Distributed Data Governance and Isolated Environments with Unity Catalog
by Max Nienu, Zeashan Pappa, Paul Roome and Sachin Thakur
Effective data governance is essential for any organization that relies on data, analytics and AI for its operations. In many organizations, there is a growing recognition of the value proposition of centralized data governance. However, even with the best intentions, implementing centralized governance can be challenging without the proper organizational processes and resources. The role of Chief Data Officer (CDO) is still emerging in many organizations, leaving questions about who will define and execute data governance policies across the organization.
As a result, the responsibility for defining and executing data governance policies across the organization is often not centralized, leading to policy variations or governing bodies across lines of business, sub-units, and other divisions within an organization. For simplicity, we can call this pattern distributed governance, where there is a general agreement on the distinctions between these governing units but not necessarily a central data governance function.
In this blog, we'll explore implementing a distributed governance model using Databricks Unity Catalog, which provides a unified governance solution for data, analytics, and AI in the lakehouse.
Evolution of Data Governance in Databricks
Before the introduction of Unity Catalog, the concept of a workspace was monolithic, with each workspace having its own metastore, user management, and Table ACL store. This led to intrinsic data and governance isolation boundaries between workspaces and duplication of effort to address consistency across them.
To handle this, some customers resorted to running pipelines or code to synchronize their metastores and ACLs, while others set up their own self-managed metastores to use across workspaces. However, these solutions added more overhead and maintenance costs forcing upfront architecture decisions on how to partition data across the organization, creating data silos.
Data Governance with Unity Catalog
To overcome these limitations, Databricks developed Unity Catalog, which aims to make it easy to implement data governance while maximizing the ability to collaborate on and share data. The first step in achieving this was implementing a common namespace that permits access to any data within an organization.
This approach may seem like a challenge to the distributed governance pattern mentioned earlier but Unity Catalog offers new isolation mechanisms within the namespace that organizations have traditionally addressed using multiple Hive metastores. These isolation mechanisms enable groups to operate independently with minimal or no interaction and also allow them to achieve isolation in other scenarios, such as production vs development environments.
Hive Metastore versus Unity Catalog in Databricks
With Hive, a metastore was a service boundary, meaning that having different metastores meant different hosted underlying Hive services and different underlying databases. Unity Catalog is a platform service within the Databricks Lakehouse Platform, so there are no service boundaries to consider.
Unity Catalog provides a common namespace that allows you to govern and audit your data in one place.
When using Hive, it was common to use multiple metastores, each with its own namespace, to achieve isolation between development and production environments, or to allow for the separation of data between operating units.
In Unity Catalog, these requirements are solved through dynamic isolation mechanisms on namespaces that don't compromise the ability to share and collaborate on data and don't require hard one-way upfront architecture decisions.
Working across different teams and environments
When using a data platform, there is often a strong need to have isolation boundaries between environments like dev/prod and between business groups, teams, or operating units of your organization.
Let's begin by defining isolation boundaries in a data platform such as Databricks:
- Users should only gain access to data based on agreed access rules
- Data can be managed by designated people or teams
- Data should be physically separated in storage
- Data should only be accessed in designated environments
Users should only gain access to data based on agreed access rules
Organizations usually have strict requirements around data access based on some organizational/regulatory requirements which is fundamental to keeping data secure. Typical examples include employee salary information or credit card payment information.
Access to this type of information is typically tightly controlled and audited periodically. Unity Catalog provides organizations granular control over data assets within the catalog to meet these industry standards. With the controls, Unity Catalog provides users will only see and query the data they are entitled to see and query.
Data can be managed by designated people or teams
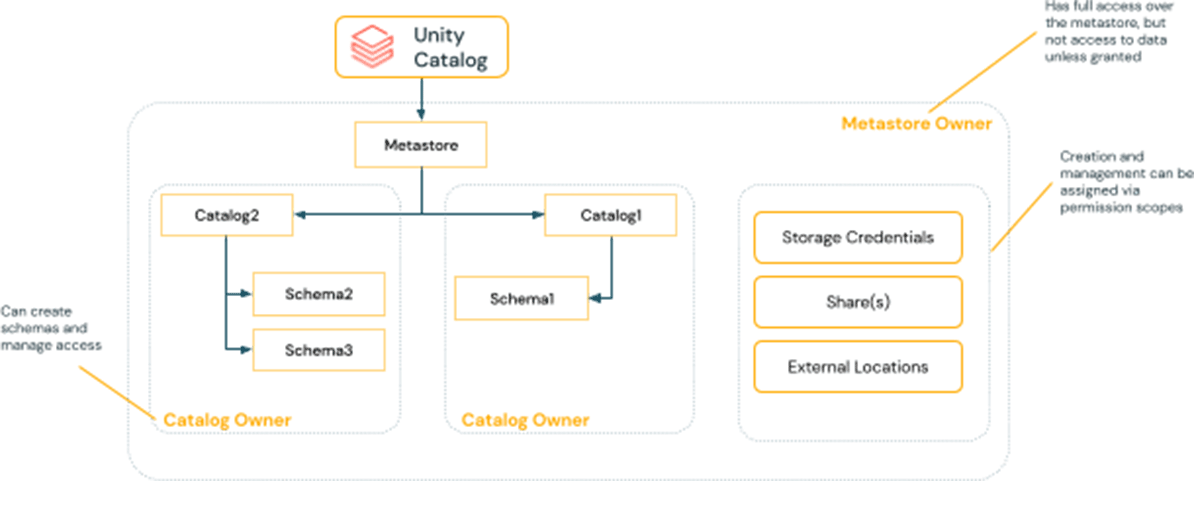
Unity Catalog gives you the ability to choose from centralized governance or distributed governance models.
In the centralized governance model, your governance administrators are owners of the metastore and can take ownership of any object and set ACLs and policy.
In a distributed governance model, you would consider a catalog or set of catalogs to be a data domain. The owner of that catalog can create and own all assets and manage governance within that domain. Therefore the owners of domains can operate independently of other owners in other domains.
We strongly recommend setting a group to be the owner or service principal for both of these options if management is done through tooling.
Data should be physically separated in storage
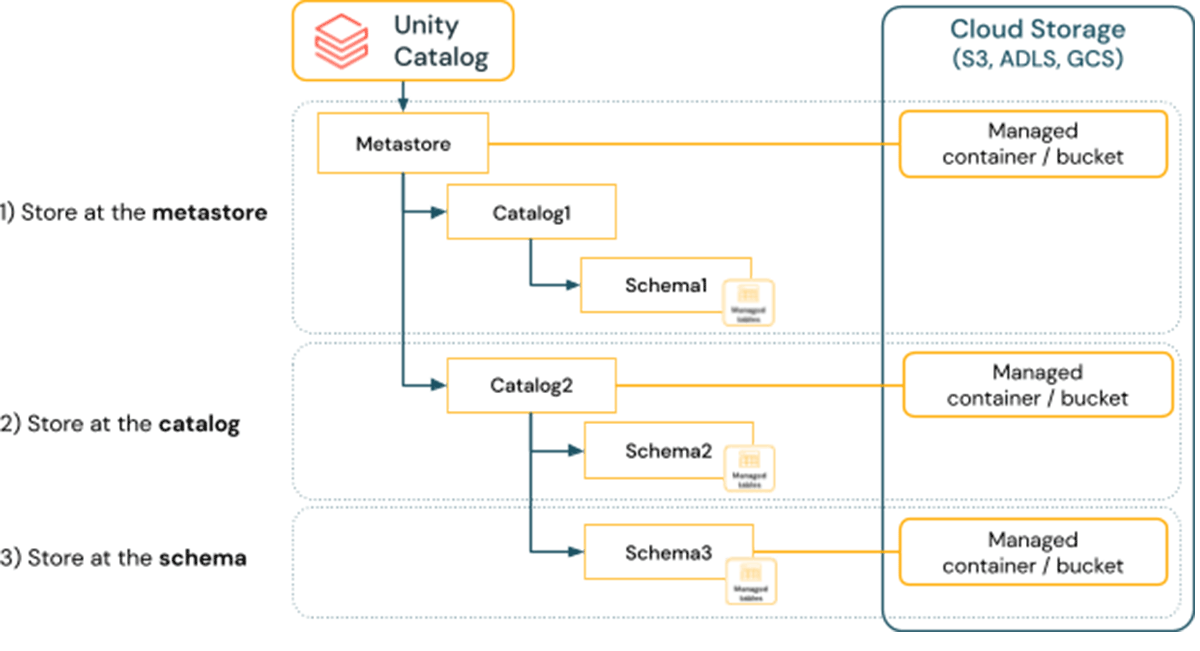
By default, when creating a UC metastore, the Databricks Account Admin provides a single cloud storage location and credential as the default location for managed tables.
Organizations that require physical isolation of data, for regulatory reasons, or for example across SDLC scopes, between business units, or even for cost allocation purposes, should consider managed data source features at the catalog and schema level.
Unity Catalog allows you to choose the defaults for how data is separated in storage. By default, all data is stored at the metastore. With feature support for managed data sources on catalogs and schemas, you can physically isolate data storage and access, helping your organization achieve their governance and data management requirements.
When creating managed tables, the data will then be stored using the schema location (if present) followed by the catalog location (if present), and will only use the metastore location if the prior two locations have not been set.
Data should only be accessed in designated environments, based on the purpose of that data
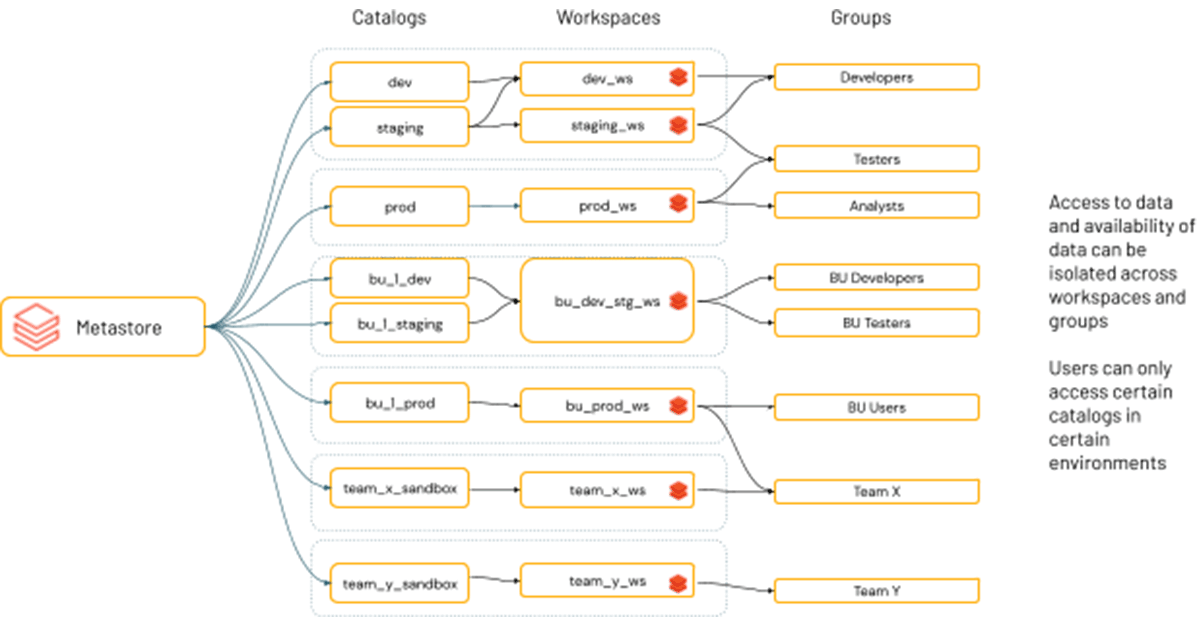
Oftentimes, organizational and compliance requirements maintain that you need to keep certain data accessible only in certain environments versus others. An example of this could be dev and production, or HIPAA or PII environments that contain PII data for analysis and have special access rules around who can access the data and the environments that allow access to that data. Sometimes requirements dictate that certain data sets or domains cannot be crossed or combined together.
In Databricks, we consider a workspace to be an environment. Unity Catalog has a feature that allows you to 'bind' catalogs to workspace. These environment-aware ACLs give you the ability to ensure that only certain catalogs are available within a workspace, regardless of a user's individual ACLs. This means that the metastore admin, or the catalog owner can define the workspaces that a data catalog can be accessed from. This can be controlled via our UI or via API/terraform for easy integrations. We even recently published a blog on how to control Unity Catalog via terraform to help fit your specific governance model.
Conclusion
With Unity Catalog at the center of your lakehouse architecture, you can achieve a flexible and scalable governance implementation without sacrificing your ability to manage and share data effectively. With Unity Catalog, you can overcome the limitations and constraints of your existing Hive metastore, enabling you to more easily isolate and collaborate on data according to your specific business needs. Follow the Unity Catalog guides (AWS, Azure) to get started. Download this free ebook on Data, analytics and AI governance to learn more about best practices to build an effective governance strategy for your data lakehouse.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.