Building Patient Cohorts with NLP and Knowledge Graphs
by Amir Kermany, Moritz Steller, David Talby and Michael Sanky
Check out the solution accelerator to download the notebooks referred throughout this blog.
Cohort building is an essential part of patient analytics. Defining which patients belong to a cohort, testing the sensitivity of various inclusion and exclusion criteria on sample size, building a control cohort with propensity score matching techniques: These are just some of the processes that healthcare and life sciences researchers live day in and day out, and that's unlikely to change anytime soon. What is changing is the underlying data, the complexity of clinical criteria, and the dynamism demanded by the industry.
While tools exist for building patient cohorts based on structured data from EHR data or claims, their practical utility is limited. More and more, cohort building in healthcare and life sciences requires criteria extracted from unstructured and semi-structured clinical documentation with Natural Language Processing (NLP) pipelines. Making this a reality requires a seamless combination of three technologies:
(1) a platform that scales for computationally-intensive calculations of massive real world datasets,
(2) an accurate NLP library & healthcare-specific models to extract and relate entities from medical documents, and
(3) a knowledge graph toolset, able to represent the relationships between a network of entities.
The latest solution from John Snow Labs and Databricks brings all of this together in the Lakehouse.
Optimizing clinical trial protocols
Let's consider one high impact application of dynamic cohort building.
Recruiting and retaining patients for clinical trials is a long-standing problem that the pandemic has exacerbated. 80% of trials are delayed due to recruitment problems1, with many sites under-enrolling. Delays in recruitment have huge financial implications in terms of both the cash burn to manage extended trials and the opportunity cost of patent life, not to mention the implications of delaying potentially life-saving medications.
One of the challenges is that as medications become more specialized, clinical trial protocols are increasingly complex. It is not uncommon to see upwards of 40 different criteria for inclusion and exclusion. The old age "measure twice, cut once" is exceedingly important here. Let's look at a relatively straightforward example of a protocol for a Phase 3 trial estimated to run for six years: Effect of Evolocumab in Patients at High Cardiovascular Risk Without Prior Myocardial Infarction or Stroke (VESALIUS-CV)2:

In terms of protocol design, the inclusion and exclusion criteria must be targeted enough to have the appropriate clinical sensitivity, and broad enough to facilitate recruitment. Real world data can provide the guideposts to help forecast patient eligibility and understand the relative impact of various criteria. In the example above, does left-ventricular ejection fraction > 30% limit the population by 10%, 20%? How about eGFR < 15? Does clinical documentation include mentions of atrial flutter that are not diagnosed, which would impact screen failure rates?
Fortunately, these questions can be answered with real-world data and AI.
Site selection and patient recruitment
Similar challenges exist once a clinical trial protocol has been defined. One of the next decisions for a pharmaceutical company is where to set up sites for the trial. Setting up a site is time consuming, expensive, and often wasteful - Over two-thirds of sites fail to meet their original patient enrollment goals and ip to 50% of sites enroll one or no patients in their studies3.
This challenge is amplified in newer clinical trials - especially those focusing on rare diseases, or on cancer patients with specific genomic biomarkers. In those cases, a hospital may see only a handful of relevant patients per year, so estimating in advance how many patients are candidates for a trial, and then actually recruiting them when they appear, are both critical to timely success.
The advent of precision health leads to many more clinical trials that target a very small population4. This requires the automation scale to find candidate patients to these trials automatically, as well as
3https://www.clinicalleader.com/doc/considerations-for-improving-patient-0001
4https://www.webmd.com/cancer/precision-medicine-clinical-trials
state-of-the-art NLP capabilities since trial inclusion and exclusion criteria call out more facts that are only available in unstructured text. These facts include genomic variants, social determinants of health, family history, and specific tumor characteristics.
Fortunately, new AI technology is now ready to meet these challenges.
Design and Run Better Clinical Trials with John Snow Labs & Databricks
First, lets understand the end to end solution architecture for Patient Cohort Building with NLP and Knowledge Graphs:
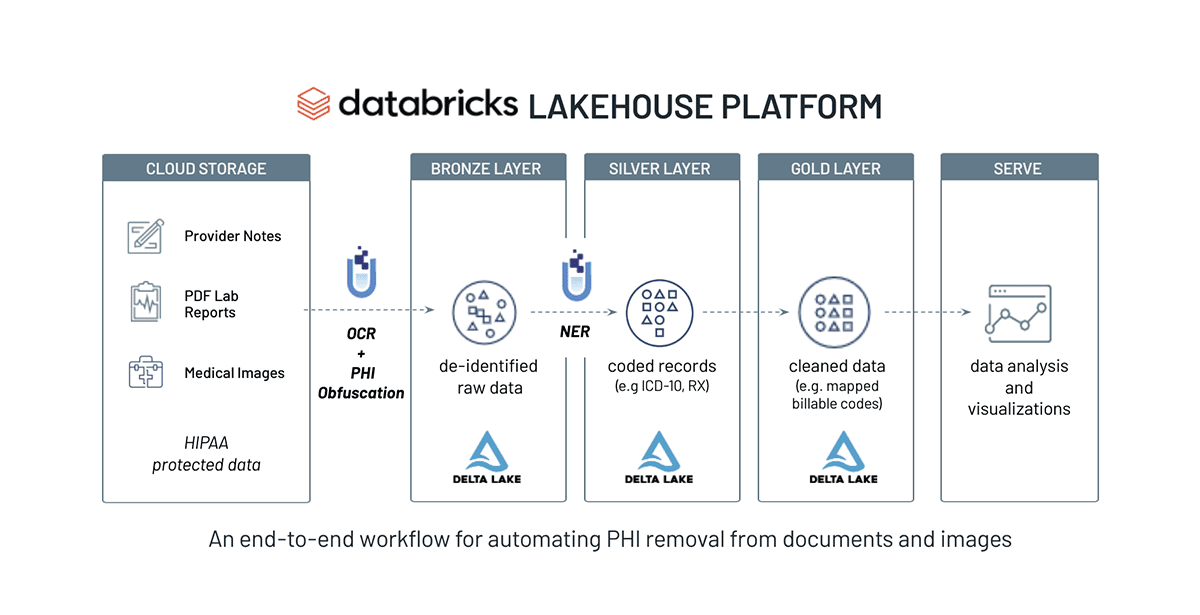
We will build a Knowledge Graph (KG) using Spark NLP relation extraction models and a graph API. The main point of this solution is to show creating a clinical knowledge graph using Spark NLP pretrained models. For this purpose, we will use pretrained relation extraction and NER models. After creating the knowledge graph, we will query the KG to get some insightful results.
As Building Patient Cohorts with NLP and Knowledge Graphs was part of DAIS 2022, please view its session here: demo.
NLP Pre-Processing
Overall, there are 965 clinical records in our example dataset stored in Delta table. We read the data and write the records into bronze Delta tables.
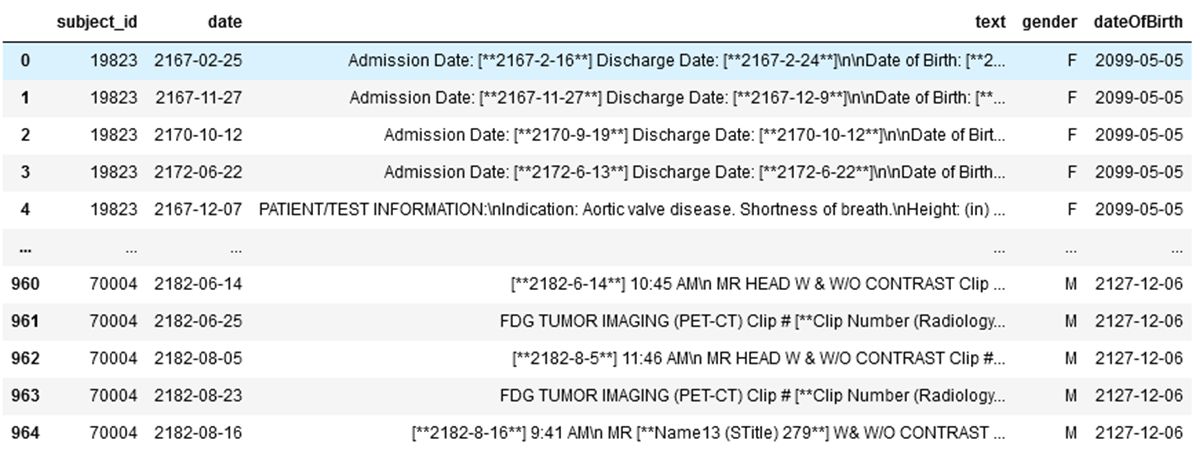
Extracting from relationships from the text in this dataframe, SparkNLP for Healthcare applies a Posology relation extraction pretrained model that supports the following relations:
DRUG-DOSAGE, DRUG-FREQUENCY, DRUG-ADE (Adverse Drug Events), DRUG-FORM, DRUG-ROUTE, DRUG-DURATION, DRUG-REASON, DRUG=STRENGTH
The model has been validated against the posology dataset described in (Magge, Scotch, & Gonzalez-Hernandez, 2018) http://proceedings.mlr.press/v90/magge18a/magge18a.pdf.
| Relation | Recall | Precision | F1 | F1 (Magge, Scotch, & Gonzalez-Hernandez, 2018) |
|---|---|---|---|---|
| DRUG-ADE | 0.66 | 1.00 | 0.80 | 0.76 |
| DRUG-DOSAGE | 0.89 | 1.00 | 0.94 | 0.91 |
| DRUG-DURATION | 0.75 | 1.00 | 0.85 | 0.92 |
| DRUG-FORM | 0.88 | 1.00 | 0.94 | 0.95* |
| DRUG-FREQUENCY | 0.79 | 1.00 | 0.88 | 0.90 |
| DRUG-REASON | 0.60 | 1.00 | 0.75 | 0.70 |
| DRUG-ROUTE | 0.79 | 1.00 | 0.88 | 0.95* |
| DRUG-STRENGTH | 0.95 | 1.00 | 0.98 | 0.97 |
*Magge, Scotch, Gonzalez-Hernandez (2018) collapsed DRUG-FORM and DRUG-ROUTE into a single relation.
Within our NLP pipeline, Spark NLP for Healthcare is following the standardized steps of preprocessing (documenter, sentencer, tokenizer), word embeddings, part-of-speech tagger, NER, dependency parsing, and relation extraction. Relation extraction in particular is the most important step in this pipeline as it establishes the connection by bringing relationships to the extracted NER chunks.
The resulting dataframe includes all relationships accordingly:
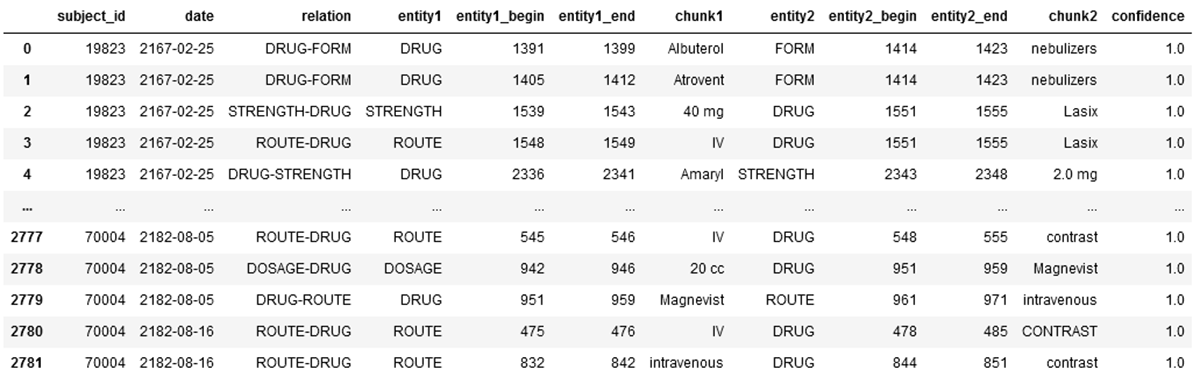
Within our Lakehouse for Healthcare, this final dataframe will be written to the silver layer.
Next, the RxNorm codes are extracted from the prior established dataset. Firstly, we use a basic rules based logic to define and clean up 'entity1' and 'entity2', followed by an SBERT (Sentence BERT) based embedder and BioBERT based resolver support the transformation to rxnorm codes.
See below for the first three records of the silver layer data set the extracted Rx related text, its NER chunks, the applicable RxNorm code, all related codes, RxNorm resolutions and final drug resolution.
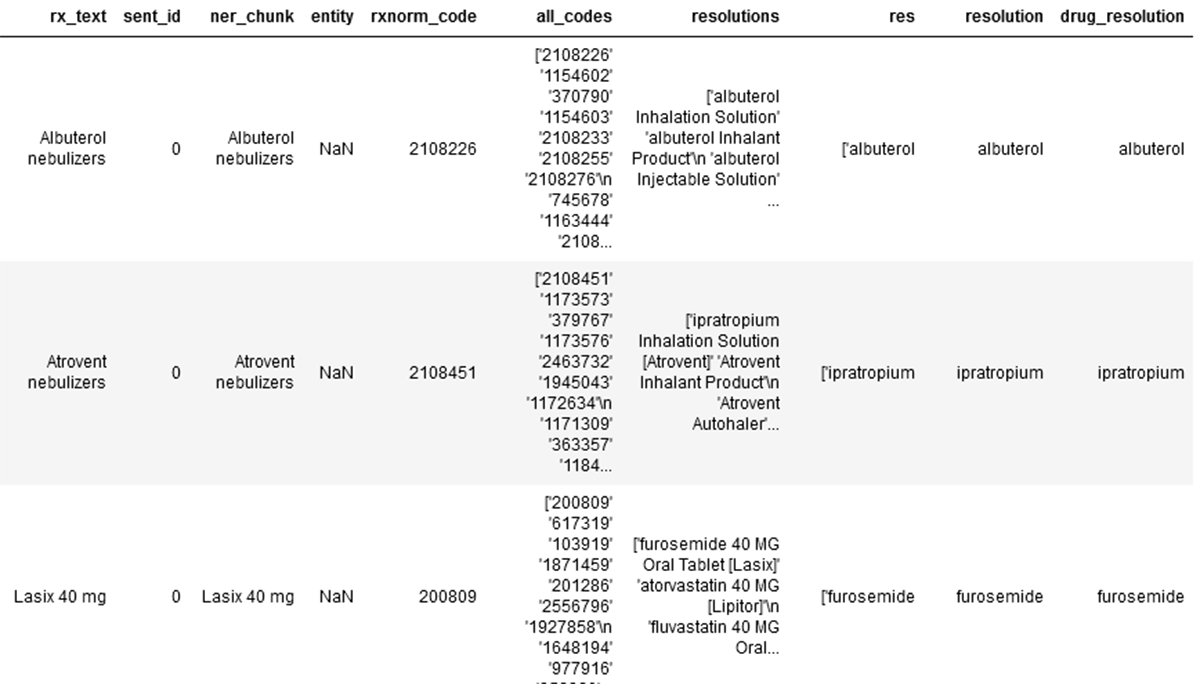
This result dataframe is written to the gold layer.
Lastly, a pretrained named entity recognition deep learning model for clinical terminology (https://nlp.johnsnowlabs.com/2021/08/13/ner_jsl_slim_en.html) is applied to our initial dataset to extract generalized entities from our medical text.
The result dataframe includes the NER chunk and NER label from the unstructured text:
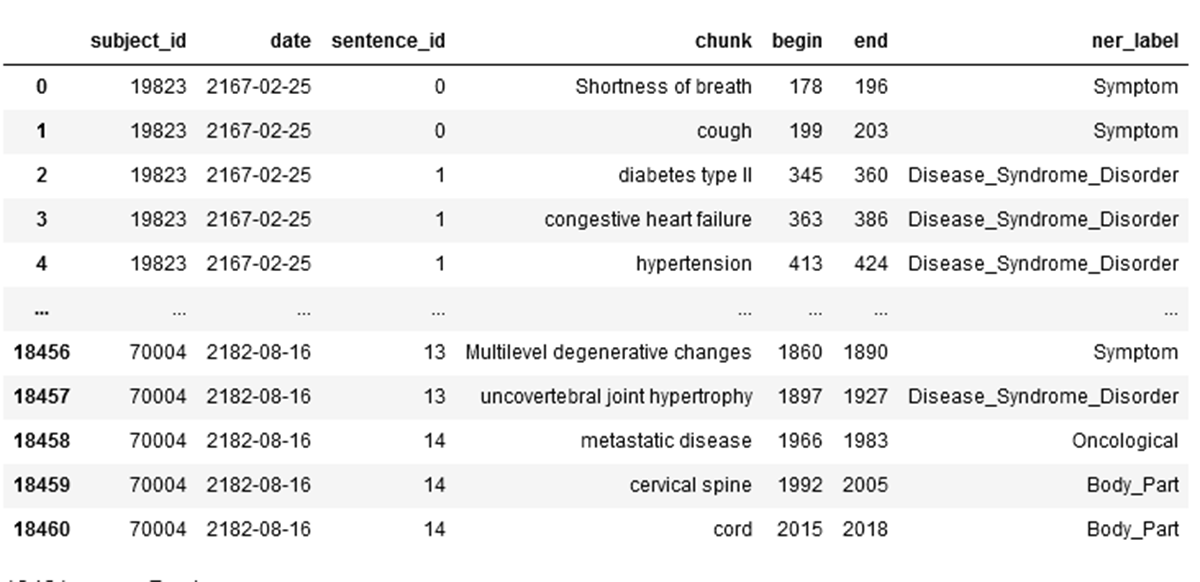
This result dataframe is written to the gold layer.
Creating and Querying of the Knowledge Graph
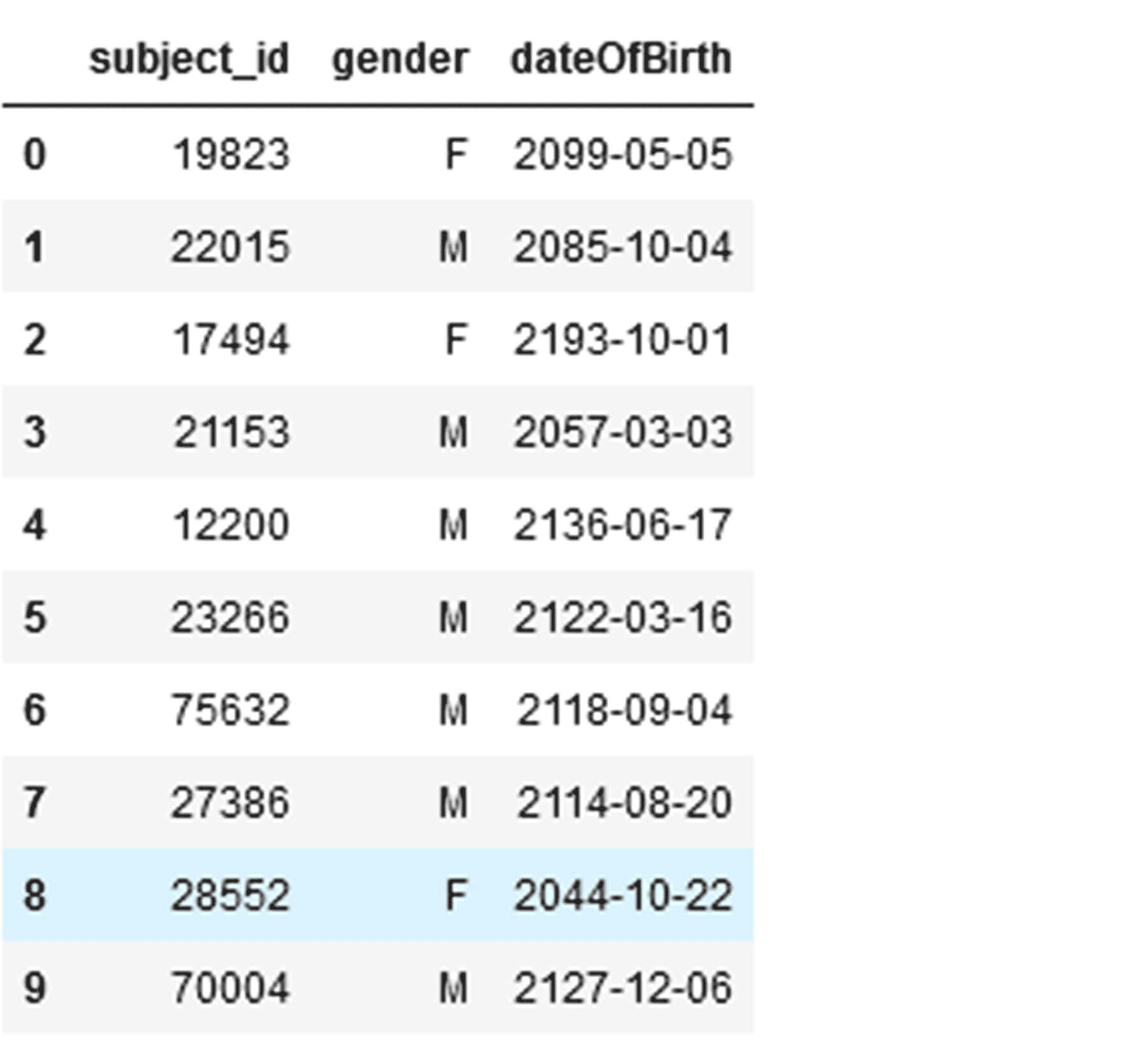
For the creation of the Knowledge Graph (KG), the prior result dataframes in the golden layer are required as well as additional tabular de-identified demographic information of patients. See:
For building the KG, best practices are to use your main cloud provider's graph capabilities. Two agnostic options to build a sufficient graph are: 1. Write your dataframe to a NoSql Database and use its graph API 2. Use a native graph database.
The goal of both options is to get to a graph schema for the extracted entities that look the following:
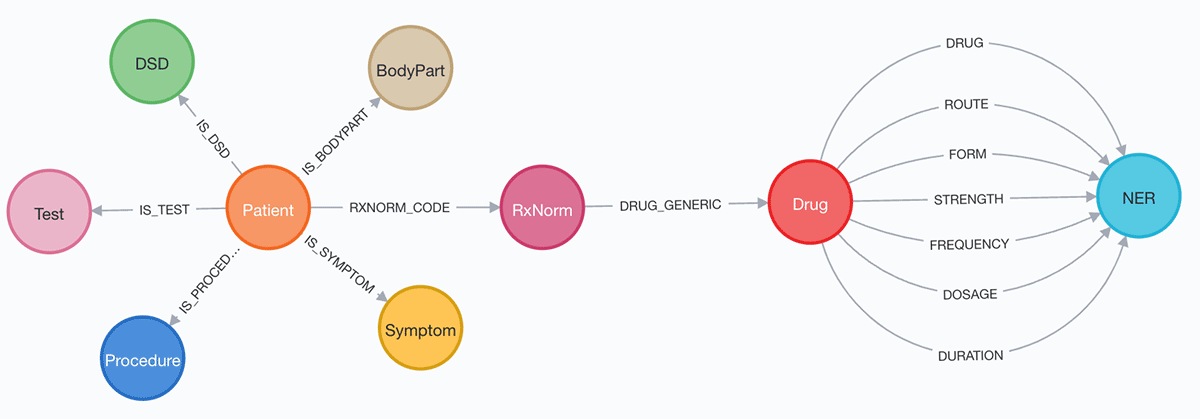
This can be achieved by splitting dataframe into multiple dataframes by ner_label and creating nodes and relationships. Examples for establishing relationship are (Examples are written in Cypher https://neo4j.com/developer/cypher/ ):
Once the KG is properly established, within any of the two options (in this example a graph database), a schema check will validate the count of records in each node and relationship:

The KG is now ready to be intelligently queried to retrieve information based on the underlying established relationships within our NLP RE steps prior. The following shows a set of queries answering clinical questions:
1. Patient 21153's journey in medical records: symptoms, procedures, disease-syndrome-disorders, test, drugs & rxnorms:
Query:
Dataframe:

Graph:

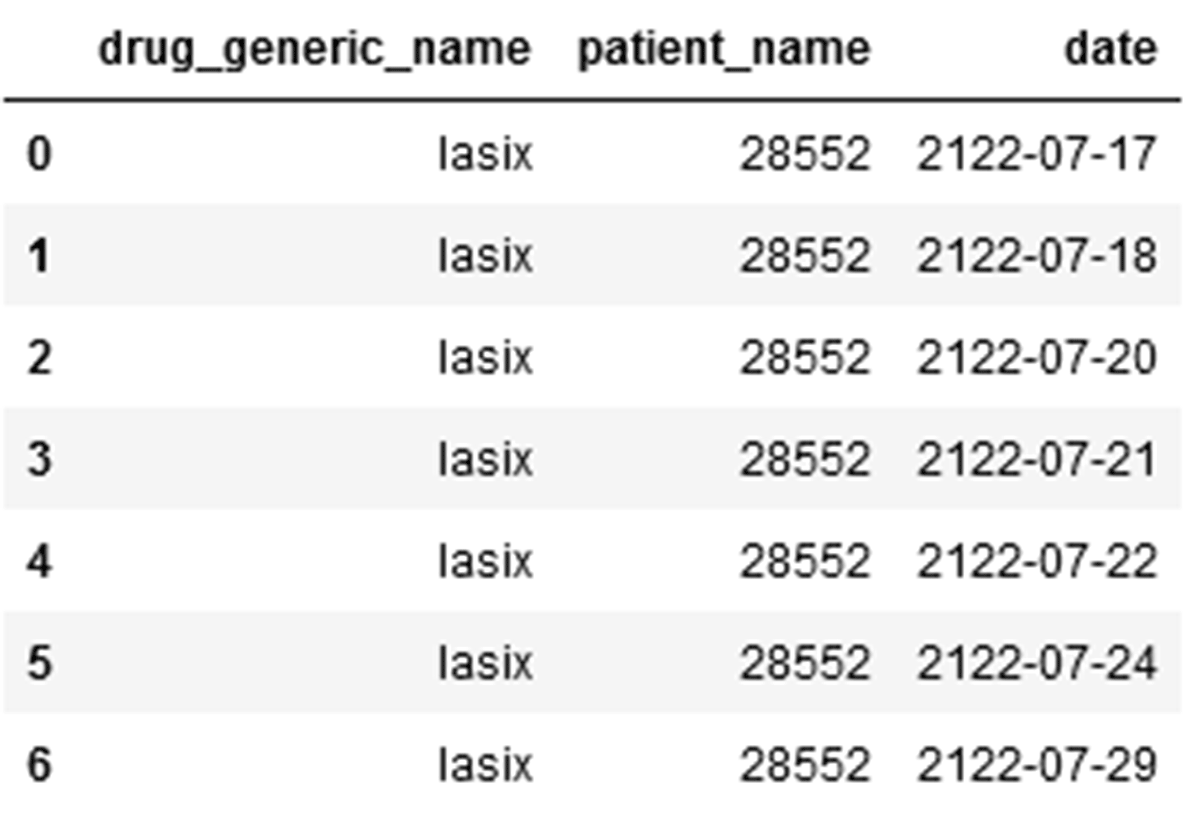
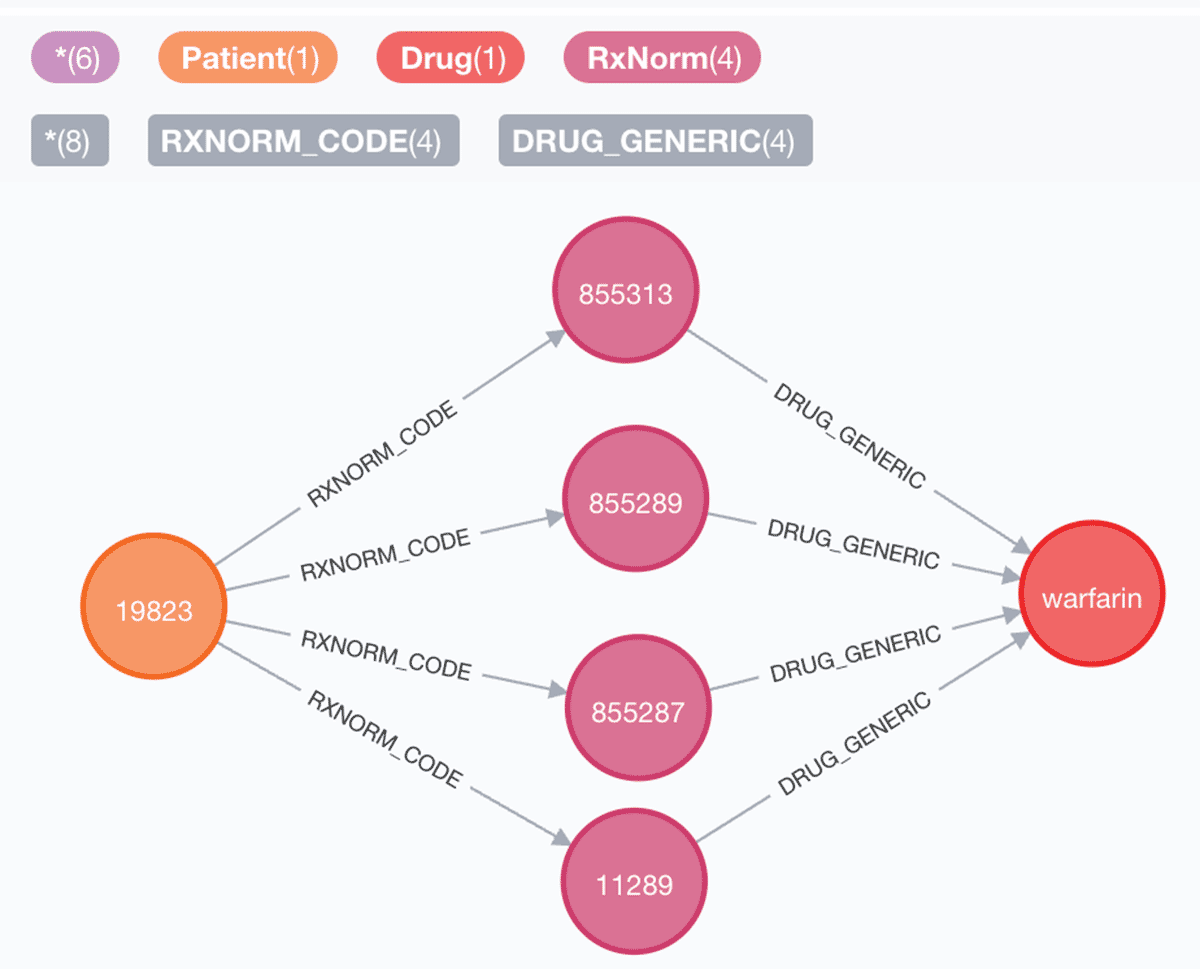
2. Patients who are prescribed Lasix between May 2060 and May 2125:
Query:
Dataframe:
Graph:
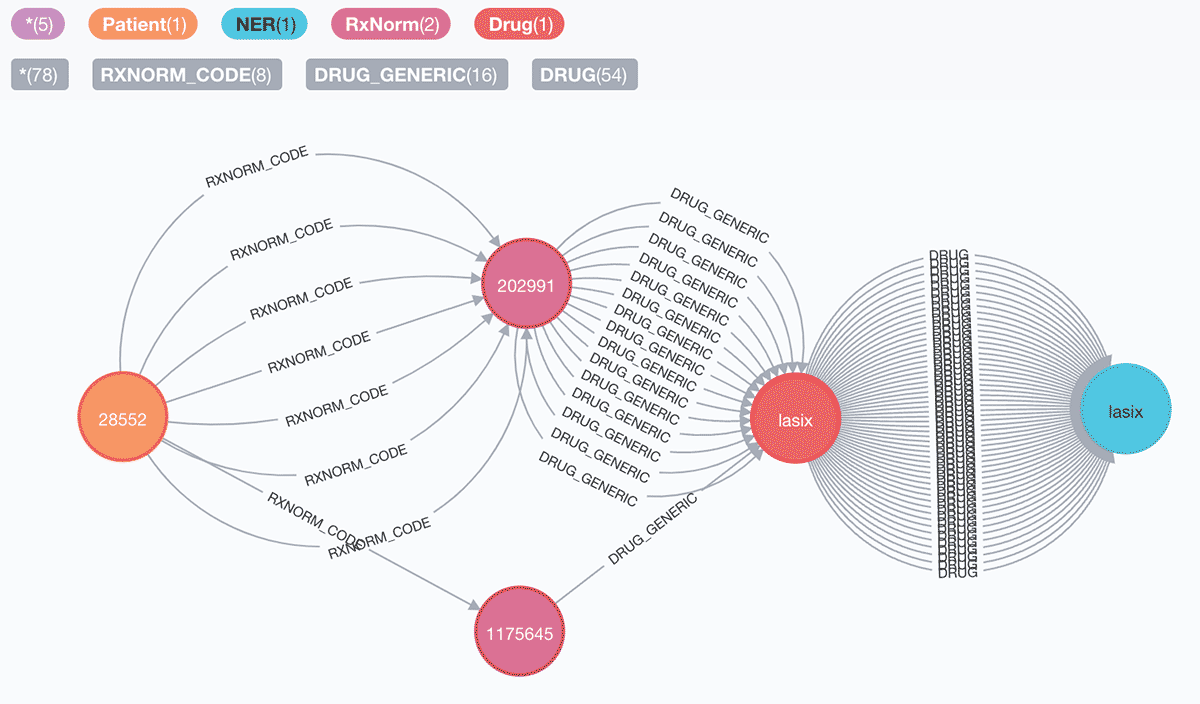
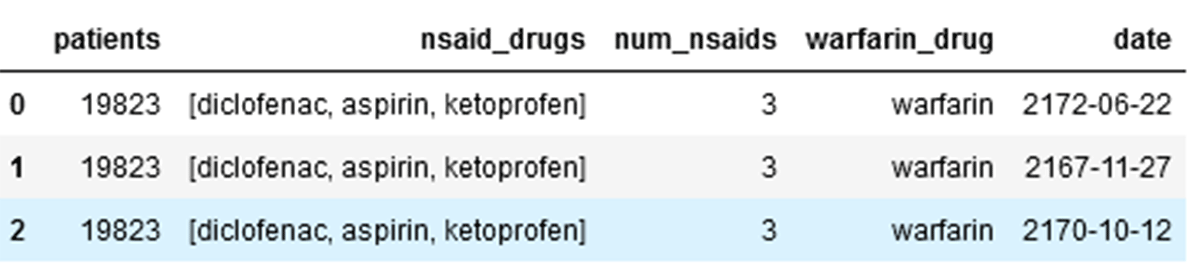
3. Dangerous drug combinations:
Query:
Dataframe:
Graph:
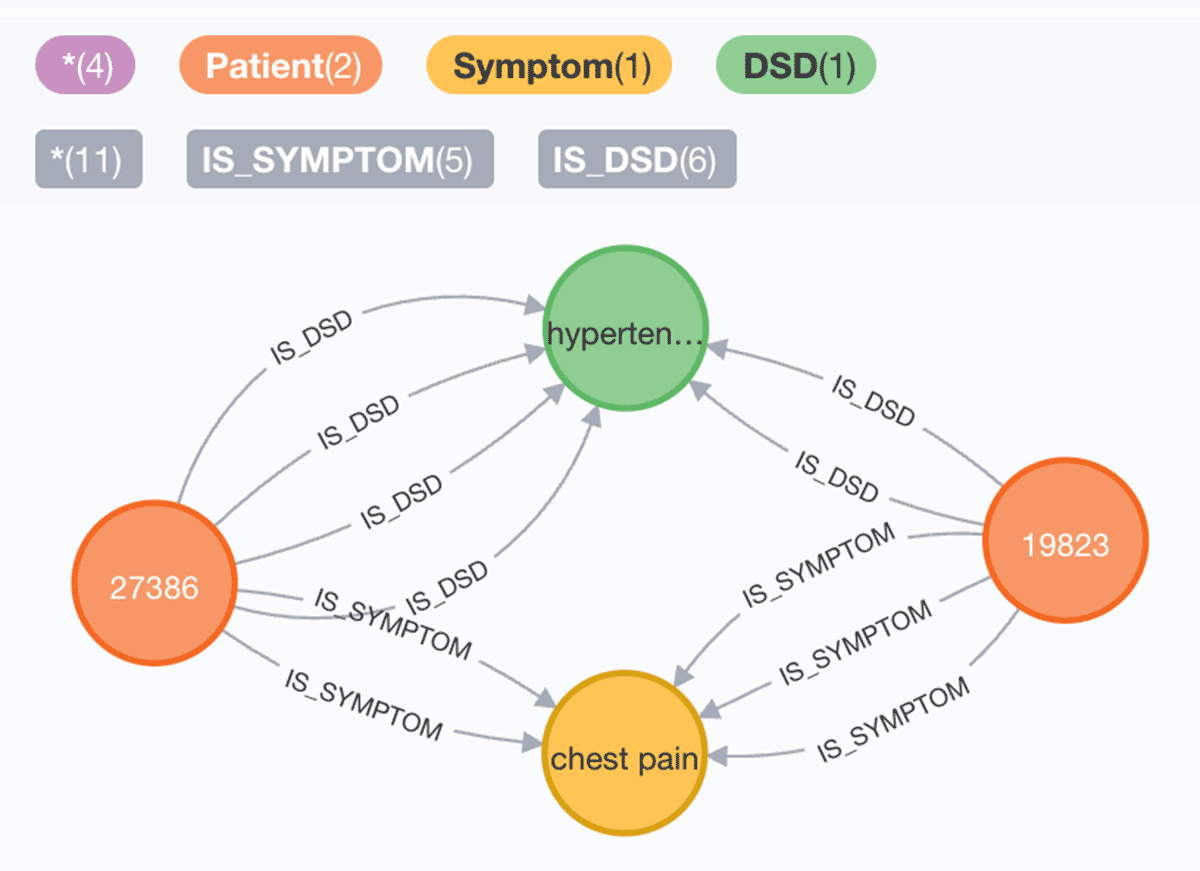
4. Patients with hypertension or diabetes with chest pain:
Query:
Dataframe:

Graph:
SparkNLP and your preferred native KG database or KG API work well together for building knowledge graphs from extracted entities and established relationships. In many scenarios, Federal Agencies and industry enterprises require retrieving cohorts fast to gain population health or adverse event insights. As most data is available as unstructured text from clinical documents, as demonstrated, we can create a scalable and automated production solution to extract entities, build their relationships, establish a KG, and ask intelligent queries where the Lakehouse supports the end-to-end.
Start building your Cohorts with Knowledge Graphs using NLP
With this Solution Accelerator, Databricks and John Snow Labs make it easy to enable building clinical cohorts using KGs.
To use this Solution Accelerator, you can preview the notebooks online and import them directly into your Databricks account. The notebooks include guidance for installing the related John Snow Labs NLP libraries and license keys.
You can also visit our Lakehouse for Healthcare and Life Sciences page to learn about all of our solutions.
1https://www.biopharmadive.com/spons/decentralized-clinical-trials-are-we-ready-to-make-the-leap/546591
2https://clinicaltrials.gov/ct2/show/NCT03872401
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.