Accelerated DBRX Inference on Databricks Model Serving
Introduction
In this blog post we dive into inference with DBRX, the open state-of-the-art large language model (LLM) created by Databricks (see Introducing DBRX). We discuss how DBRX was designed from the ground up for both efficient inference and advanced model quality, we summarize how we achieved cutting-edge performance on our platform, and end with some practical tips on how to interact with the model.
Databricks Model Serving provides instant access to DBRX Instruct on a high-performance, production-grade, enterprise-ready platform. Users can instantly experiment and build prototype applications, then smoothly transition to our production-grade inference platform.
Try DBRX now!
- AI Playground in your Databricks workspace (US only)
- With the OpenAI SDK: Getting started querying LLMs on Databricks
- Public demo: huggingface.co/spaces/databricks/dbrx-instruct
We've seen tremendous demand for DBRX Instruct. Hundreds of enterprises have begun to explore the model's capabilities on the Databricks platform.
Databricks is a key partner to Nasdaq on some of our most important data systems. They continue to be at the forefront of industry in managing data and leveraging AI, and we are excited about the release of DBRX. The combination of strong model performance and favorable serving economics is the kind of innovation we are looking for as we grow our use of Generative AI at Nasdaq. — Mike O'Rourke, Head of AI and Data Services, NASDAQ
To support the ML community, we also open sourced the model architecture and weights, and contributed optimized inference code to leading open source projects like vLLM and TRT-LLM.
DBRX-Instruct's integration has been a phenomenal addition to our suite of AI models and highlights our commitment to supporting open-source. It's delivering fast, high-quality answers to our users' diverse questions. Though it's still brand new on You.com, we're already seeing the excitement among users and look forward to its expanded use. — Saahil Jain, Senior Engineering Manager, You.com
At Databricks, we are focused on building a Data Intelligence Platform: an intelligence engine infused with generative AI, built on top of our unified data lakehouse. A powerful instantly-available LLM like DBRX Instruct is a critical building block for this. Additionally, DBRX's open weights empowers our customers to further train and adapt DBRX to extend its understanding to the unique nuances of their target domain and their proprietary data.
DBRX Instruct is an especially capable model for applications that are important to our enterprise customers (code generation, SQL, and RAG). In retrieval augmented generation (RAG), content relevant to a prompt is retrieved from a database and presented alongside the prompt to give the model more information than it would otherwise have. To excel at this, a model must not only support long inputs (DBRX was trained with up to 32K token inputs) but it must also be able to find relevant information buried deep in its inputs (see the Lost in the Middle paper).
On long-context and RAG benchmarks, DBRX Instruct performs better than GPT-3.5 Turbo and leading open LLMs. Table 1 highlights the quality of DBRX Instruct on two RAG benchmarks - Natural Questions and HotPotQA - when the model is also provided with the top 10 passages retrieved from a corpus of Wikipedia articles.
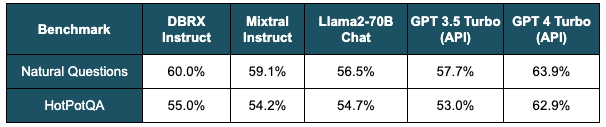
Table 1. RAG benchmarks. The performance of various models measured when each model is given the top 10 passages retrieved from a Wikipedia corpus using bge-large-en-v1.5. Accuracy is measured by matching within the model's answer. DBRX Instruct has the highest score other than GPT-4 Turbo.
An Inherently Efficient Architecture
DBRX is a Mixture-of-Experts (MoE) decoder-only, transformer model. It has 132 billion total parameters, but only uses 36 billion active parameters per token during inference. See our previous blog post for details on how it was trained.
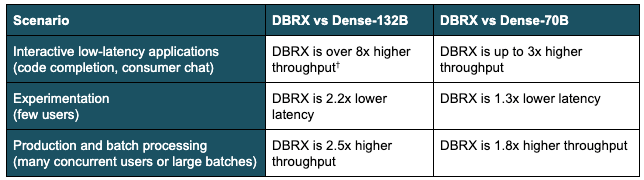
Table 2: MoE inference efficiency in various scenarios. The table summarizes the advantage an MoE like DBRX has over a comparably sized dense model and over the popular dense 70B model form factor († max output tokens per sec @ time per output token target < 30 ms). This summary is based on a variety of benchmarks on H100 servers with 8-way tensor parallelism and 16-bit precision. Figures 1 and 2 show some underlying details.
We chose the MoE architecture over a dense model not only because MoEs are more efficient to train, but also due to the serving time benefits. Improving models is a challenging task: we would like to scale parameter counts—which our research has shown to predictably and reliably improve model capabilities—without compromising model usability and speed. MoEs allow parameter counts to be scaled without proportionally large increases in training and serving costs.
DBRX's sparsity bakes inference efficiency into the architecture: instead of activating all the parameters, only 4 out of the total 16 "experts" per layer are activated per input token. The performance impact of this sparsity depends on the batch size, as shown in figures 1 and 2. As we discussed in an earlier blog post, both Model Bandwidth Utilization (MBU) and Model Flops Utilization (MFU) determine how far we can push inference speed on a given hardware setup.
First, at low batch sizes, DBRX has less than 0.4x the request latency of a comparably-sized dense model. In this regime the model is memory–bandwidth bound on high end GPUs like NVIDIA H100s. Simply put, modern GPUs have tensor cores that can perform trillions of floating point operations per second, so the serving engine is bottlenecked by how fast memory can provide data to the compute units. When DBRX processes a single request, it does not have to load all 132 billion parameters; it only ends up loading 36 billion parameters. Figure 1 highlights DBRX's advantage at small batch sizes, an advantage which narrows but remains large at larger batch sizes.
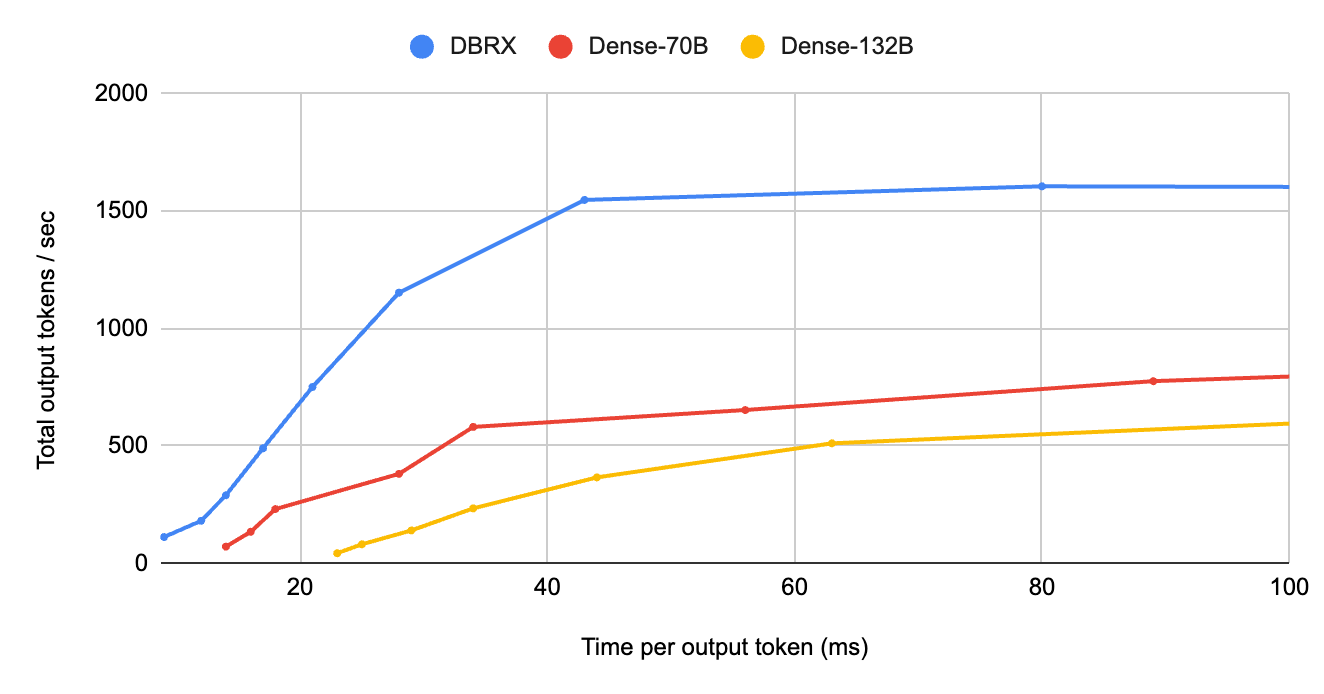
Figure 1: MoEs are substantially better for interactive applications. Many applications need to generate responses within a strict time budget. Comparing an MoE like DBRX to dense models, we see that DBRX is able to generate over 8x as many total tokens per second if the target is below 30 ms per output token. This means model servers can handle an order of magnitude more concurrent requests without compromising individual user experience. These benchmarks were run on H100 servers using 16-bit precision and 8-way tensor parallelism with optimized inference implementations for each model.
Second, for workloads that are compute bound—that is, bottlenecked by the speed of the GPU—the MoE architecture significantly reduces the total number of computations that need to occur. This means that as concurrent requests or input prompt lengths increase, MoE models scale significantly better than their dense counterparts. In these regimes, DBRX can increase decode throughput up to 2.5x relative to a comparable dense model, as highlighted in figure 2. Users performing Retrieval Augmented Generation (RAG) workloads will see an especially large benefit, since these workloads typically pack several thousand tokens into the input prompt. As do workloads using DBRX to process many documents with Spark and other batch pipelines.
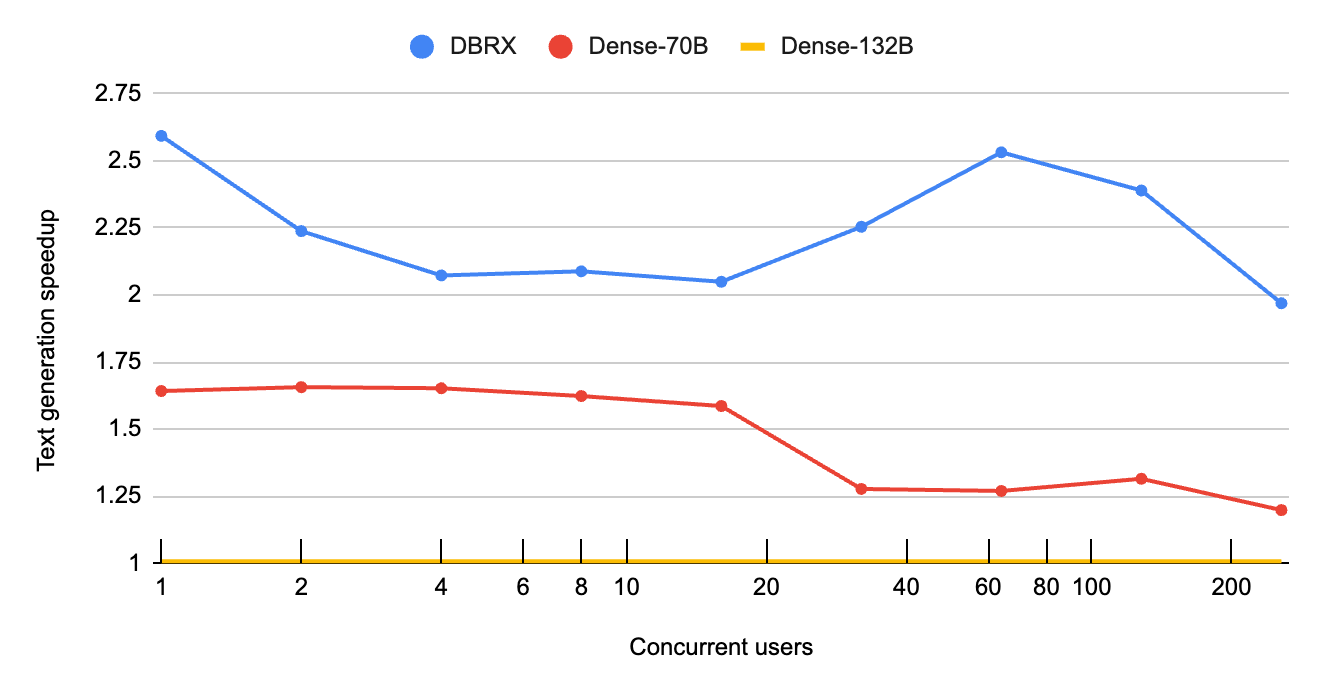
Figure 2: MoE's have superior scaling. Comparing an MoE like DBRX to dense models, we see that its text generation rate* scales much better at large batch sizes (* total output tokens per second). DBRX consistently has 2x or higher throughput compared to a similarly sized dense model (Dense-132B). DBRX's speedup accelerates at large batch sizes: above 32 concurrent users DBRX reaches 2x the speed of a leading dense 70B model. These benchmarks used the same setup as those in figure 1.
Fine-Grained Mixture-of-Experts
DBRX is a fine-grained MoE, meaning it uses a larger number of smaller experts. DBRX has 16 experts and chooses 4, while Mixtral and Grok-1 have 8 experts and choose 2. This provides 65x more possible combinations of experts and we found that this improves model quality.
Additionally, DBRX is a relatively shallow and wide model so its inference performance scales better with tensor parallelism. DBRX and Mixtral-8x22B have roughly the same number of parameters (132B for DBRX vs 140B for Mixtral) but Mixtral has 1.4x as many layers (40 vs 56). Compared to Llama2, a dense model, DBRX has half the number of layers (40 vs 80). More layers tends to result in more expensive cross-GPU calls when running inference on multiple GPUs (a requirement for models this large). DBRX's relative shallowness is one reason it has a higher throughput at medium batch sizes (4 - 16) compared to Llama2-70B (see Figure 1).
To maintain high quality with many small experts, DBRX uses "dropless" MoE routing, a technique pioneered by our open-source training library MegaBlocks (see Bringing MegaBlocks to Databricks). MegaBlocks has also been used to develop other leading MoE models such as Mixtral.
Previous MoE frameworks (Figure 3) forced a tradeoff between model quality and hardware efficiency. Experts had a fixed capacity so users had to choose between occasionally dropping tokens (lower quality) or wasting computation due to padding (lower hardware efficiency). In contrast (Figure 4), MegaBlocks (paper) reformulated the MoE computation using block-sparse operations so that expert capacity could be dynamically sized and efficiently computed on modern GPU kernels.

Figure 3: A traditional Mixture-of-Experts (MoE) layer. A router produces a mapping of input tokens to experts and produces probabilities that reflect the confidence of the assignments. Tokens are sent to their top_k experts (in DBRX top_k is 4). Experts have fixed input capacities and if the dynamically routed tokens exceed this capacity, some tokens are dropped (see top red area). Conversely, if fewer tokens are routed to an expert, computation capacity is wasted with padding (see bottom red area).
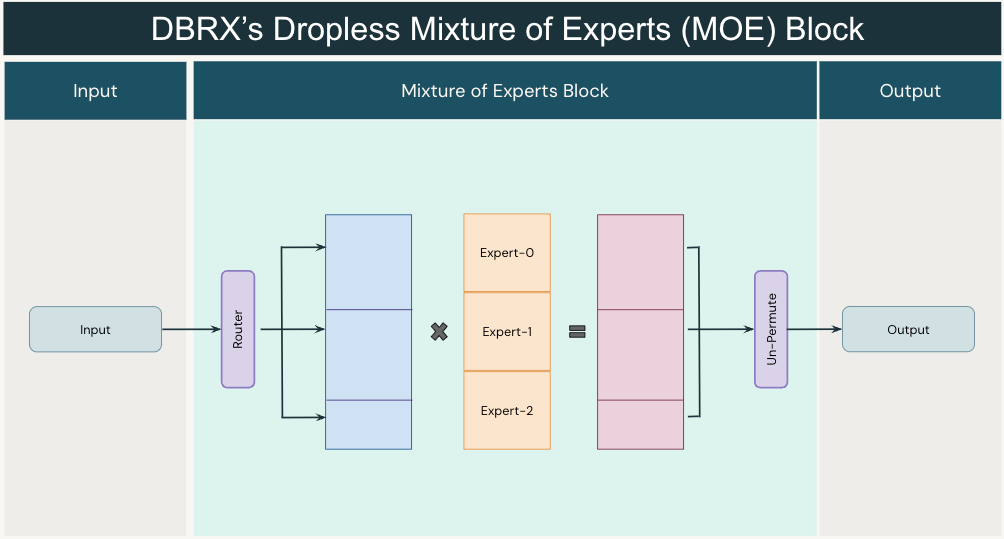
Figure 4: A dropless MoE layer. The router works as before, routing each token to its top_k experts. However we now use variable sized blocks and efficient matrix multiplications to avoid dropping tokens or wasting capacity. MegaBlocks proposes using block-sparse matrix multiplications. In practice, we use optimized GroupGEMM kernels for inference.
Engineered for Performance
As explained in the previous section, inference with the DBRX architecture has innate advantages. Nonetheless, achieving state-of-the-art inference performance requires a substantial amount of careful engineering.
Figure 5: DBRX in the Databricks AI Playground. Foundation Model APIs users can expect to see text generation speeds of up to ~150 tokens per second for DBRX.
We have made deep investments in our high-performance LLM inference stack and have implemented new DBRX-focused optimizations. We have applied many optimizations such as fused kernels, GroupGEMMs for MoE layers, and quantization for DBRX.
Optimized for enterprise use cases. We have optimized our server to support workloads with lots of traffic at high throughput, without degrading latency below acceptable levels—especially for the long context requests that DBRX excels on. As discussed in a previous blog post, building performant inference services is a challenging problem; lots of care must be put into memory management and performance tuning to maintain high availability and low latency. We utilize an aggregated continuous batching system to process several requests in parallel, maintaining high GPU utilization and providing strong streaming performance.
Deep multi-GPU optimizations. We have implemented several custom techniques inspired by state-of-the-art serving engines such as NVIDIA's TensorRT-LLM and vLLM. This includes custom kernels implementing operator fusions to eliminate unnecessary GPU memory reads/writes as well as carefully tuned tensor parallelism and synchronization strategies. We explored different forms of parallelism strategies such as tensor parallel and expert parallel and identified their comparative advantages.
Quantization and quality. Quantization – a technique for making models smaller and faster – is especially important for models the size of DBRX. The main barrier to deploying DBRX is its memory requirements: at 16-bit precision, we recommend a minimum of 4x80GB NVIDIA GPUs. Being able to serve DBRX in 8-bit precision halves its serving costs and frees it to run on lower-end GPUs such as NVIDIA A10Gs. Hardware flexibility is particularly important for enterprise users who care about geo-restricted serving in regions where the availability of high-end GPUs is scarce. However, as we discussed in our previous blog post, great care must be taken when incorporating quantization. In our rigorous quality evals, we found that the default INT8 quantization methods in TRT-LLM and vLLM lead to model quality degradation in certain generative tasks. Some of this degradation is not apparent in benchmarks like MMLU where the models are not generating long sequences. The biggest quality problems we have seen were flagged by domain-specific (e.g., HumanEval) and long-context (e.g., ZeroSCROLLS) benchmarks. As a user of Databricks' inference products, you can trust that our engineering team carefully ensures the quality of our models even as we make them faster.
In the past, we have released many blogs on our engineering practices for fast and secure inference serving. For more details, please see our previous blog posts linked below:
- Fast, Secure and Reliable: Enterprise-grade LLM Inference
- Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs
- LLM Inference Performance Engineering: Best Practices
Figure 6: Folks on X really like DBRX token generation speed (tweet). Our Hugging Face Space demo uses Databricks Foundation Model APIs as its backend.
Inference Tips and Tricks
In this section we share some strategies for constructing good prompts. Prompt details are especially important for system prompts.
DBRX Instruct provides high performance with simple prompts. However, like other LLMs, well-crafted prompts can significantly enhance its performance and align its outputs with your specific needs. Remember that these models use randomness: the same prompt evaluated multiple times can result in different outputs.
We encourage experimentation to find what works best for each of your use-cases. Prompt engineering is an iterative process. The starting point is often a "vibe check" – manually assessing response quality with a few example inputs. For complex applications, it's best to follow this by constructing an empirical evaluation framework and then iteratively evaluating different prompting strategies.
Databricks provides an easy-to-use UI to aid this process, in AI Playground and with MLflow. We also provide mechanisms to run these evaluations at scale, such as Inference Tables and data analysis workflows.
System Prompts
System prompts are a way to transform the generic DBRX Instruct model into a task-specific model. These prompts establish a framework for how the model should respond and can provide additional context for the conversation. They are also often used to assign a role to modulate the model's response style ("you are a kindergarten teacher").
DBRX Instruct's default system prompt turns the model into a general purpose enterprise chatbot with basic safety guardrails. This behavior won't be a good fit for every customer. The system prompt can be changed easily in the AI Playground or using the "system" role in chat API requests.
When a custom system prompt is provided, it completely overrides our default system prompt. Here is an example system prompt which uses few-shot prompting to turn DBRX Instruct into a PII detector.
Prompting Tips
Here are a few tips to get you started prompting DBRX Instruct.
First steps. Start with the simplest prompts you can, to avoid unnecessary complexity. Explain what you want in a straightforward manner, but provide adequate detail and relevant context for the task. These models cannot read your mind. Think of them as an intelligent-yet-inexperienced intern.
Use precise instructions. Instruction-following models like DBRX Instruct tend to give the best results with precise instructions. Use active commands (“classify”, “summarize”, etc) and explicit constraints (e.g. “do not” instead of “avoid”). Use precise language (e.g. to specify the desired length of the response use “explain in about 3 sentences” rather than “explain in a few sentences”). Example: “Explain what makes the sky blue to a five year old in 50 or fewer words” instead of “Explain briefly and in simple terms why the sky is blue.”
Teach by example. Sometimes, rather than crafting detailed general instructions, the best approach is to provide the model with a few examples of inputs and outputs. The sample system prompt above uses this technique.This is referred to as "few-shot" prompting. Examples can ground the model in a particular response format and steer it towards the intended solution space. Examples should be diverse and provide good coverage. Examples of incorrect responses with information about why they were wrong can be very helpful. Typically at least 3-5 examples are needed.
Encourage step-by-step problem solving. For complex tasks, encouraging DBRX Instruct to proceed incrementally towards a solution often works better than having it generate an answer immediately. In addition to improving answer accuracy, step-by-step responses provide transparency and make it easier to analyze the model’s reasoning failures. There are a few techniques in this area. A task can be decomposed into a sequence of simpler sub-tasks (or recursively as a tree of simpler and simpler sub-tasks). These sub-tasks can be combined into a single prompt, or prompts can be chained together, passing the model’s response to one as the input to the next. Alternatively, we can ask DBRX Instruct to provide a “chain of thought” before its answer. This can lead to higher quality answers by giving the model “time to think” and encouraging systematic problem solving. Chain-of-thought example: “I baked 15 muffins. I ate 2 muffins and gave 5 muffins to a neighbor. My partner then bought 6 more muffins and ate 2. Do I have a prime number of muffins? Think step by step.”
Formatting matters. Like other LLMs, prompt formatting is important for DBRX Instruct. Instructions should be placed at the start. For structured prompts (few-shot, step-by-step, etc) if you use delimiters to mark section boundaries (markdown style ## headers, XML tags, triple quotation marks, etc), use a consistent delimiter style throughout the conversation.
If you are interested in learning more about prompt engineering, there are many resources readily available online. Each model has idiosyncrasies, DBRX Instruct is no exception. There are, however, many general approaches that work across models. Collections such as Anthropic's prompt library can be a good source of inspiration.
Generation Parameters
In addition to prompts, inference request parameters impact how DBRX Instruct generates text.
Generating text is a stochastic process: the same prompt evaluated multiple times can result in different outputs. The temperature parameter can be adjusted to control the degree of randomness. temperature is a number that ranges from 0 to 1. Choose lower numbers for tasks that have well-defined answers (such as question answering and RAG) and higher numbers for tasks that benefit from creativity (writing poems, brainstorming). Setting this too high will result in nonsensical responses.
Foundation Model APIs also support advanced parameters, such as enable_safety_mode (in private preview). This enables guardrails on the model responses, detecting and filtering unsafe content. Soon, we'll be introducing even more features to unlock advanced use cases and give customers more control of their production AI applications.
Querying the Model
You can begin experimenting immediately if you are a Databricks customer via our AI Playground. If you prefer using an SDK, our Foundation Model APIs endpoints are compatible with the OpenAI SDK (you will need a Databricks personal access token).
Conclusions
DBRX Instruct is another significant stride in our mission to democratize data and AI for every enterprise. We released the DBRX model weights and also contributed performance-optimized inference support to two leading inference platforms: TensorRT-LLM and vLLM. We have worked closely with NVIDIA during the development of DBRX to push the performance of TensorRT-LLM for MoE models as a whole. With vLLM, we have been humbled by the overarching community support and appetite for DBRX.
While foundation models like DBRX Instruct are the central pillars in GenAI systems, we are increasingly seeing Databricks customers construct compound AI systems as they move beyond flashy demos to develop high quality GenAI applications. The Databricks platform is built for models and other components to work in concert. For example, we serve RAG Studio chains (built on top of MLflow) that seamlessly connect Vector Search to the Foundation Model APIs. Inference Tables allow secure logging, visualization, and metrics tracking, facilitating the collection of proprietary data sets which can then be used to train or adapt open models like DBRX to drive continuous application improvement.
As an industry we are at the start of the GenAI journey. At Databricks we are excited to see what you build with us! If you aren't a Databricks customer yet, sign up for a free trial!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.