, ability to describe when to trigger the processing logic and the option to evict window elements before or after the processing logic is applied.
- State Management - Stateful support is provided through predefined aggregators and joins. In addition, specialized APIs are provided for direct access to state and manipulating it. New functionality, in Lightspeed, will incorporate the evolution of the state schema as the processing logic changes and the ability to query the state externally.
- Asynchronous I/O - Often, in ETL, there is a need to join a stream with external databases and microservices. Project Lightspeed will introduce a new API that manages connections to external systems, batch requests for efficiency and handles them asynchronously.
- Python API Parity - While Python API is popular, it still lacks the primitives for stateful processing. Lightspeed will add a powerful yet simple API for storing and manipulating state. Furthermore, Lightspeed will provide tighter integrations with popular Python data processing packages like Pandas - to make it easy for the developers.
Connectors and Ecosystem
Connectors make it easier to use the Spark Structured Streaming engine to process data from and write processed data into various messaging buses like Apache Kafka and storage systems like Delta lake. As part of Project Lightspeed, we will work on the following:
- New Connectors - We will add new connectors working with partners (for example, Google Pub/Sub, Amazon DynamoDB) to enable developers to easily use the Spark Structured Streaming engine with additional messaging buses and storage systems they prefer.
- Connector Enhancement - We will enable new functionalities and improve performance on existing connectors. Some examples include AWS IAM auth support in the Apache Kafka connector and enhanced fan-out support in the Amazon Kinesis connector.
Operations and Troubleshooting
Structured Streaming jobs are continuously running until explicitly terminated. Because of the always-on nature, it is necessary to have the appropriate tools and metrics to monitor, debug and alert when certain thresholds are exceeded. Towards satisfying these goals, Project Lightspeed will improve the following:
- Observability - Currently, the metrics generated from structured streaming pipelines for monitoring require coding to collect and visualize. We will unify the metric collection mechanism and provide capabilities to export to different systems and formats. Furthermore, based on customer input, we will add additional metrics for troubleshooting.
- Debuggability - We will provide capabilities to visualize pipelines and how its operators are grouped and mapped into tasks and the executors the tasks are running. Furthermore, we will implement the ability to drill down to specific executors, browse their logs and various metrics.
What’s Next
In this blog, we discussed the advantages of Spark Structured Streaming and how it contributed to its widespread growth and adoption. We introduced Project Lightspeed which advances Spark Structured Streaming into the real-time era as more and more new use cases and workloads migrate into streaming.
In subsequent blogs, we will expand on the individual categories of improving Spark Structured Streaming performance across multiple dimensions, enhanced functionality, operations and ecosystem support.
Project Lightspeed will roll out incrementally by collaborating and closely working with community. We are expecting most of the features to be delivered by early next year.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.