Skip to main content![Tathagata Das]()
![lake]()
![Social-Graphic-for-Delta-Lake-The-Definitive-Guide-Blog]()
![delta-8-0-og2]()
![Data Intelligence Platforms]()
![Data Intelligence Platforms]()
![An example of the operational metrics now available for review in the Spark UI through Delta Lake 0.6.0]()
![delta-lake]()
![Data Intelligence Platforms]()

Tathagata Das
Tathagata Das's posts

Engineering
June 29, 2023/6 min read
Announcing Delta Lake 3.0 with New Universal Format and Liquid Clustering


Open Source
June 22, 2021/8 min read
Get Your Free Copy of Delta Lake: The Definitive Guide (Early Release)

Data Engineering
February 10, 2021/8 min read
Automatically Evolve Your Nested Column Schema, Stream From a Delta Table Version, and Check Your Constraints

Open Source
September 29, 2020/9 min read
Diving Into Delta Lake: DML Internals (Update, Delete, Merge)
Solutions
August 27, 2020/13 min read
Enabling Spark SQL DDL and DML in Delta Lake on Apache Spark 3.0
Solutions
May 19, 2020/7 min read
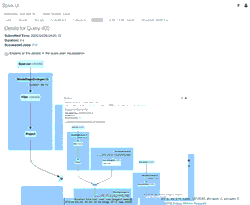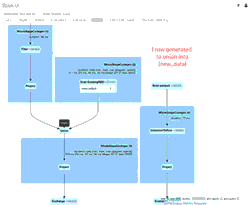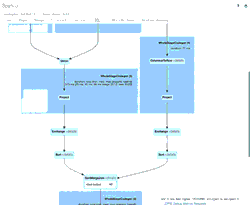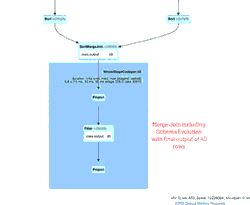
Schema Evolution in Merge Operations and Operational Metrics in Delta Lake

Solutions
January 29, 2020/7 min read
Query Delta Lake Tables from Presto and Athena, Improved Operations Concurrency, and Merge performance
Solutions
October 3, 2019/12 min read
Simple, Reliable Upserts and Deletes on Delta Lake Tables using Python APIs

Showing 1 - 12 of 20 results