Best Practices for LLM Evaluation of RAG Applications
A Case Study on the Databricks Documentation Bot

Published: September 12, 2023
by Quinn Leng, Kasey Uhlenhuth and Alkis Polyzotis
Chatbots are the most widely adopted use case for leveraging the powerful chat and reasoning capabilities of large language models (LLM). The retrieval augmented generation (RAG) architecture is quickly becoming the industry standard for developing chatbots because it combines the benefits of a knowledge base (via a vector store) and generative models (e.g. GPT-3.5 and GPT-4) to reduce hallucinations, maintain up-to-date information, and leverage domain-specific knowledge. However, evaluating the quality of chatbot responses remains an unsolved problem today. With no industry standards defined, organizations resort to human grading (labeling) –which is time-consuming and hard to scale.
We applied theory to practice to help form best practices for LLM automated evaluation so you can deploy RAG applications to production quickly and with confidence. This blog represents the first in a series of investigations we’re running at Databricks to provide learnings on LLM evaluation. All research in this post was conducted by Quinn Leng, Senior Software Engineer at Databricks and creator of the Databricks Documentation AI Assistant.
Challenges with auto-evaluation in practice
Recently, the LLM community has been exploring the use of “LLMs as a judge” for automated evaluation with many using powerful LLMs such as GPT-4 to do the evaluation for their LLM outputs. The lmsys group’s research paper explores the feasibility and pros/cons of using various LLMs (GPT-4, ClaudeV1, GPT-3.5) as the judge for tasks in writing, math, and world knowledge.
Despite all this great research, there are still many unanswered questions about how to apply LLM judges in practice:
- Alignment with Human Grading: Specifically for a document-Q&A chatbot, how well does an LLM judge’s grading reflect the actual human preference in terms of correctness, readability and comprehensiveness of the answers?
- Accuracy through Examples: What’s the effectiveness of providing a few grading examples to the LLM judge and how much does it increase the reliability and reusability of the LLM judge on different metrics?
- Appropriate Grade Scales: What grading scale is recommended because different grading scales are used by different frameworks (e.g., AzureML uses 0 to 100 whereas langchain uses binary scales)?
- Applicability Across Use Cases: With the same evaluation metric (e.g. correctness), to what extent can the evaluation metric be reused across different use cases (e.g. casual chat, content summarization, retrieval-augmented generation)?
Applying effective auto-evaluation for RAG applications
We explored the possible options for the questions outlined above in the context of our own chatbot application at Databricks. We believe that our findings generalize and can thus help your team effectively evaluate RAG-based chatbots at a lower cost and faster speed:
- LLM-as-a-judge agrees with human grading on over 80% of judgments. Using LLMs-as-a-judge for our document-based chatbot evaluation was as effective as human judges, matching the exact score in over 80% of judgments and being within a 1-score distance (using a scale of 0-3) in over 95% of judgments.
- Save costs by using GPT-3.5 with examples. GPT-3.5 can be used as an LLM judge if you provide examples for each grading score. Because of the context size limit it’s only practical to use a low-precision grading scale. Using GPT-3.5 with examples instead of GPT-4 drives down the cost of LLM judge by 10x and improves the speed by more than 3x.
- Use low-precision grading scales for easier interpretation. We found lower-precision grading scores like 0, 1, 2, 3 or even binary (0, 1) can largely retain precision compared to higher precision scales like 0 to 10.0 or 0 to 100.0, while making it considerably easier to provide grading rubrics to both human annotators and LLM judges. Using a lower precision scale also allows consistency of grading scales among different LLM judges (e.g. between GPT-4 and claude2).
- RAG applications require their own benchmarks. A model might have good performance on a published specialized benchmark (e.g. casual chat, math, or creative writing) but that doesn’t guarantee good performance on other tasks (e.g. answering questions from a given context). Benchmarks should only be used if the use case matches, i.e., a RAG application should only be evaluated with a RAG benchmark.
Based on our research, we recommend the following procedure when using an LLM judge:
- Use a 1-5 grading scale
- Use GPT-4 as an LLM judge with no examples to understand grading rules
- Switch your LLM judge to GPT-3.5 with one example per score
Our methodology for establishing the best practices
The remainder of this post will walk through the series of experiments we conducted to form these best practices.
Experiment Setup
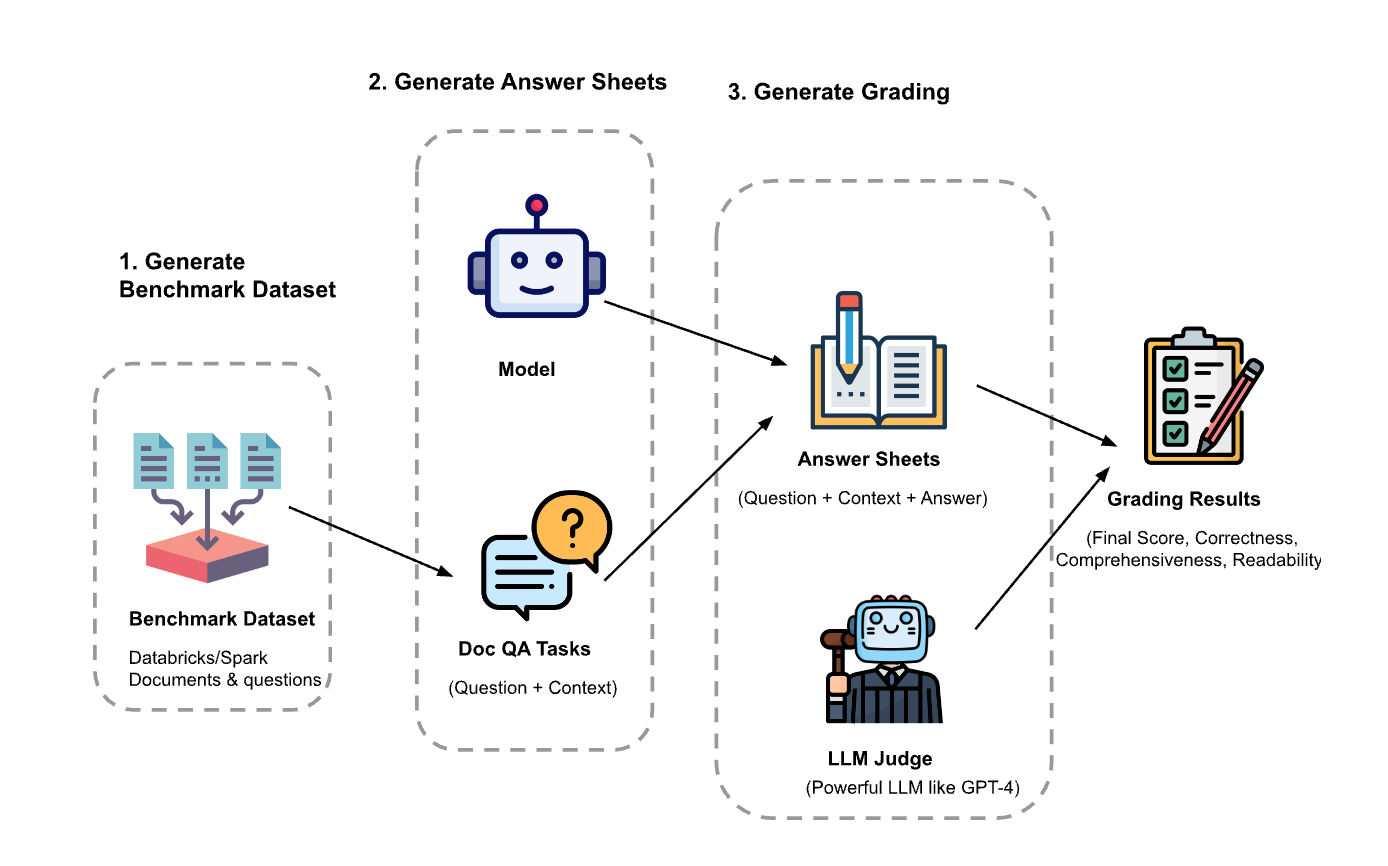
The experiment had three steps:
- Generate evaluation dataset: We created a dataset from 100 questions and context from Databricks documents. The context represents (chunks of) documents that are relevant to the question.

- Generate answer sheets: Using the evaluation dataset, we prompted different language models to generate answers and stored the question-context-answer pairs in a dataset called “answer sheets”. In this investigation, we used GPT-4, GPT-3.5, Claude-v1, Llama2-70b-chat, Vicuna-33b, and mpt-30b-chat.
- Generate grades: Given the answer sheets, we used various LLMs to generate grades and reasoning for the grades. The grades are a composite score of Correctness (weighted: 60%), Comprehensiveness (weighted: 20%) and Readability (weighted: 20%). We chose this weighting scheme to reflect our preference for Correctness in the generated answers. Other applications may tune these weights differently but we expect Correctness to remain a dominant factor.
Additionally, the following techniques were used to avoid positional bias and improve reliability:
- Low temperature (temperature 0.1) to ensure reproducibility.
- Single-answer grading instead of pairwise comparison.
- Chain of thoughts to let the LLM reason about the grading process before giving the final score.
- Few-shots generation where the LLM is provided with several examples in the grading rubric for each score value on each factor (Correctness, Comprehensiveness, Readability).
Experiment 1: Alignment with Human Grading
To confirm the level of agreement between human annotators and LLM judges, we sent answer sheets (grading scale 0-3) from gpt-3.5-turbo and vicuna-33b to a labeling company to collect human labels, and then compared the result with GPT-4’s grading output. Below are the findings:
- Human and GPT-4 judges can reach above 80% agreement on the correctness and readability score. And if we lower the requirement to be smaller or equal than 1 score difference, the agreement level can reach above 95%.
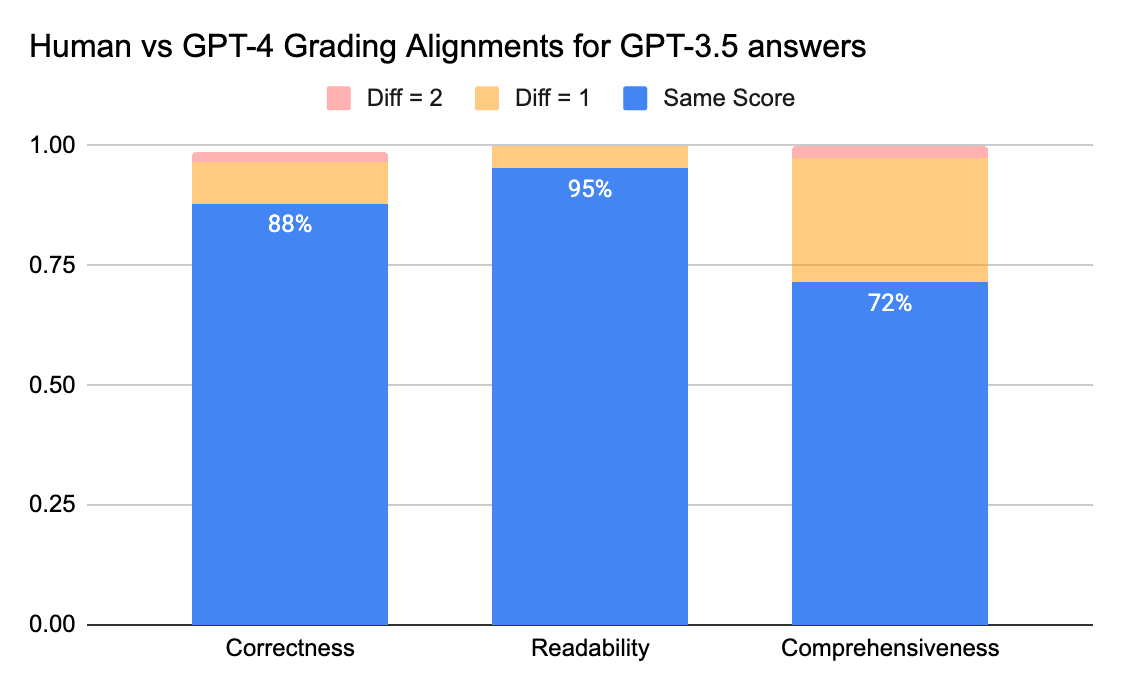
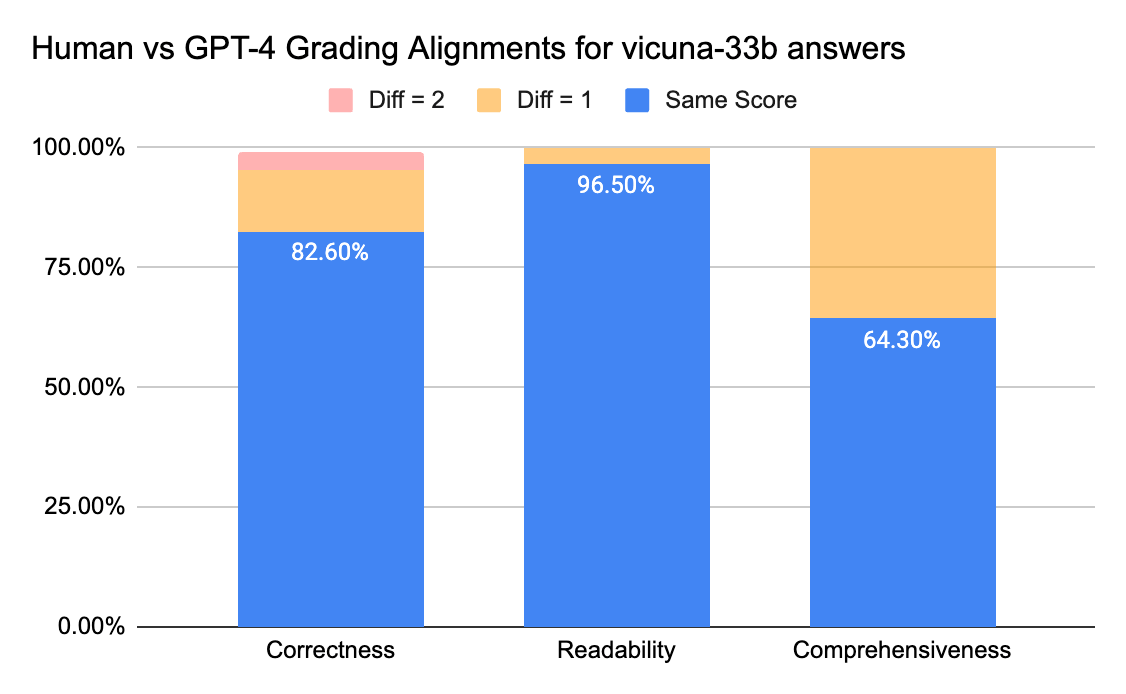
The Comprehensiveness metric has less alignment, which matches what we’ve heard from business stakeholders who shared that “comprehensive” seems more subjective than metrics like Correctness or Readability.
Experiment 2: Accuracy through Examples
The lmsys paper uses this prompt to instruct the LLM judge to evaluate based on the helpfulness, relevance, accuracy, depth, creativity, and level of detail of the response. However, the paper doesn’t share specifics on the grading rubric. From our research, we found many factors can significantly affect the final score, for example:
- The importance of different factors: Helpfulness, Relevance, Accuracy, Depth, Creativity
- The interpretation of factors like Helpfulness is ambiguous
- If different factors conflict with each other, where an answer is helpful but is not accurate
We developed a rubric for instructing an LLM judge for a given grading scale, by trying the following:
- Original Prompt: Below is the original prompt used in the lmsys paper:
|
|
We adapted the original lmsys paper prompt to emit our metrics about correctness, comprehensiveness and readability, and also prompt the judge to provide one line justification before giving each score (to benefit from chain-of-thought reasoning). Below are the zero-shot version of the prompt which doesn’t provide any example, and the few-shot version of the prompt which provides one example for each score. Then we used the same answer sheets as input and compared the graded results from the two prompt types.
- Zero Shot Learning: require the LLM judge to emit our metrics about correctness, comprehensiveness and readability, and also prompt the judge to provide one line justification for each score.
|
|
- Few Shots Learning: We adapted the zero shot prompt to provide explicit examples for each score in the scale. The new prompt:
|
|
From this experiment, we learned several things:
- Using the Few Shots prompt with GPT-4 didn’t make an obvious difference in the consistency of results. When we included the detailed grading rubric with examples we didn’t see a noticeable improvement in GPT-4’s grading results across different LLM models. Interestingly, it caused a slight variance in the range of the scores.
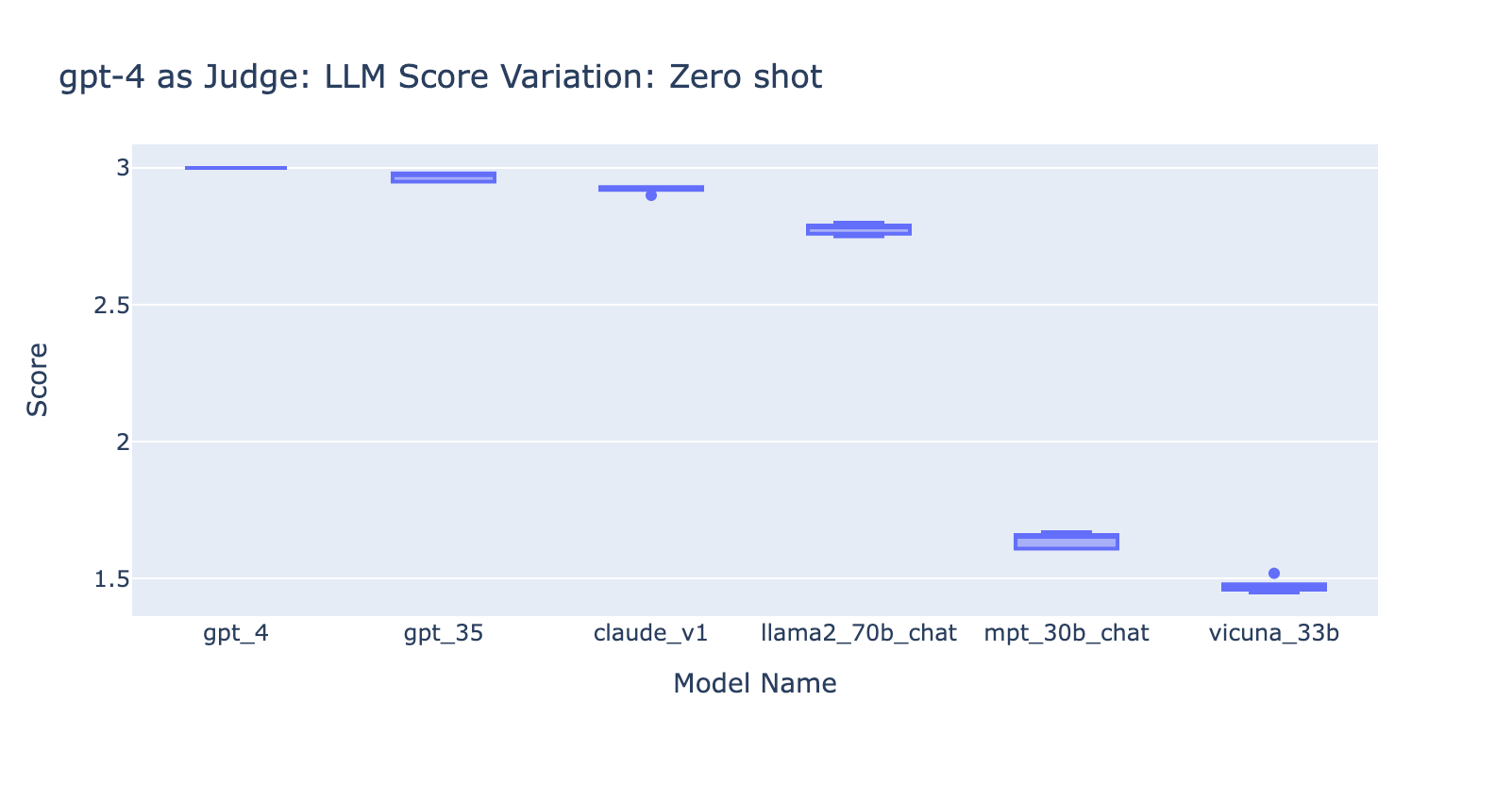
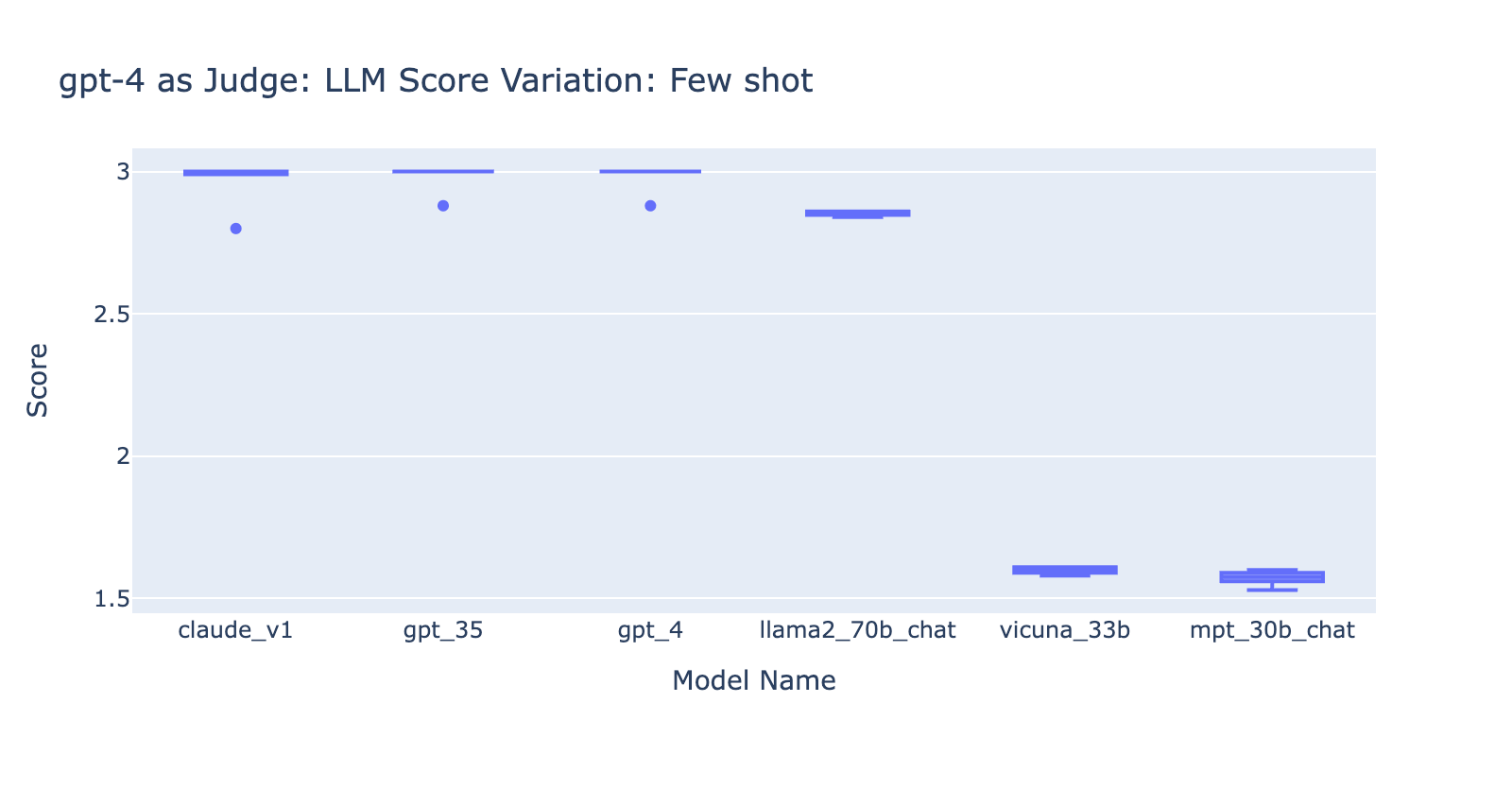
- Including few examples for GPT-3.5-turbo-16k significantly improves the consistency of the scores, and makes the result usable. Including detailed grading rubric/examples has very obvious improvement on the grading result from GPT-3.5 (chart on the right side) Though the actual average score value is slightly different between GPT-4 and GPT-3.5 (score 3.0 vs score 2.6), the ranking and precision remains fairly consistent
- On the contrary, (screenshot on the left) using GPT-3.5 without a grading rubric gets very inconsistent results and is completely unusable
- Note that we are using GPT-3.5-turbo-16k instead of GPT-3.5-turbo since the prompt can be larger than 4k tokens.
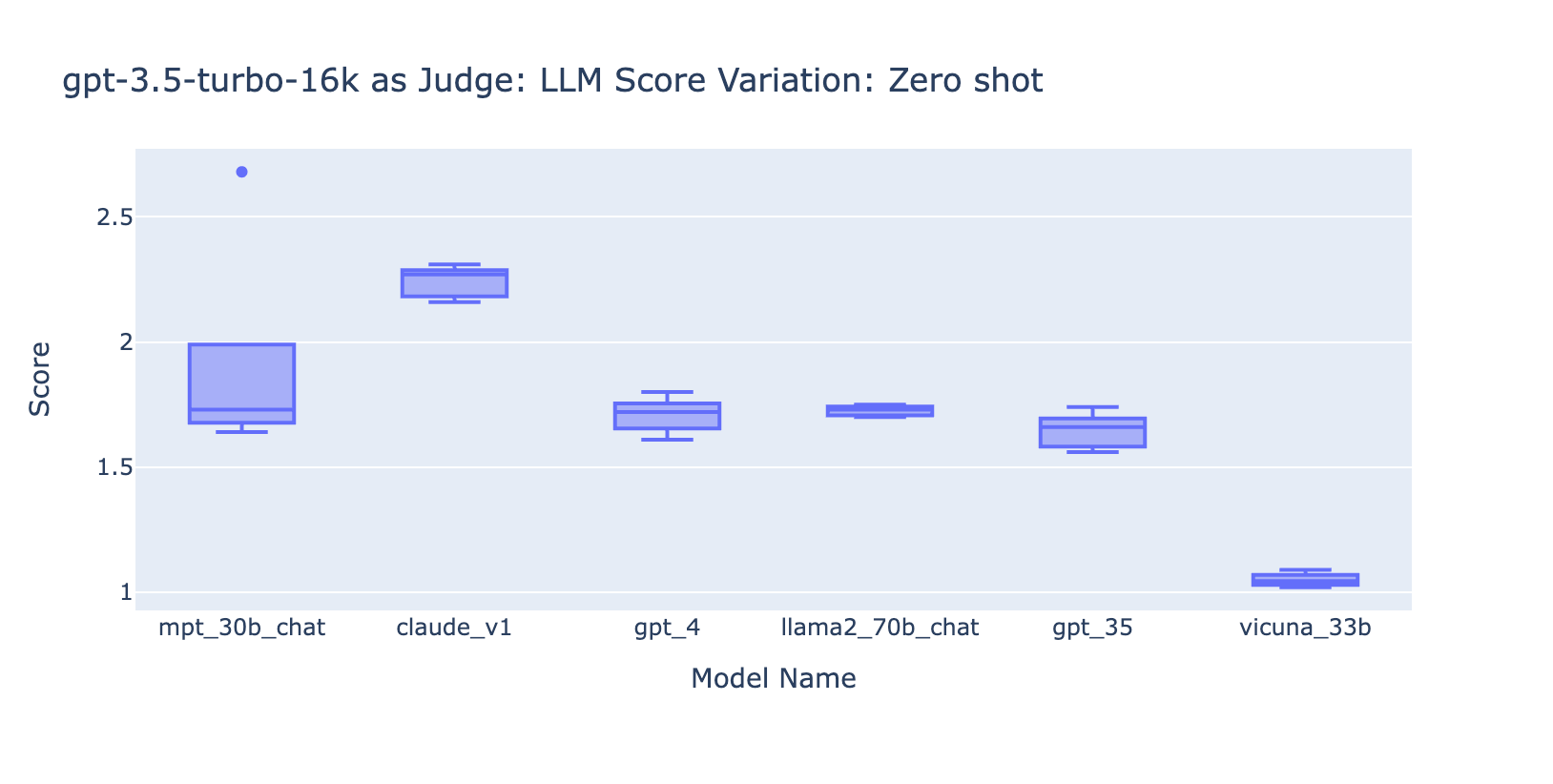
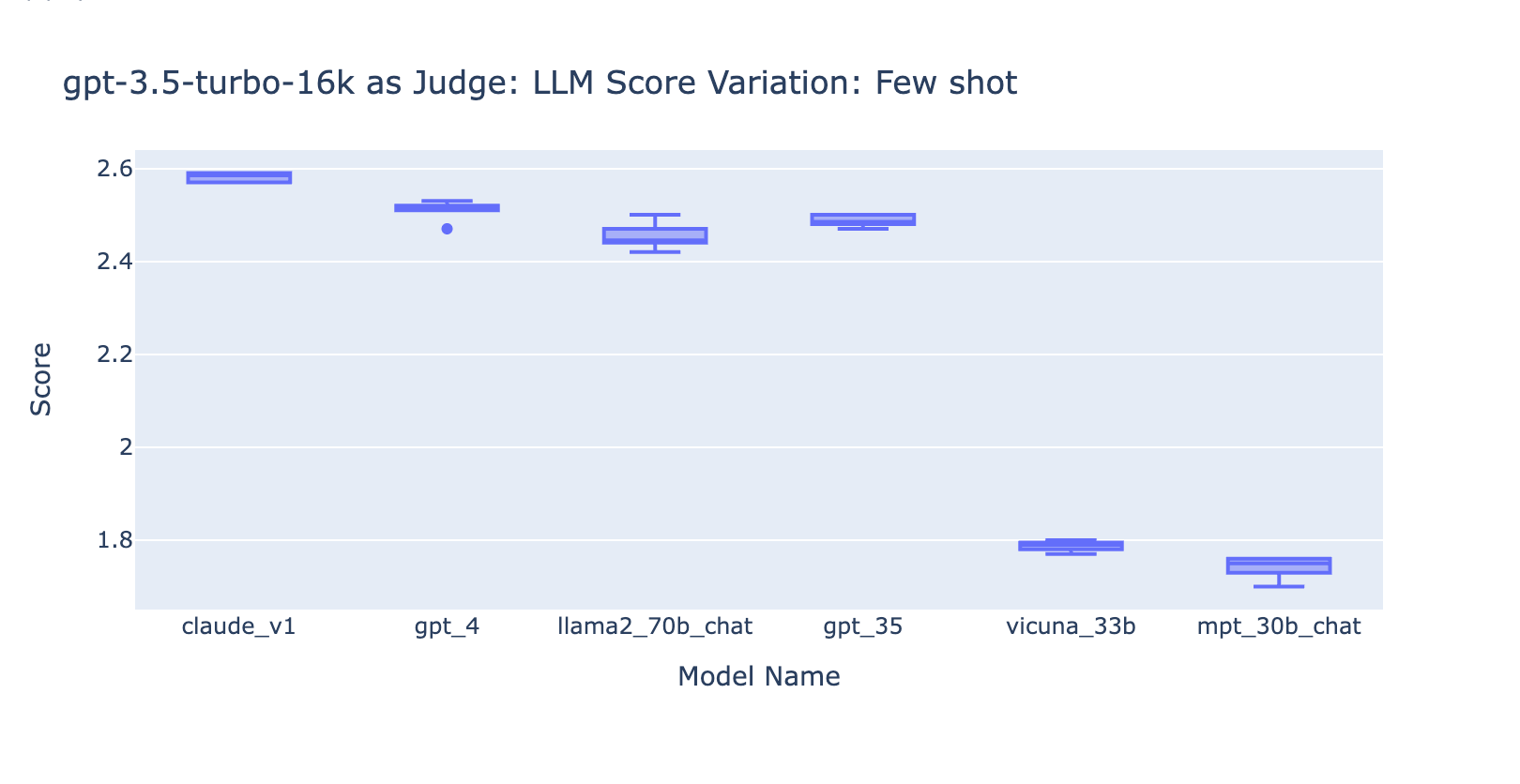
Experiment 3: Appropriate Grade Scales
The LLM-as-judge paper uses a non-integer 0~10 scale (i.e. float) for the grading scale; in other words, it uses a high precision rubric for the final score. We found these high-precision scales cause issues downstream with the following:
- Consistency: Evaluators–both human and LLM–struggled to hold the same standard for the same score when grading on high precision. As a result, we found that output scores are less consistent across judges if you move from low-precision to high-precision scales.
- Explainability: Additionally, if we want to cross-validate the LLM-judged results with human-judged results we must provide instructions on how to grade answers. It is very difficult to provide accurate instructions for each “score” in a high-precision grading scale–for example, what’s a good example for an answer that’s scored at 5.1 as compared to 5.6?
We experimented with various low-precision grading scales to provide guidance on the “best” one to use, ultimately we recommend an integer scale of 0-3 or 0-4 (if you want to stick to the Likert scale). We tried 0-10, 1-5, 0-3, and 0-1 and learned:
- Binary grading works for simple metrics like “usability” or “good/bad”.
- Scales like 0-10 are difficult to come up with distinguishing criteria between all scores.
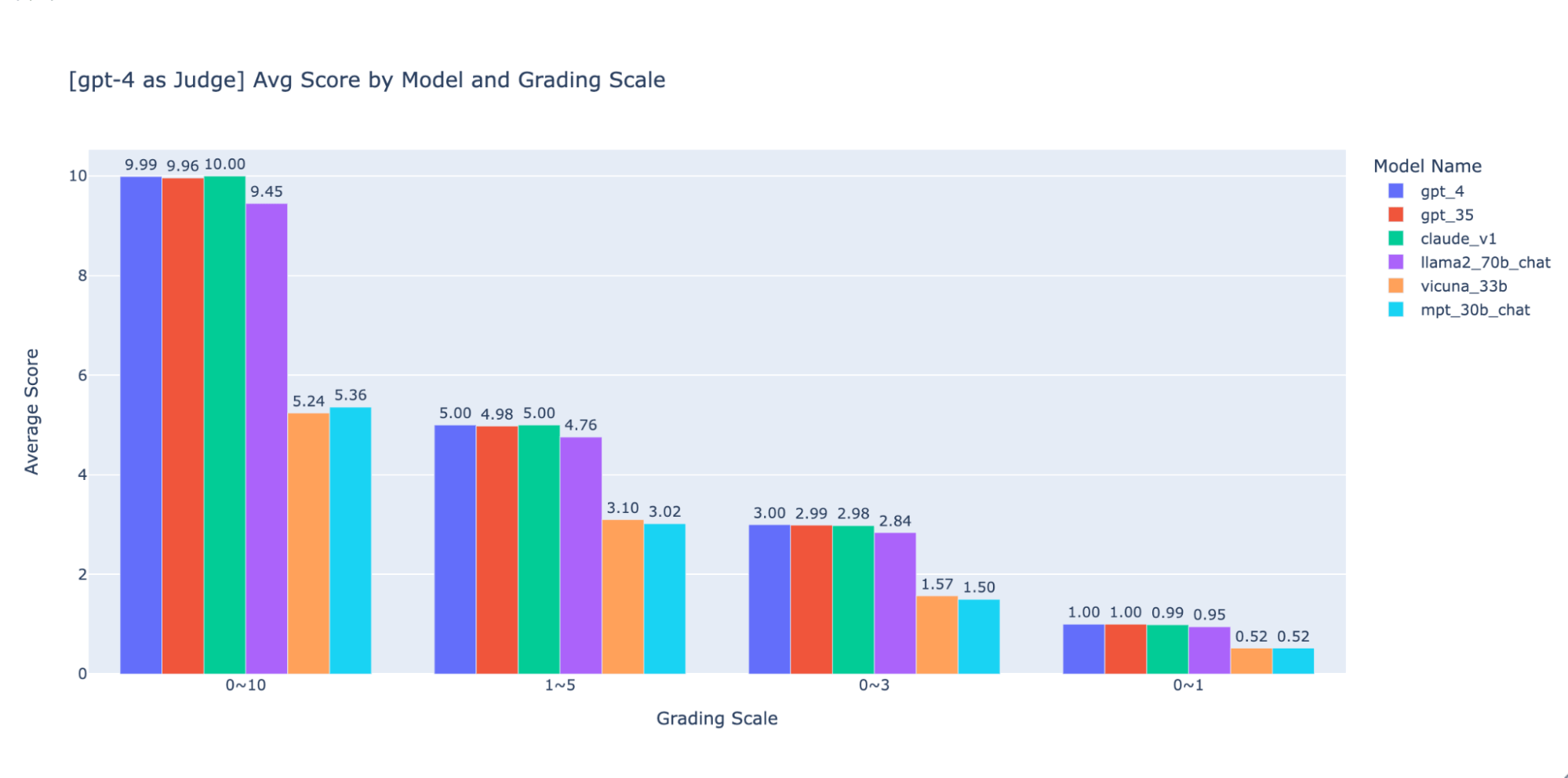
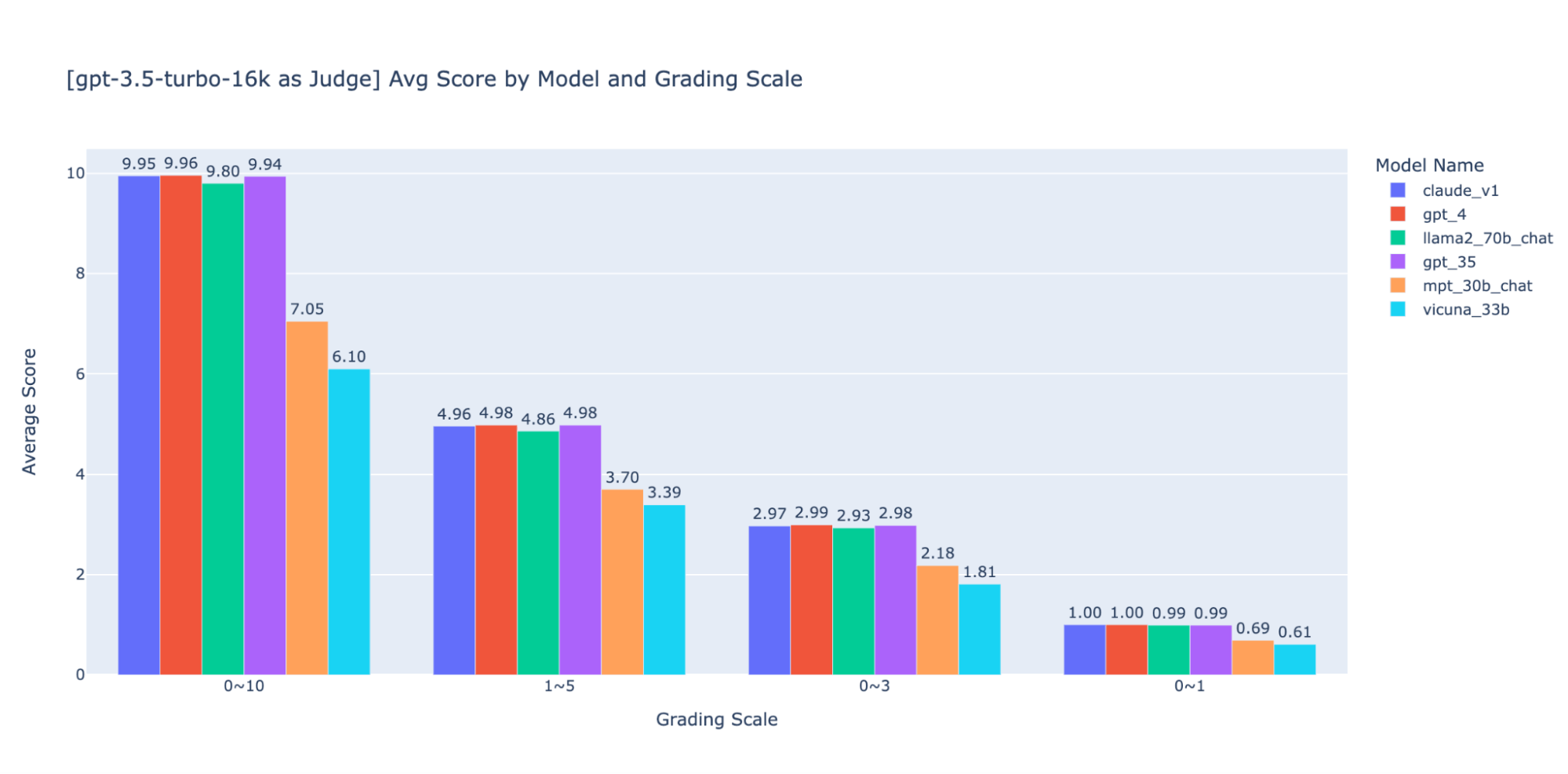
As shown in the plots above, both GPT-4 and GPT-3.5 can retain consistent ranking of results using different low-precision grading scales, thus using a lower grading scale like 0~3 or 1~5 can balance the precision with explainability)
Thus we recommend 0-3 or 1-5 as a grading scale to make it easier to align with human labels, reason about scoring criteria, and provide examples for each score in the range.
Experiment 4: Applicability Across Use Cases
The LLM-as-judge paper shows that both LLM and human judgment ranks the Vicuna-13B model as a close competitor to GPT-3.5:
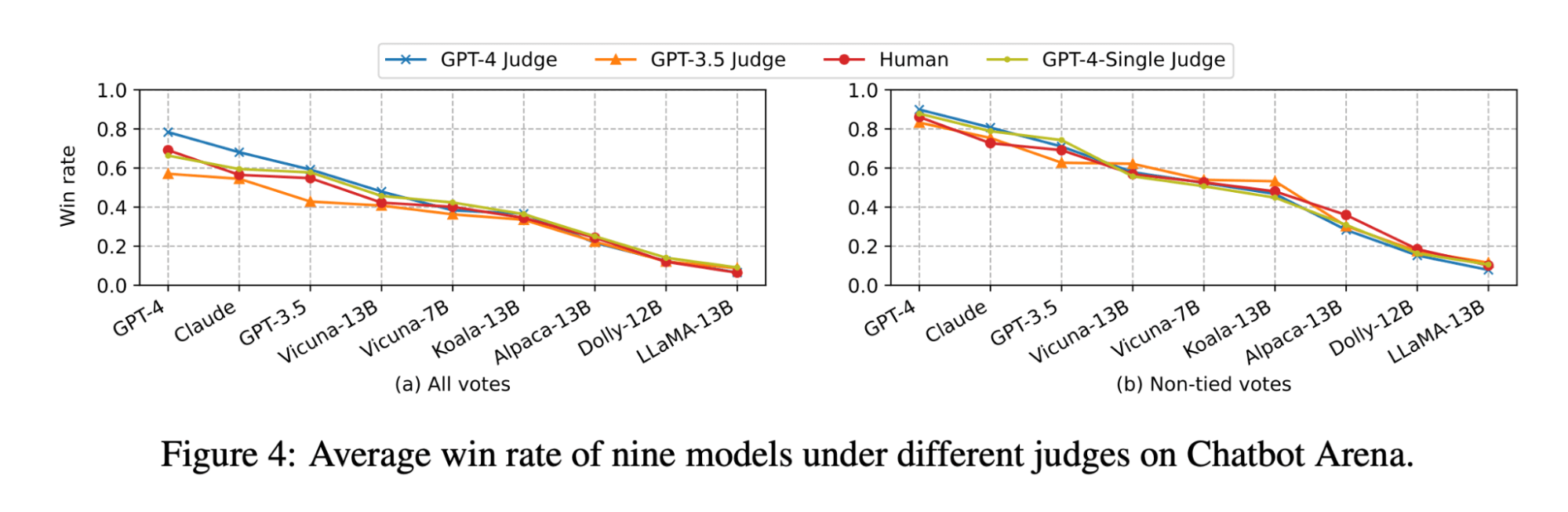
(The figure is coming from Figure 4 of the LLM-as-judge paper: https://arxiv.org/pdf/2306.05685.pdf )
However, when we benchmarked the set of models for our document Q&A use cases, we found that even the much larger Vicuna-33B model has a noticeably worse performance than GPT-3.5 when answering questions based on context. These findings are also verified by GPT-4, GPT-3.5 and human judges (as mentioned in Experiment 1) which all agree that Vicuna-33B is performing worse than GPT-3.5.
We looked closer at the benchmark dataset proposed by the paper and found that the 3 categories of tasks (writing, math, knowledge) don’t directly reflect or contribute to the model’s ability to synthesize an answer based on a context. Instead, intuitively, document Q&A use cases need benchmarks on reading comprehension and instruction following. Thus evaluation results can’t be transferred between use cases and we need to build use-case-specific benchmarks in order to properly evaluate how good a model can meet customer needs.
Use MLflow to leverage our best practices
With the experiments above, we explored how different factors can significantly affect the evaluation of a chatbot and confirmed that LLM as a judge can largely reflect human preferences for the document Q&A use case. At Databricks, we are evolving the MLflow Evaluation API to help your team effectively evaluate your LLM applications based on these findings. MLflow 2.4 introduced the Evaluation API for LLMs to compare various models’ text output side-by-side, MLflow 2.6 introduced LLM-based metrics for evaluation like toxicity and perplexity, and we’re working to support LLM-as-a-judge in the near future!
In the meantime, we compiled the list of resources we referenced in our research below:
- Doc_qa repository
- The code and data we used to conduct the experiments
- LLM-as-Judge Research paper from lmsys group
- The paper is the first research for using LLM as judge for the casual chat use cases, it extensively explored the feasibility and pros and cons of using LLM (GPT-4, ClaudeV1, GPT-3.5) as the judge for tasks in writing, math, world knowledge
Never miss a Databricks post
What's next?


Product
December 10, 2024/7 min read