Intermittent Demand Forecasting With Nixtla on Databricks

This is a collaborative post from Nixtla and Databricks. We thank Max Mergenthaler Canseco, CEO and Co-founder, and Federico Garza Ramírez, CTO and Co-founder, of Nixtla for their contributions.
To download the notebooks and learn more, check out our Solution Accelerator for Demand Forecasting.
An organization’s ability to deliver the right goods to the right place at the right time (and at the right price) is dependent upon its ability to predict demand. This makes demand forecasting an essential practice in most organizations.
A forecast is never expected to be perfectly accurate. There are always unknowns and factors we can’t account for. But historically, organizations have been forced to bend their data to work within the confines of available software packages and constrained computational capacity. This has led to an erosion of forecast accuracy with many organizations today operating from projections that are off as much as 30% or even more.
The consequences of this are dramatic. The linkage between forecasts and operations are such that a 10 to 20% increase in forecast accuracy generates a 5% reduction in inventory costs and a 2 to 3% increase in revenues. By leveraging inaccurate forecasts, these organizations are not only leaving money on the table, they are encouraging continued reliance on opinion and gut feel in the interpretation of forecast output which in study after study has been shown to inject bias into the process.
This ongoing reliance on forecast interpretation and intervention jeopardizes these organizations’ ability to bring forward the kinds of automated processes that are at the heart of most supply chain modernization efforts today. Organizations unable to modernize will soon find themselves struggling to deliver goods to their customers with the same speed, efficiency and flexibility of their competitors, putting them at a disadvantage in an increasingly crowded marketplace.
More and More Organizations Are Moving to Fine-Grained Forecasting
The way forward for most organizations is not a radical rethinking of their demand forecasting processes but instead a return to the original goal of predicting demand at the levels where it is being served using the most up to date information available. For different parts of the organization, this will mean slightly different things, but consistently we are seeing that it is driving various teams to implement forecasting at finer levels of granularity and to deliver predictions more frequently within increasingly narrow windows of time.
While this sounds challenging (and it was in years past!), advances in technology and the availability of the cloud make this much easier to deliver. Here at Databricks, we regularly encounter customers generating tens of millions of forecasts, often within a window of no more than an hour or two daily. Faster processing of the input data is essential, but the real trick is enlisting hundreds and sometimes thousands of virtual cores needed to rapidly train the models required by these processes.
In a pre-cloud world, the availability of such resources was dependent on the organization’s willingness to invest in a data center’s worth of servers, many of which would go idle outside the narrow windows within which forecasts needed to be generated. Few could justify the expense.
But the cloud changed that dynamic. Instead of owning the compute, it’s rented just for the minutes when needed. Leveraging Databricks, organizations can now rapidly allocate and just as quickly deallocate these resources around their demand forecasting cycles, making available the incredible amount of capacity needed to deliver the required results in a timely but still cost-effective manner.
Fine-Grained Forecasts Often Expose Intermittent Patterns of Demand
By removing the computational constraints on fine grained demand forecasting, organizations are now able to deliver predictions precisely at the levels where they operate. This has tremendous potential for the delivery of forecasts that capture the exact patterns of demand at a localized level. But quite often, this includes patterns of intermittent demand.
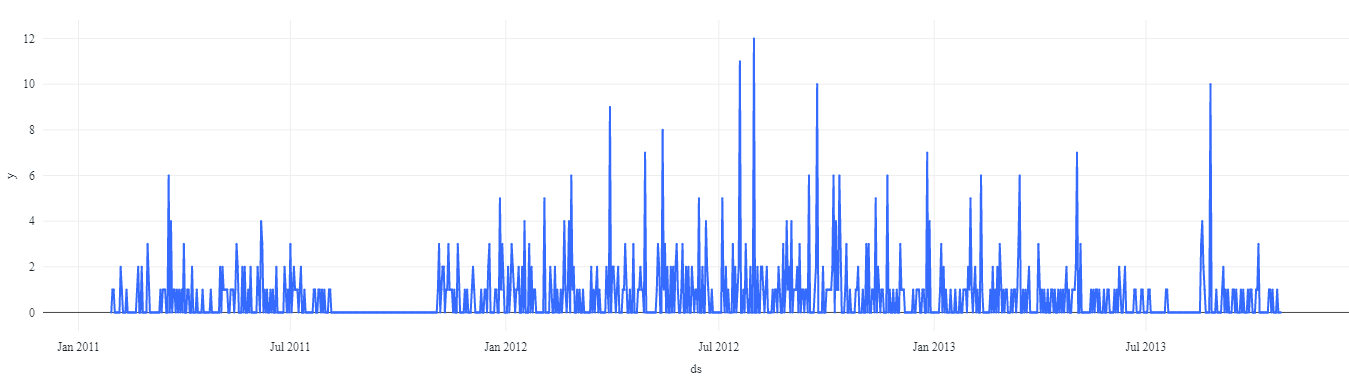
Simply put, not every product sells in every location every day. This issue is often masked in aggregate data, but when we move to finer levels of granularity, these localized periods of inactivity are frequently exposed.
What makes intermittent demand difficult is that quite often the factors that control whether a given unit sells on say today versus tomorrow cannot be captured in the data. Instead, we need to examine the rates at which units move over broader periods of time and focus on estimating the probability some number of those units will move on a particular date.
This is a very different approach to time series forecasting than is employed in the models most organizations have historically relied upon. Those models have focused on predicting the precise units expected to move on a given day, often by decomposing the data into elements that capture high-level trends as well as seasonal and cyclic patterns. These elements cannot often be effectively estimated in sparsely populated time series data, making these approaches and the software packages centered on them unusable at this level of granularity.
Intermittent Demand Needs to Be Modeled Using Specialized Techniques
Models for forecasting intermittent demand have been around since the 1970s. However, this space was often treated as an edge case as academics and practitioners focused their energies on the higher-level forecasts required for macro-level planning or dictated by the computational limitations of the time. As a result, access to these models have often been limited to a scattered set of one-off libraries and software packages that have largely escaped the vision of the broader forecasting community. Enter Nixtla.

Nixtla is a set of libraries intended to make available the widest set of forecasting capabilities in a consistent and easy-to-use manner. Built by practitioners frustrated with having to hunt down capabilities across disparate software packages, Nixtla emphasizes standardization and performance, allowing organizations to solve real-world forecasting challenges, including intermittent demand forecasting, with relative ease.
Recognizing that more and more organizations are attempting to generate large numbers of forecasts in a timely manner leveraging the cloud, Nixtla has incorporated a high-performance, automated scale-out engine, known as the Fugue engine, into their libraries. When coupled with Databricks, organizations can generate massive volumes for forecast output in a fast and cost-effective manner.
Demonstrating Intermittent Demand Forecasting with Nixtla and Databricks
To demonstrate the ability of Nixtla and Databricks to tackle intermittent demand forecasting at scale, we’ve written a set of notebooks to build forecasts for each of 30K+ store-item combinations presented as part of the M5 dataset, provided by Walmart. Each store-item in the dataset represents a time series with intermittent pattern of demand at a daily level, with 68% of the dates (on average) in each time series having no units sold.
In the notebooks, we demonstrate not only how to generate forecasts for each of these items using multiple techniques, but we show how organizations may automate a bake-off between model types to arrive at the best forecast for each store-item combination. We also introduce advanced techniques such as time series cross-validation to help organizations understand how they may employ more robust forecast evaluations at scale.
It’s our hope that this demonstration will help organizations explore new paths for the generation of demand forecasts that enable them to improve dependent supply chain processes and take their next leap forward in supply chain modernization.
To download the notebooks and learn more, check out our Solution Accelerator for Demand Forecasting.
Never miss a Databricks post
What's next?

Retail & Consumer Goods
September 20, 2023/11 min read
How Edmunds builds a blueprint for generative AI

Retail & Consumer Goods
September 9, 2024/6 min read