How Corning Built End-to-end ML on Databricks Lakehouse Platform

“This blog is authored by Denis Kamotsky, Principal Software Engineer at Corning”
Corning has been one of the world’s leading innovators in materials science for nearly 200 years. These innovations include the first glass bulbs for Thomas Edison’s electric light, the first low-loss optical fiber, the cellular substrates that enable catalytic converters, and the first damage-resistant cover glass for mobile devices. At Corning, as we continue to push boundaries, we use disruptive technologies like machine learning to deliver better products and drive efficiencies.
Driving better efficiency in our manufacturing process with machine learning
Delivering high-quality products is a key objective across our manufacturing facilities around the world, and we continue to explore how ML can help us deliver on that goal. This is true, for example, with our plant that produces Corning ceramics used in air filters and catalytic converters for both personal and commercial vehicles. While most steps in the manufacturing of these filters are robotized, some are still quite manual. Specifically for quality inspection, we take high-resolution images to look for irregularities in the cells, which can be predictive of leaks and defective parts. The challenge, however, is the prevalence of false positives due to the debris in the manufacturing environment showing up in pictures.
To address this, we manually brush and blow the filters before imaging. We discovered that by notifying operators of which specific parts to clean, we could significantly reduce the total time required for the process, and machine learning came in handy. We used ML to predict whether a filter is clean or dirty based on low-resolution images taken while the operator is setting up the filter inside the imaging device. Based on the prediction, the operator would get the signal to clean the part or not, thus reducing false positives on the final high-res images, helping us move faster through the production process and providing high-quality filters.
To execute this ML model, we needed a binary classifier for the low-resolution image. The key here is that it had to be a low-latency model since it’s interacting with the human operator on the factory floor, who would be frustrated or slowed down by long run times. When designing our model, we knew it would have to take only milliseconds to run.
Here’s a breakdown of how we did it
The data team
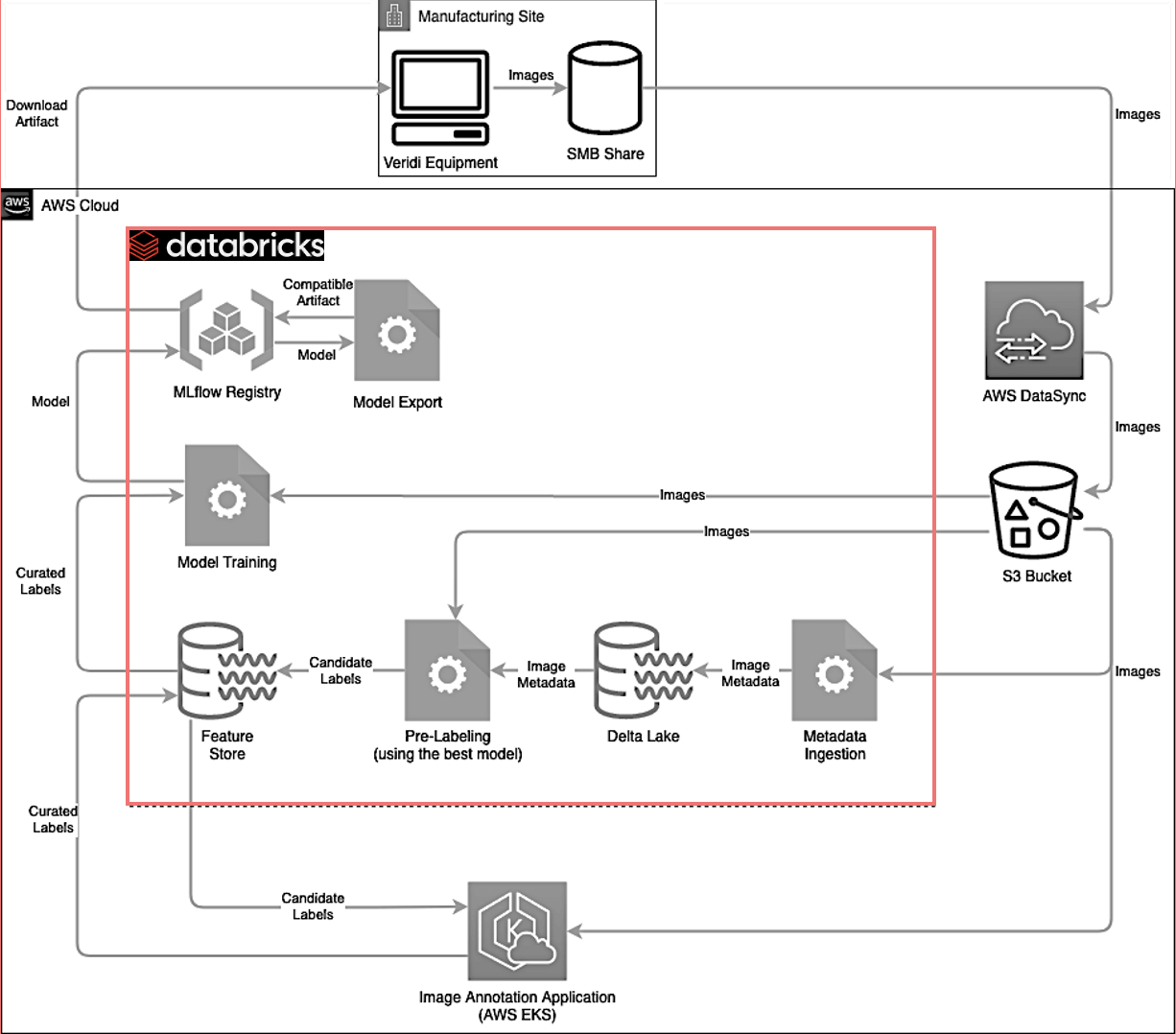
We started by building a cross-functional team to use Databricks to build a low-latency model with a deep learning approach. To enable our data scientists to experiment and build a model from scratch, we first collected thousands of images for them to use. We deployed a front-end app to help wrangle all this data and label these images, built data pipelines, and then trained the model at scale. And finally, once the model was trained, it needed to be deployed on the edge, across all Corning environmental technologies plants around the world.
Building the model
Databricks was central to our strategy and transformation, as it provides us with a simplified and unified platform, where we can centralize all of our data and ML work. We can train the model, register it in MLflow, generate all additional artifacts – like exported formats – and track them in the same place as the base model that we generate. Additionally, we use AWS data sync to collect images from Windows shares in our manufacturing facilities, which then land in an S3 bucket, depending on the project. Sometimes, if images require a lot of pre-processing, we convert or apply transformations to the images, and then store transformed images as binary columns in the Delta table itself. Using a lakehouse means that whether it's a bunch of files on S3, whether it's a column in a Delta table, it all looks the same to the code. So the programming model for accessing that data is the same regardless of the format.
Next, we kick off the model training as a Databricks job with the jobs API. The training produces the model, which we stored as a HDF5 file. The model is tracked by MLflow and registered in MLflow registry as the latest version. The next step is to run an evaluation of that model and compare the metrics we get with the best metrics from the model so far. These models can be tagged in MLflow to keep track of the best version of the model.
Deploying the model
Following the above steps, our expert logs in through the MLflow user interface and examines all the artifacts that were produced by the training job to generate the best model. Once they have made this evaluation, the experts move forward to take the most performant model to production, and the edge system can download that model using MLflow API from MLflow registry. This loop is great because it can be reused for supervising drift detection.
Our final deployed model has about 200,000 parameters, and it works great with over 90% accuracy.
Databricks for end-to-end ML
Databricks is a fantastic development environment for Python-centric data scientists and deep learning engineers and enables collaboration for end-to-end ML. It has environments that are pre-installed with the entire Python ecosystem from Scikit-learn, TensorFlow, and PyTorch. Clusters are very quick to provision and there is a great notebook environment. It’s easy to collaborate not only on the notebooks but also on the MLflow experiments across teams.
Another advantage of Databricks, that's not to be underestimated, is that it gives you individual computing environments for individual data scientists. Data scientists can provide themselves with a cluster of nodes. And the distributed nature of that cluster is managed through Spark, which is an open-source programming engine, enabling us to implement interesting solutions on top of it, providing flexibility and options beyond Java or Scala. All these parallel computing capabilities are very powerful, and by parallelizing your workload across multiple nodes, you can achieve high throughput. To get onboarded, Databricks offers deep dive classes through the Databricks Academy with lots of examples and notebooks.
Business Impact
Using machine learning on Databricks Lakehouse Platform, our business has experienced $2 Million in cost avoidance through manufacturing upset event reduction in the first year. It is deployed to all manufacturing facilities in Corning environmental technologies. Our project’s success also helped us earn our manufacturing Leadership Council award in 2022 for AI and machine learning in the industry, which we're very proud of.
You can watch the detailed video of this session from AWS re: Invent here:
AWS re:Invent 2022 - How Corning built E2E ML on a data lakehouse platform with Databricks (PRT321)
Never miss a Databricks post
What's next?

Technology
December 9, 2024/6 min read
Scale Faster with Data + AI: Insights from the Databricks Unicorns Index

News
December 11, 2024/4 min read