Faster MERGE Performance With Low-Shuffle MERGE and Photon
by Bart Samwel, Piyush Revuri, Himanshu Raja, Justin Breese, Tom van Bussel, Lars Kroll, Sabir Akhadov, Tathagata Das and Prakhar Jain
At Databricks, one of our key goals is to provide our customers with an industry-best price/performance experience out of the box. From ETL to analytics, streaming to batch, Databricks continues to invest in the Lakehouse to provide customers with the best read and write query performance in all scenarios.
The Lakehouse has enabled customers to process large volumes of data at low latencies while keeping storage and compute costs within customer budgets. Today, Databricks customers are processing over 1 Exabyte of data every day, with DML (Data Manipulation Language) operations like MERGE, UPDATE and DELETE representing a large fraction of the workload. MERGE, specifically, is one of the key tools for data engineers to ingest, transform and update their tables, making up about half the time spent out of all write operations in Databricks. In this blog, we will dive deeper into how we improved performance of MERGE operations for customers to ensure that they continue to attain the industry-best price/performance with Delta Lake and Databricks.
What needed improvement?
During our investigation to determine what needed improvement for MERGE, we found that a significant number of MERGE operations made small changes across various distributed parts of their tables.

A common example of this scenario is a CDC (Change Data Capture) ingestion workload that replays changes from a dimension table based on a primary key. For these types of workloads, small changes are scattered throughout various files of the table and MERGE would only be updating a relatively small number of rows per file for the operation. For such workloads, MERGE may trigger costly rewrite and shuffle operations on large amounts of unmodified data, doing unnecessary work and adding significant overhead.
In addition, we noticed that for tables that were clustered using Delta Lake's ZORDER, the MERGE implementation would break the intended clustering of unmodified data by doing the expensive shuffle process. As a result, customers would be required to re-run ZORDER to ensure that they were getting the optimal data skipping.
To dive deeper into the MERGE operation - the operation joins the source and destination (Step 1 shown below) which, in Apache Spark™, shuffles the rows in the table, breaking the existing ordering of the table. MERGE then executes the changeset against the joined table, writing the resulting set of rows into a new file (Step 2 shown below).
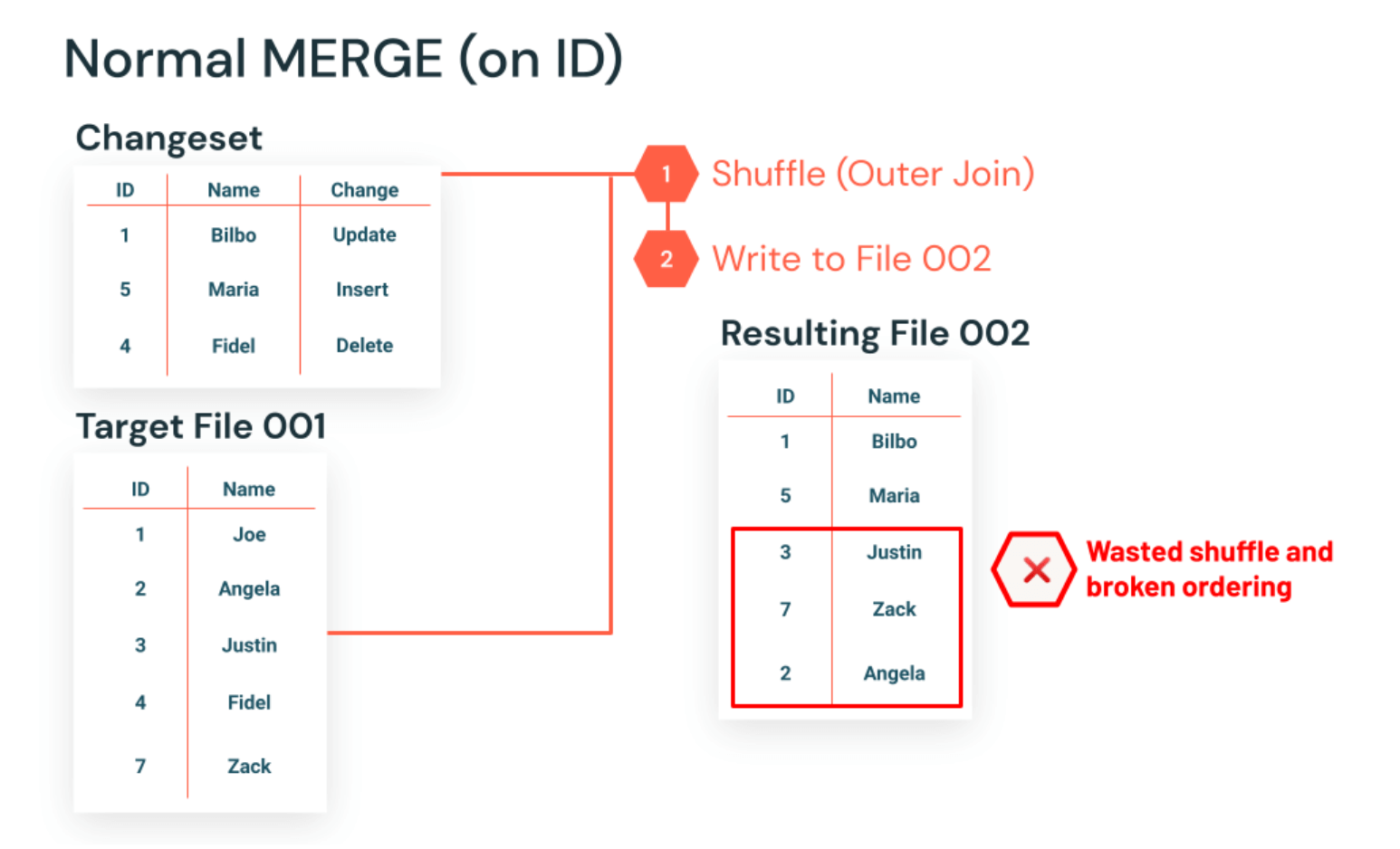
Introducing Low-Shuffle MERGE!
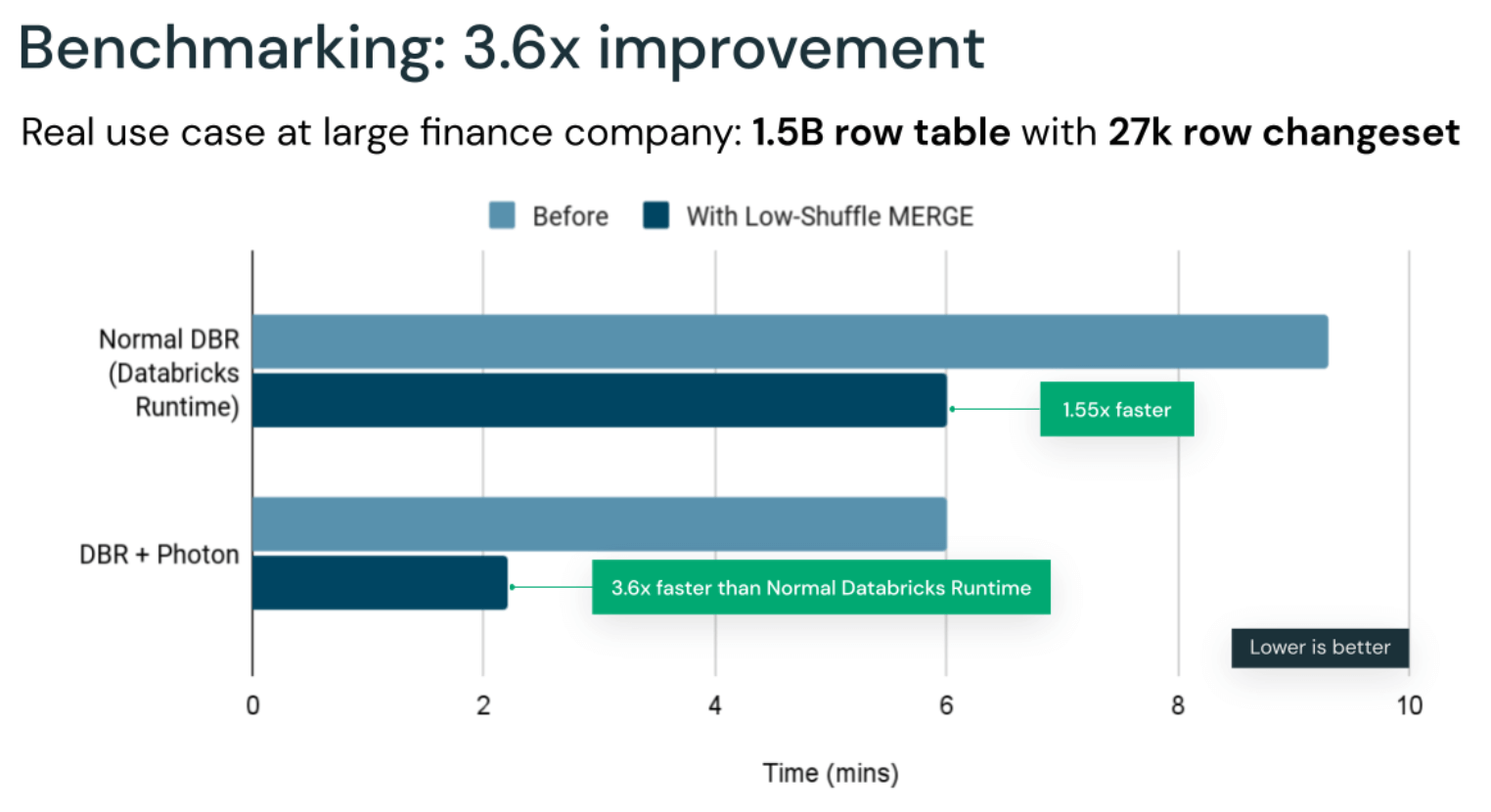
By removing this expensive shuffle process, we fixed two major performance issues customers were experiencing when running MERGE. Low-Shuffle Merge (LSM) delivers up to 5x performance improvement on MERGE-based workloads with the average on the order of 2-3x. This substantial improvement translates directly to faster write queries and lower compute costs by avoiding unnecessary shuffling and rewrite operations when updates are distributed across multiple table files.
Low-Shuffle MERGE optimizes execution by removing any updated and deleted rows (Step 2 shown below) from the original file while writing any new and updated rows (Step 1 shown below) in a separate file, removing the need to process and shuffle the rest of the rows in the original file, significantly reducing the amount of work required to do MERGE.

In addition to removing the processing overhead on unmodified rows, ZORDER clustering is now maintained, delivering great data skipping without the additional burden of re-running an expensive ZORDER operation after executing MERGE.
Photon + Low-Shuffle Merge
In a previous blog, we've announced our new execution engine, Photon. Photon's vectorized implementation speeds up many operations, including aggregations, joins, reads and writes. Joins, reads and writes are typical bottlenecks for MERGE workloads, therefore making Photon and LSM a perfect match. Using both Photon and LSM together can result in up to a 4x performance increase.
Customer examples
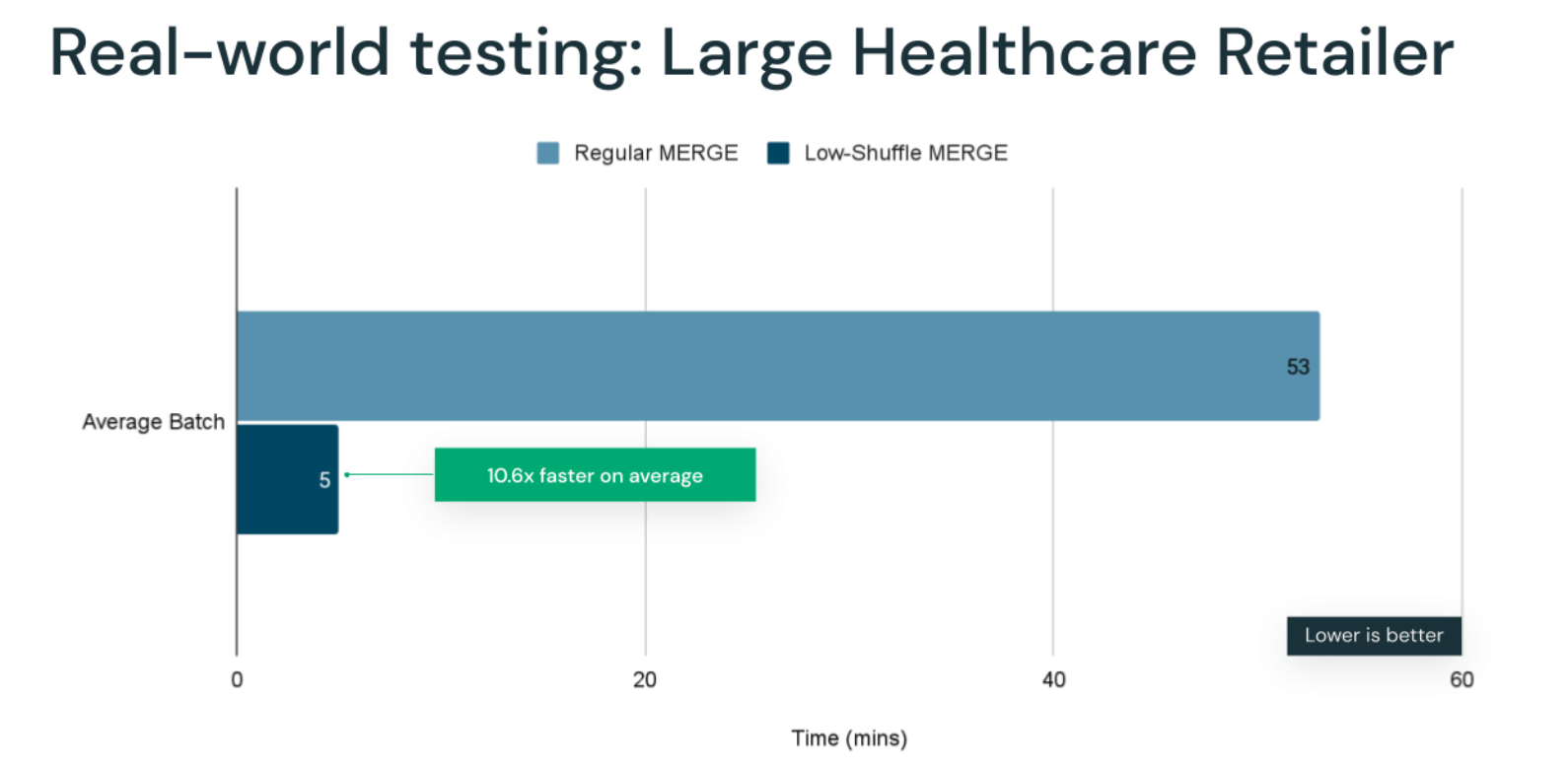
Large healthcare customer
Low-Shuffle MERGE was remarkably effective in improving the performance of MERGE workloads for a large healthcare company that produced various healthcare products from home goods to medical devices. The company uses Databricks to retain and analyze sensor data to improve medical outcomes, requiring up to date analytics with constantly streaming data. They do this by taking advantage of Delta Lake's streaming capabilities to continuously MERGE changes, updating older data and appending new data. Using just Low-Shuffle MERGE without Photon with their production workload, the company achieved an average batch MERGE speedup of 10.6x. With this massive speedup, the streaming data that used to take 1 hour of processing time is now available to query in 5 minutes, significantly reducing their time to insights.
Large fintech customer
Another case where Low-Shuffle MERGE provided a significant benefit was when a large fintech company was attempting to reduce the SLA of one of their ingest pipelines that supports a fraud detection use case. Reducing the amount of time between when data was updated and when it was available for querying in the Lakehouse increased the value of the data significantly for the company. The ingestion workload update data sparsely across a large time domain, which led to to higher processing times.
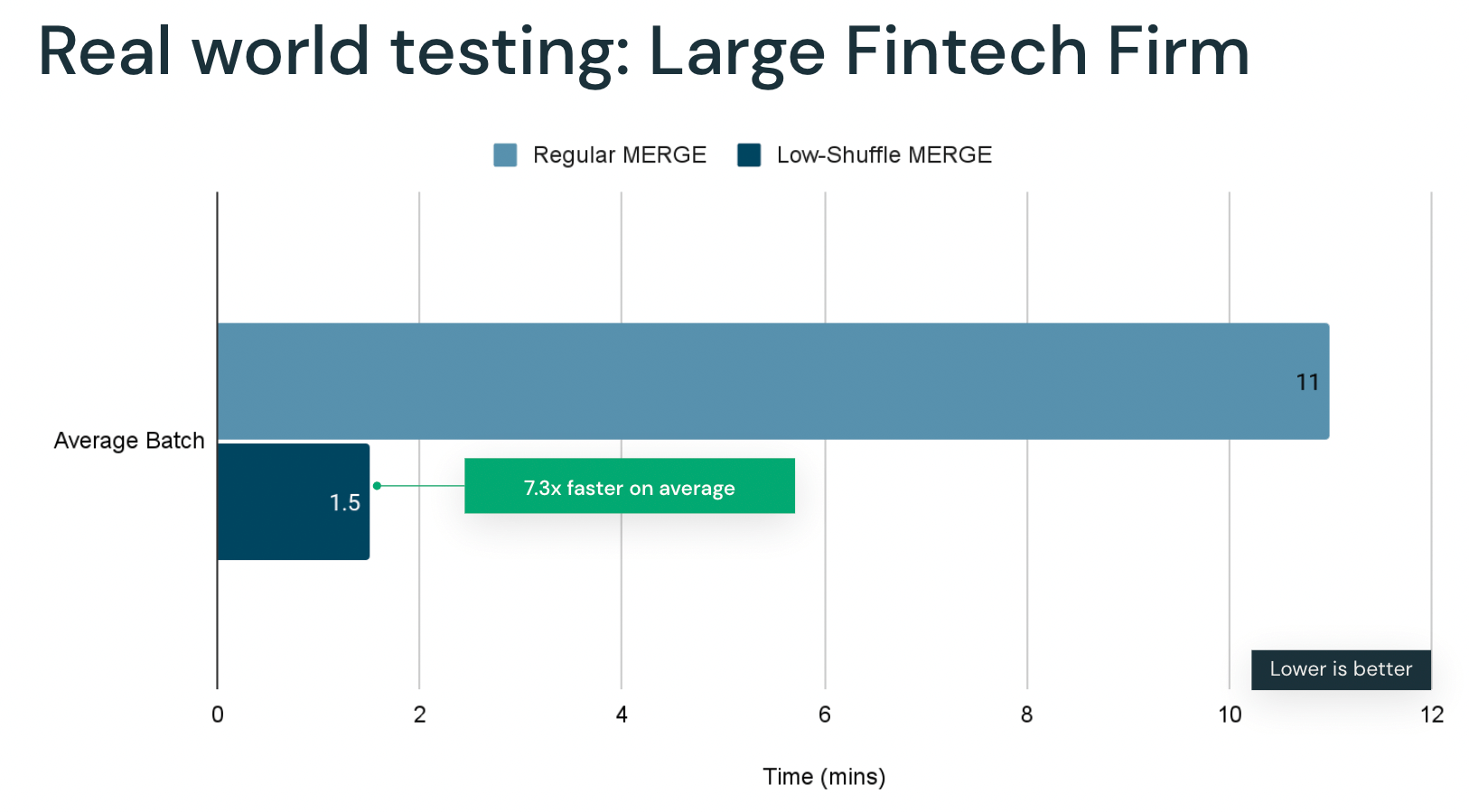
With the new optimized merge, the customer was able to reduce their average merge time from 11 minutes to 1.5 minutes, improving their average batch merge performance by 7x.
Concluding remarks
Low-Shuffle MERGE is enabled by default for all MERGEs in Databricks Runtime 10.4+ and also in the current Databricks SQL warehouse compute version.
For those wanting a more detailed, visual explanation, check out this great video by Advancing Spark that walks you through how Low-Shuffle MERGE works!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.